看着似乎用jenkins基于ansible发布spring boot/cloud类的jar包程序,或者tomcat下的war包的需求挺多的,闲来无事,也说说自己做过的jenkins基于ansible的发布方法。
规范与标准
无规矩不成方圆,要做好后期的自动化,标准化是少不了的,下面是我们这边规划的一些标准(非强制,根据自己实际情况调整)
- 应用名称:
{应用类型}-{端口}-{应用名称}or{类型}-{应用名称}, 例如:web-8080-gateway,app-jobs-platform - 主机名称:
{地区}-{机房}-{应用类型}-{代码语言}-{项目分组}-{ip结尾}, 例如:sz-rjy-service-java-foo-14-81 - 日志路径:
/log/web,例如:/log/web/web-8080-gateway - 应用路径:
/data/,例如:/data/web-8080-gateway
不难看出,这里应用名称前缀使用的是主机名称的第三个字段(看起来挺麻烦的,不过没办法,谁让公司是这么规定的呢 )
)
环境配置
1). 软件版本描述
- Ansible: 2.7.1
- Python: 2.7.5
- CentOS: 7.2
- Java: 1.8.0_73
- Jenkins: 2.121.1
2).环境/软件安装
略...自己玩去
Ansible Role
1).目录结构
- playbooks/deploy.yml # 入口文件
- roles/deploy
- ├── defaults
- │ └── main.yml # 默认参数
- ├── tasks
- │ ├── backup.yml # 备份应用
- │ ├── common.yml
- │ ├── gray_deploy.yml # 发布应用
- │ ├── main.yml # 主配置
- └── templates
- ├── service.sh.j2 # 服务管理模板
- └── systemd.service.j2 # systemd模板
2).role配置
playbooks/deploy.yml(入口文件)
- ---
- - hosts: "{{ TARGET }}"
- remote_user: "{{ REMOTE_USER }}"
- any_errors_fatal: true
- roles:
- - deploy
defaults/main.yml
- ---
- # defaults file for deploy
- # 获取项目名称,JOB_NAME来自jenkins内建参数,可见下文jenkins配置页说明
- PROJECT: "{{ JOB_NAME.split('_')[-1] }}"
- # 项目路径
- PROJECT_DIR: "/data"
- # JAVA参数配置项,JAVA_OPTIONS来自jenkins参数化构建,可见下文jenkins配置页说明
- JAVA_OPTS: "{{ JAVA_OPTIONS | default('-Xmx256m -Xms256m') }}"
- # systemd配置路径
- SYSTEMD_PATH: "/etc/systemd/system"
- # 应用日志路径
- LOGPATH: "/log/web"
- # 备份目录
- BACKUP: "/data/backup/{{ PROJECT }}"
- # jdk version
- # 配和include_role: jdk使用
- jdk:
- version: "{{ version | default('1.8.0_73') }}"
tasks/main.yml(主配置)
- ---
- # 本想引用jdk的role做到预配置jdk环境,但是become下遇到了些bug,如果是秘钥或者直连,应该也是没问题的
- #- include_role: name=jdk
- - include_tasks: common.yml
- - include_tasks: backup.yml
- # 这里使用loop循环play_hosts(当前执行的主机),是为了实现一个蓝绿,当然,这是主机少的情况,
- # 如果一个应用有N台主机,这效率就很低了,这样的话,可以考虑设置全局serial来控制每次发布的比例
- # PS: 如果不需要可以把run_once与loop去掉, ab_deploy.yml里的delegate_to去掉
- - include_tasks: ab_deploy.yml
- loop: "{{ play_hosts }}"
- run_once: true
- become: yes
[\d+\.]{3,}\d+
tasks/common.yml(公共配置,预配置环境,创建目录等)
- ---
- - set_fact:
- BASENAME: "{{ ansible_hostname.split('-')[2] }}-{{ SERVER_PORT }}-{{ PROJECT }}"
- when: (SERVER_PORT is defined) and (SERVER_PORT != "")
- - set_fact:
- BASENAME: "{{ ansible_hostname.split('-')[2] }}-{{ PROJECT }}"
- when: (SERVER_PORT is not defined) or (SERVER_PORT == "")
- - set_fact:
- WORKPATH: "{{ PROJECT_DIR }}/{{ BASENAME }}"
- - name: 检查 {{ WORKPATH }} 工作路径
- stat: path={{ WORKPATH }}
- register: work
- - name: 检查systemd
- stat: path={{ SYSTEMD_PATH }}/{{ PROJECT }}.service
- register: systemd
- - block:
- - name: 创建 {{ WORKPATH }}
- file: path={{ item }} state=directory owner={{ REMOTE_USER }} group={{ REMOTE_USER }} recurse=yes
- with_items:
- - "{{ WORKPATH }}"
- - "{{ LOGPATH }}"
- - name: 推送syetmed模板
- template: src=systemd.service.j2 dest={{ SYSTEMD_PATH }}/{{ PROJECT }}.service
- become: yes
- - name: Local | find package
- find: paths={{ WORKSPACE }} patterns=".*{{ PROJECT.split('-')[0] }}.*\.jar$" age=-60 age_stamp=mtime recurse=yes use_regex=yes
- delegate_to: localhost
- register: target_file
- - assert:
- that:
- - "target_file.files.0.path is defined"
- msg: "未找到构建文件,请检查构建过程"
- - set_fact:
- package: "{{ target_file.files.0.path }}"
- # 推送管理脚本
- - name: Push script
- template: src=service.sh.j2 dest={{ WORKPATH }}/{{ PROJECT }}.sh mode=0750
tasks/backup.yml(备份应用)
- ---
- - name: 获取远程文件信息
- stat:
- path: "{{ WORKPATH }}/{{ PROJECT }}.jar"
- register: history_pkg
- # 获取一个时间点
- - set_fact: backup_time={{ '%Y%m%d_%H%M' | strftime }}
- - block:
- # 在控制端创建了一个空的目录?(至于为什么要建一个空的目录,后面回滚会用到)
- - name: Create local flag
- file: path={{ BACKUP }}/{{ backup_time }} state=directory recurse=yes
- delegate_to: localhost
- run_once: true
- # 在远程主机创建备份目录
- - name: Create backup directory
- file:
- path: "{{ BACKUP }}/{{ backup_time }}"
- state: directory
- owner: "{{ REMOTE_USER }}"
- group: "{{ REMOTE_USER }}"
- recurse: yes
- become: yes
- # 备份到远程主机的本地路径
- - name: Backup {{ PROJECT }}
- shell: |
- \cp -ra {{ WORKPATH }}/* {{ BACKUP }}/{{ backup_time }}/
- # 远程文件存在才备份
- when: history_pkg.stat.exists
tasks/ab_deploy.yml(逐台推送打包文件,重启应用)
- ---
- # 有人可能会问delegate_to为何不写外层的include_tasks,其实这似乎是不支持或者是bug,
- # include_tasks获取的执行对象居然是同一个,导致delegate_to+loop只在一台机器上生效
- # 不过我们item写在block里获取是正常的,有兴趣的童鞋可以试试。
- # PS:不需要ab发布可以去掉delegate_to
- - block:
- # 推送编译好的jar包
- - name: Push {{ package }} --> {{ WORKPATH }}/{{ PROJECT }}.jar
- copy: src={{ package }} dest={{ WORKPATH }}/{{ PROJECT }}.jar mode=0640
- - name: Restart Service
- systemd: name={{ PROJECT }} state=restarted enabled=yes daemon_reload=yes
- become: yes
- # 等待服务打开端口提供服务,超时30s,注意到,这里只有定义了SERVER_PORT才执行
- # 相对的,你可以走接口或者页面检查页面的状态码或者返回内容来做一样的判断,
- # 参考模块: shell,uri,until
- # PS: 不需要ab发布可以去掉delegate_to
- - name: Wait for {{ SERVER_PORT }} available
- wait_for:
- host: "{{ ansible_default_ipv4.address }}"
- port: "{{ SERVER_PORT }}"
- delay: 5
- timeout: 30
- when: SERVER_PORT is defined
- delegate_to: "{{ item }}"
- # 上面的wait失败后执行的任务,(非必要,要么真的慢,要么是真的没起来)
- # 这里也可以放其他任务,比如直接fail模块失败消息,或者失败的回滚策略?
- rescue:
- - debug:
- msg: "{{ PROJECT }} {{ SERVER_PORT }} timeout more the 30s!"
templates/service.sh.j2
- #!/bin/bash
- # public func
- source /etc/init.d/functions
- # Env
- source /etc/profile
- # program
- program="{{ PROJECT }}.jar"
- # work path
- work_path={{ WORKPATH }}
- # check --no-daemonize option
- args=$2
- # other args
- {# 这里可以设置很多jinja2的判断,根据不同模块,业务配置不同的一些需要的参数 #}
- {# eureka账户密码,非必要,根据自己的业务来吧 #}
- {% if ENV == 'STG' %}
- # eureka账户名
- export EUREKA_USER='abc'
- # eureka密码
- export EUREKA_PASS='123'
- {% endif %}
- # jmx,按需吧。
- # JMX_OPTS="-Djava.rmi.server.hostname={{ ansible_default_ipv4.address }} -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1{{ SERVER_PORT | default('9990') }} -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
- # JAVA OPTIONS
- {# 这些参数其实是从jenkins的参数化构建传入到jenkins的ansible插件里的高级选项里的extra vars传入的 #}
- {# 这里我们的eureka配置项是环境变量传入的,各位的方式可能不同,自己斟酌 #}
- {# 判断是否包含eureka_conf选项,有则为注册中心配置(eureka_conf也是从jenkins传入) #}
- {% if eureka_conf is defined %}
- JAVA_OPTS="{{ JAVA_OPTS }} -Dspring.profiles.active={{ eureka_conf }} $JMX_OPTS"
- {% else %}
- JAVA_OPTS="{{ JAVA_OPTS }} $JMX_OPTS"
- {% endif %}
- get_pid() {
- ps -eo pid,cmd | grep java | grep "${program}" | grep -Ev "grep|python" | awk '{print $1}'
- }
- run_program() {
- cd ${work_path}
- if [[ "${args}"x == "--no-daemonize"x ]];then
- # 至于为什么要放在前台执行,是为了将程序交给systemd管理
- java -jar ${JAVA_OPTS} ${program}
- else
- nohup java -jar ${JAVA_OPTS} ${program} &> /dev/null &
- fi
- [[ $? -eq 0 ]] && return 0 || return 1
- }
- run_or_not() {
- pid=$(get_pid)
- if [[ ! ${pid} ]];then
- return 1
- else
- return 0
- fi
- }
- start() {
- run_or_not
- if [[ $? -eq 0 ]];then
- success;echo -e "${program} is running..."
- else
- cd ${work_path} && run_program
- if [[ $? -eq 0 ]];then
- sleep 1
- pid=$(get_pid)
- if [[ "$pid"x != x ]];then
- flag=success
- else
- flag=failure
- $flag;echo -e "Success Start ${program}, but it exists.!"
- exit 1
- fi
- else
- flag=failure
- fi
- $flag;echo -e "[$pid] Start ${program}"
- fi
- }
- stop() {
- run_or_not
- if [[ $? -eq 0 ]];then
- pid=$(get_pid)
- kill -9 $pid
- if [[ $? -eq 0 ]];then
- flag=success
- else
- flag=failure
- fi
- $flag;echo -e "Stop $program"
- else
- $flag;echo -e "$program is not running."
- fi
- }
- status() {
- run_or_not
- if [[ $? -eq 0 ]];then
- pid=$(get_pid)
- success;echo -e "[$pid] $program is running..."
- exit 0
- else
- failure;echo -e "$program not running."
- exit 1
- fi
- }
- case $1 in
- start)
- start
- ;;
- stop)
- stop
- ;;
- status)
- status
- ;;
- restart)
- stop
- sleep 1
- start
- ;;
- *)
- echo "Usage: $0 {start [--no-daemoize]|stop|status|reload|restart}"
- exit 1
- esac
templates/systemd.service.j2
- [Unit]
- Description={{ PROJECT }}
- After=network.target
- [Service]
- {# --no-daemonize这里放在前台启动了 #}
- ExecStart={{ WORKPATH }}/{{ PROJECT }}.sh start --no-daemonize
- ExecStop={{ WORKPATH }}/{{ PROJECT }}.sh stop
- WorkingDirectory={{ WORKPATH }}
- {# 按需配置重启策略吧 #}
- #Restart=on-failure
- #RestartSec=30
- User={{ REMOTE_USER }}
- Group={{ REMOTE_USER }}
- RuntimeDirectory={{ PROJECT }}
- RuntimeDirectoryMode=0755
- [Install]
- WantedBy=multi-user.target
注:为何要注册到systemd呢?一个是统一管理维护(业务环境复杂多样,go/python/java/.net core有脚本启动的,有中间件管理启动的,管理方式层出不穷),以及结合journalctl捕获控制台的输出日志
Jenkins结合Ansible的自动发布
1)jenkins依赖插件描述
- Ansible plugin: 执行Ansible所需插件。
- AnsiColor:彩色输出,非必须
- Build With Parameters:参数化构建需要
- Git plugin:git需要
- JDK Parameter Plugin:自己按需吧
- Mask Passwords Plugin:参数化构建,加密密码类参数,非必须
- Readonly Parameter plugin:参数化构建里的,只读参数选项
- Active Choices Plug-in: 动态参数插件,发布不会用到,后面会介绍,有奇用
- Run Selector Plugin:参数化构建,选择插件
- Git Parameter Plug-In:git分支选择插件,非必要
2)jenkins项目命名规范
{环境}_{项目组}_{应用名},如:STG_AIO_gateway, STG_AIO_basic-data
ps: 不一定按照这个规则写,根据自己需求改动上下文吧。
3)jenkins项目配置(以配置中心为例)
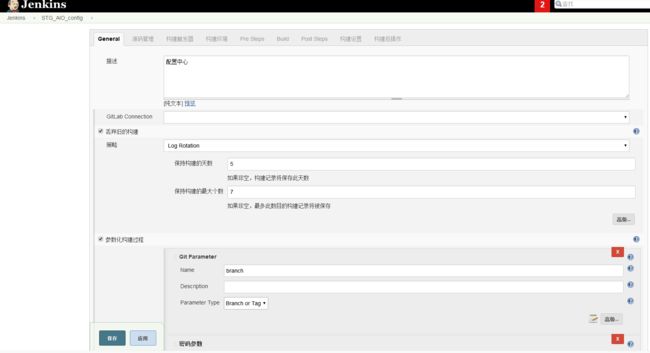
这里的STG_USER_PASS,ROOT_PASS是远程服务的登录密码,传递给ansible作为登录依据,当然你做了互信或者其他方式也可以的

这里描述了业务环境,服务对外提供端口,以及java的配置参数

Git的配置

构建的配置
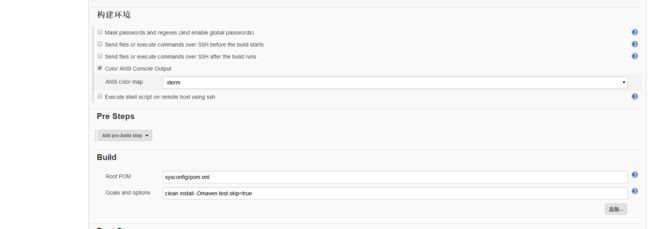
接下来是最关键的ansible配置
这里我们把主机inventory信息跟账户验证都写在了页面文本中(这种方式的好处是什么?是你可以随时新增可用主机来添加实例,而不需要调整其他)
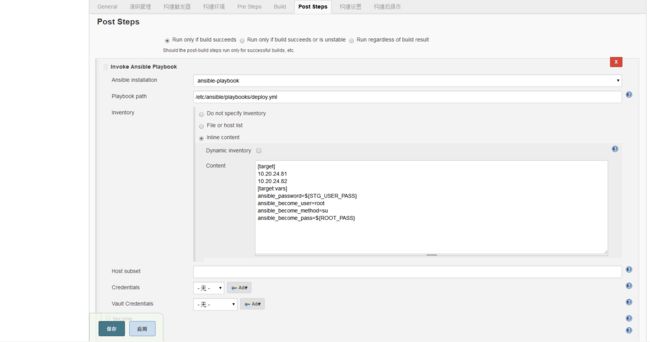
不难看出这里的content就是inventory,我们也很容易的通过content的vars配置各种差异和传值,十分的方便,比如,我们配置的eureka实例,要配置主从复制,启动的参数是有差异的,从前面的service.sh.j2我们也看到了eureka的一些jinja2判断,那么它判断参数的来源就是这个content的东西,如下图的eureka配置示例所示:
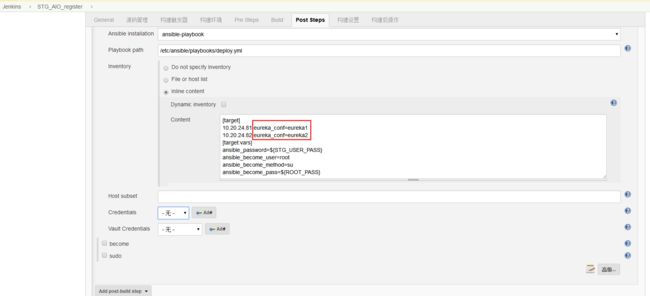

接下来,我们继续点开下方的高级选项,配置extra vars来传入前面的参数化构建的参数以及一些内置参数


至此,关键的配置已经完成了,如果有需要,各位还可以配置一些邮件通知什么的。
4)发布动图演示
发布后的回滚
由于各种各样的原因,发布的代码可能会出现异常,这时候可能需要紧急回滚代码,庆幸的是,我们前面有做备份策略,我们可以手动去回滚备份的代码,但是缺点也很明显,当主机实例过多时,手动回滚明显是不再明智的,所以我们想办法结合Jenkins+Ansible这两者来做到一个通用的服务回滚策略,首先我们先分析下我们回滚代码需要用到什么?
- 代码的历史备份
- 回滚应用名称
- 需要回滚的主机
首先看下第1点,我们发布过程是是有对代码做备份的。再看第2,3点,应用名称跟回滚的主机哪里可以获取到呢?答案是jenkins job里。
我们来看下JENKINS_HOME下对应的job是什么样的。
- # 进去你的jenkins家目录
- cd /data/jenkins/
- ls STG_AIO_config/
- builds config.xml lastStable lastSuccessful modules nextBuildNumber
我们通过拆分目录名STG_AIO_config可以得到{环境},{项目分组},{应用名称}等信息,而主机信息就在config.xml的content字段内!
- # 以下是config.xml的部分配置片段
-
/etc/ansible/playbooks/deploy.ymlplaybook> - <inventory class="org.jenkinsci.plugins.ansible.InventoryContent">
-
[target] - 10.20.24.81
- 10.20.24.82
- [target:vars]
- ansible_password=${STG_USER_PASS}
- ansible_become_user=root
- ansible_become_method=su
- ansible_become_pass=${ROOT_PASS}
- CFG_SVR_USER=${CFG_SVR_USER}
- CFG_SVR_PASS=${CFG_SVR_PASS}
- CFG_SVR_KEY_PASS=${CFG_SVR_KEY_PASS}
- CFG_SVR_KEY_SECRET=${CFG_SVR_KEY_SECRET}content>
-
falsedynamic> - inventory>
-
ansible-playbookansibleName>
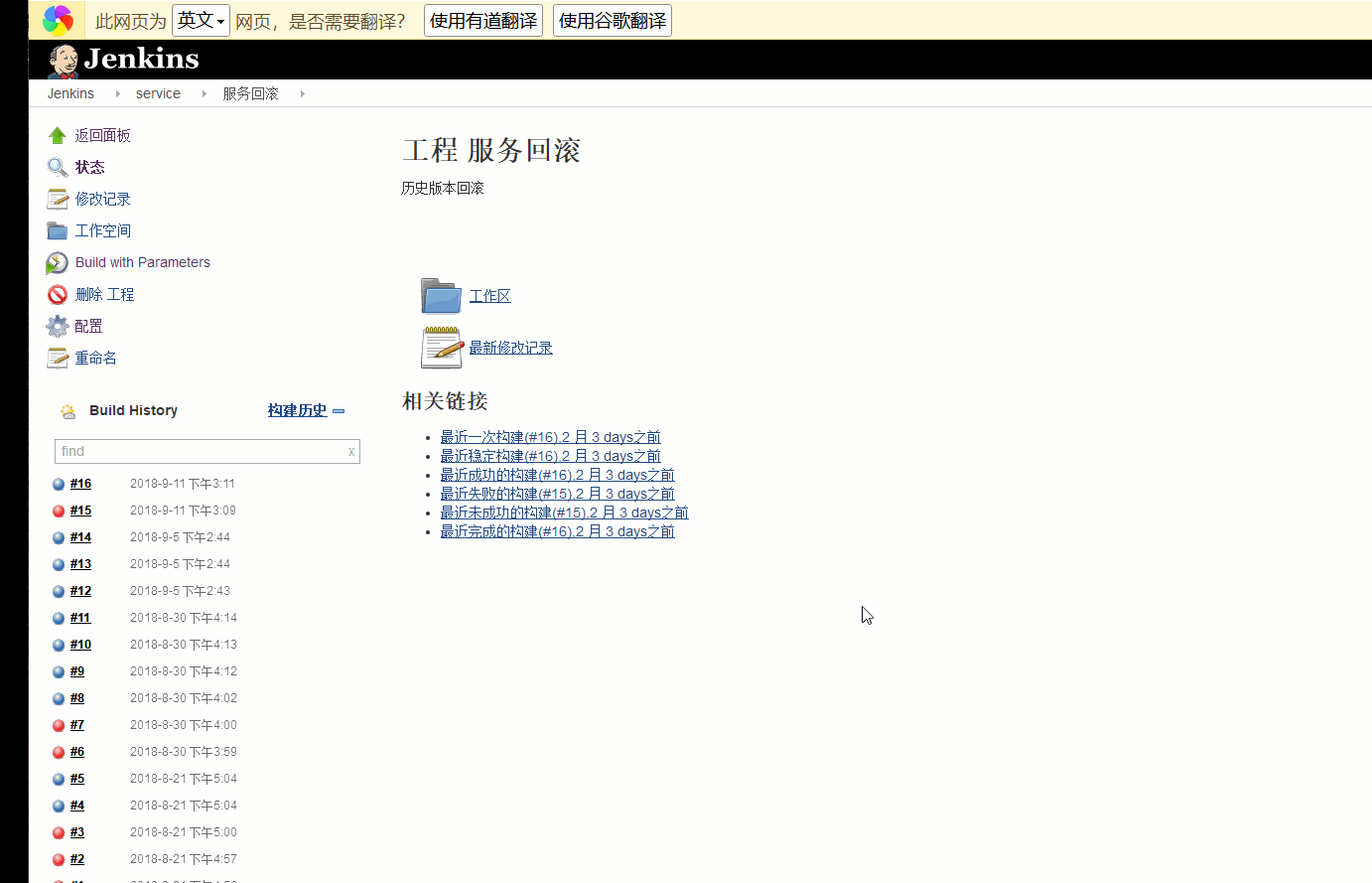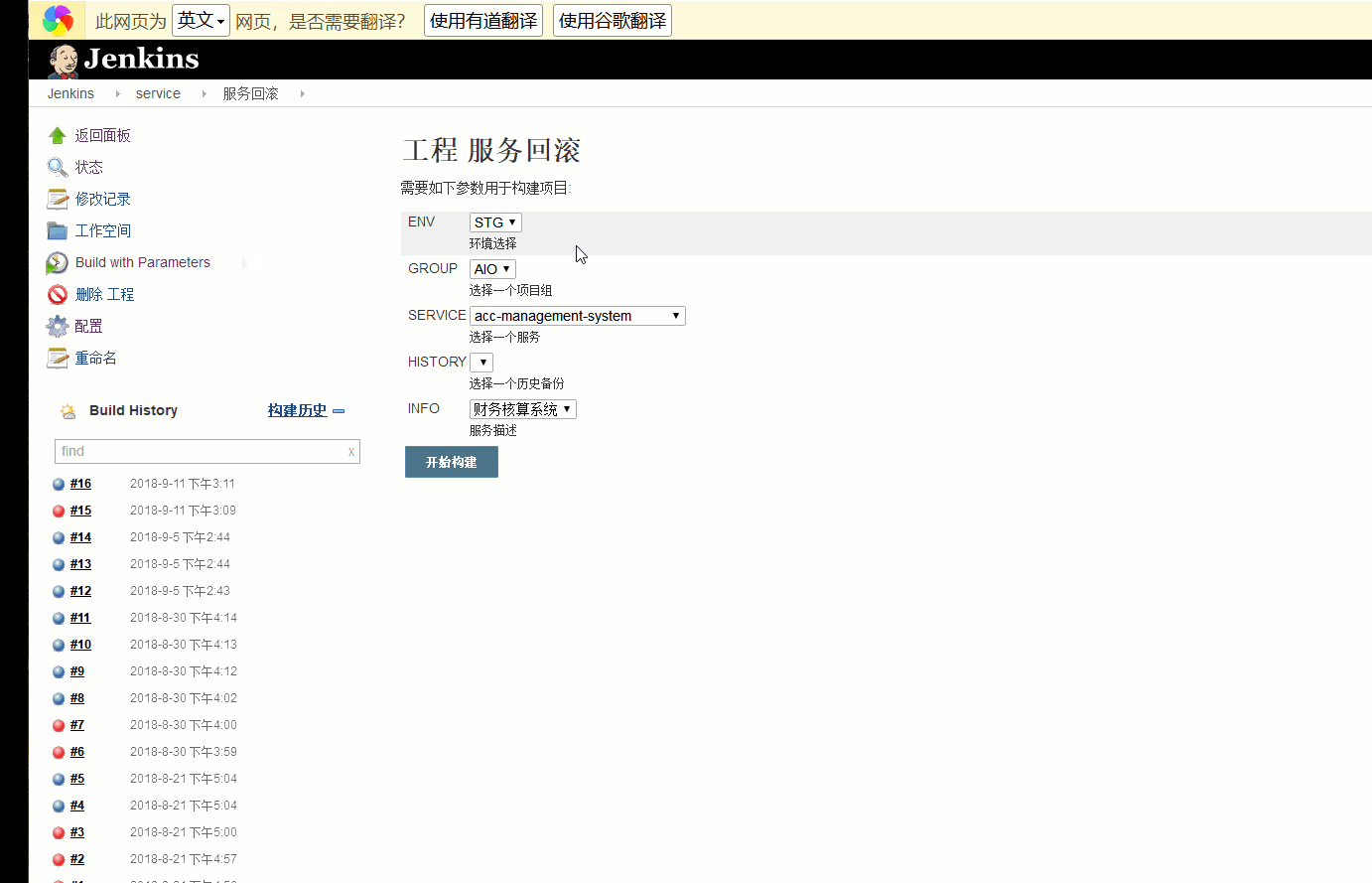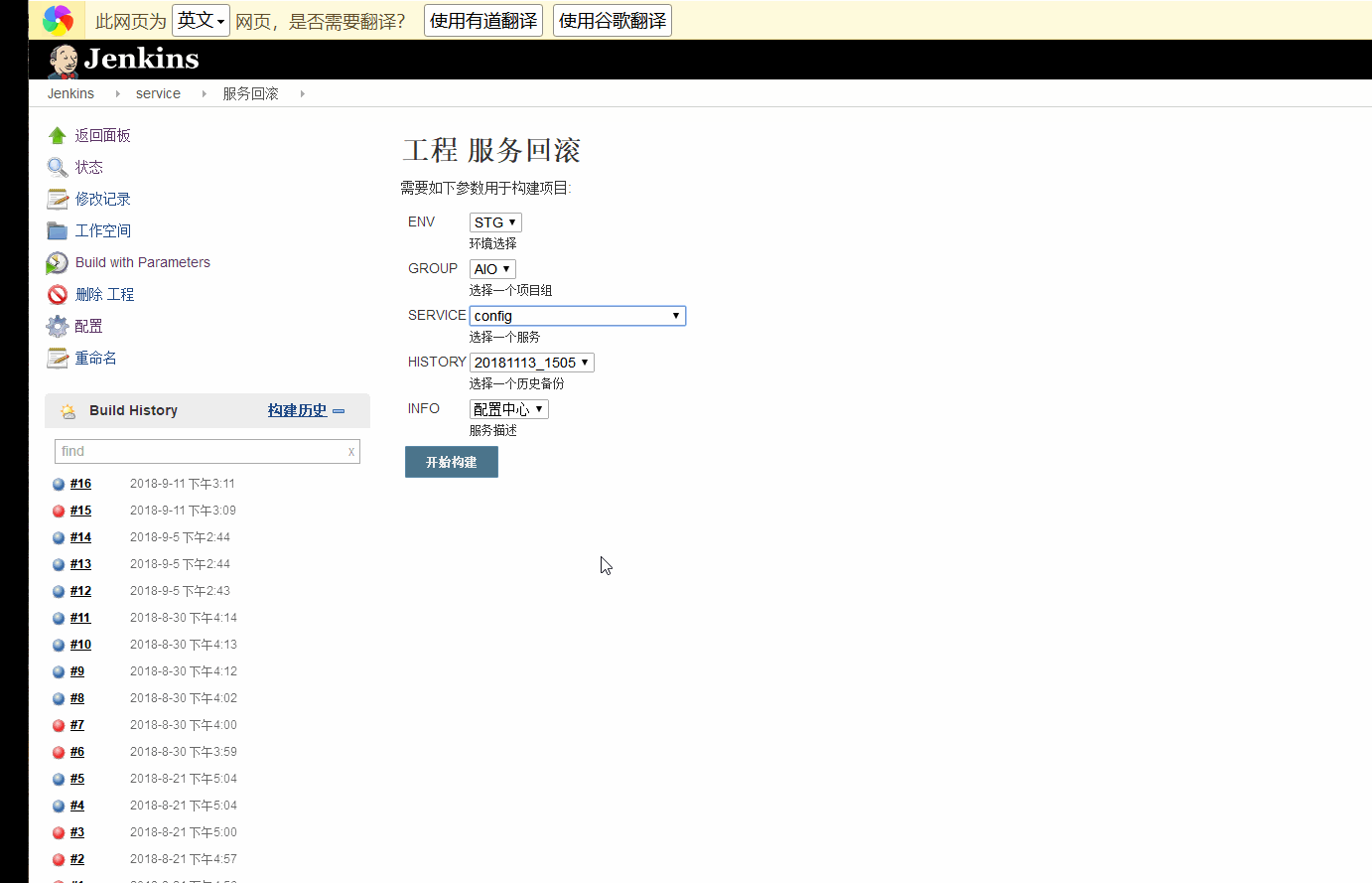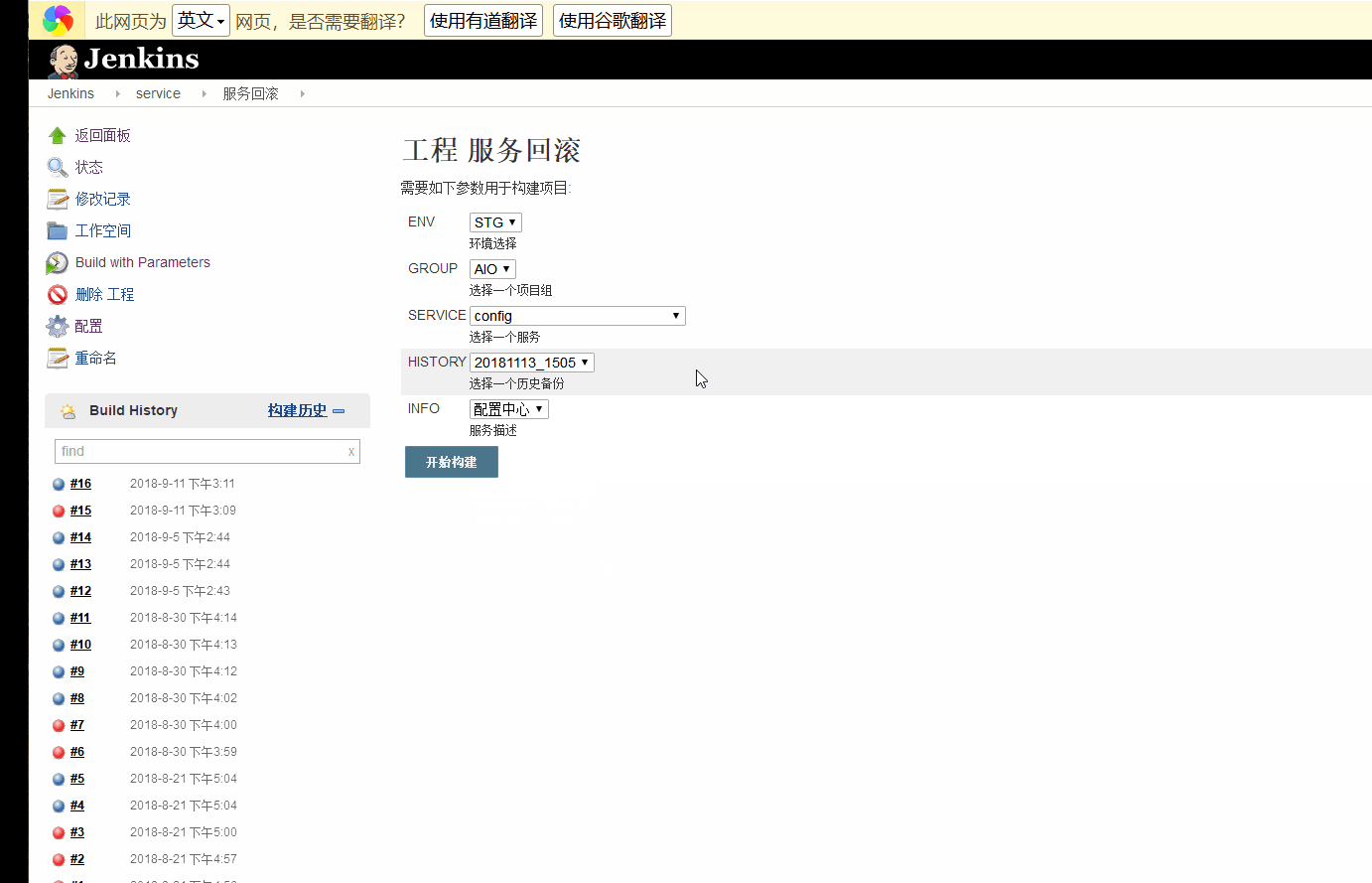
首先我们看一下成品的一个截图效果。
接下来,我们看看jenkins里是如何做到的。
1)创建回滚任务的jenkins job
我们新建了一个常规job,叫服务回滚(自己随便叫啥),通过参数化构建插件{环境},{项目分组},{应用名称},再通过shell命令获取config.xml里的主机信息,又通过{应用名称}获取备份目录下(还记得在前面的发布环节我们在Jenkins本机创建的空目录么,当然你也可以写文件里读取)备份目录名称得到历史还原点,于是得到了前面需要的3个点。
现在我们来看看怎么做。新建的job叫服务回滚

下拉选择参数化构建,选择动态参数,新建一个Avctive Choices Parameter ==>ENV,选择Groovy script,里面用groovy套了一个shell去执行(当然,你groovy熟悉不套shell能获取一个列表也行),
Choice Type选择Single Select,即单选框
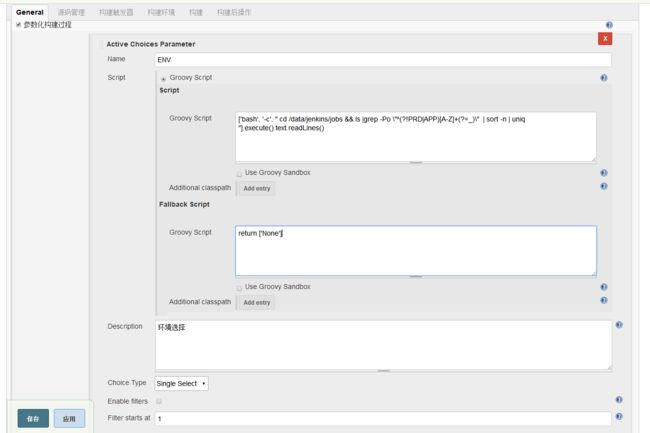
这个shell能获取到什么呢?我们看下
- #为了演示效果我新建的PROD,DEV的目录
- [root@sz-rjy-ops-ansible-config-23-222 config]# cd /data/jenkins/jobs && ls |grep -Po '^(?!PRD|APP)[A-Z]+(?=_)' | sort -n | uniq
- DEV
- PROD
- STG
可以知道,我们这里是获取了多个{环境}
接下来,我们添加第二个参数Active Choices Reactive Parameter(要引用其他参数)==> GROUP,Groovy Script里多了一个env=ENV是为了引入前面获取的ENV,Choice Type里继续勾选单选框,
不同的是下面多了一个Referenced parameter,这里填写ENV(这个是因为要关联上面的ENV)

我们代入ENV,看下shell下能获取到什么呢?
- [root@sz-rjy-ops-ansible-config-23-222 config]# env=STG
- [root@sz-rjy-ops-ansible-config-23-222 config]# cd /data/jenkins/jobs && ls -d $env* | grep -Po '(?<=_)[A-Z0-9]+(?=_)' | sort -n | uniq
- AIO
- J
获取到了{项目分组}
接下来,我们添加第三个动态参数Active Choices Reactive Parameter(要引用其他参数)==>SERVICE,Groovy Script里多了一个env=ENV,group=GROUP是为了引入前面获取的ENV跟GROUP,Choice Type里继续勾选单选框,
不同的是下面多了一个Referenced parameter,这里填写ENV,GROUP(这个是因为要关联上面的ENV,GROUOP)
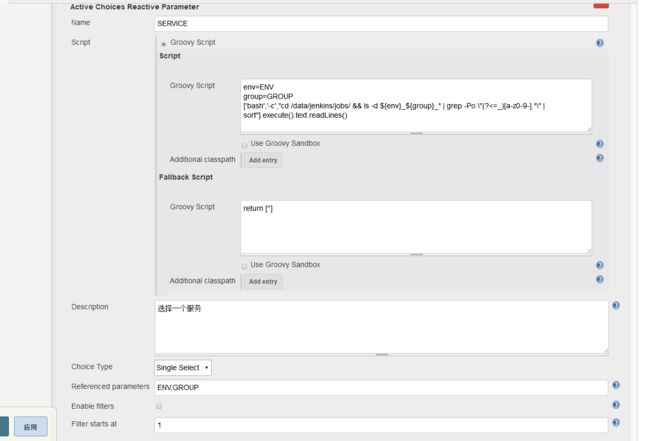
我们看下这个shell又能获取到什么
- [root@sz-rjy-ops-ansible-config-23-222 config]# env=STG
- [root@sz-rjy-ops-ansible-config-23-222 config]# group=AIO
- [root@sz-rjy-ops-ansible-config-23-222 config]# cd /data/jenkins/jobs/ && ls -d ${env}_${group}_* | grep -Po "(?<=_)[a-z0-9-].*" | sort
- basic-data
- bootadmin
- ce-system
- config
- gateway
- jobs-acc-executor
- loan-batch
- monitor
- eureka
- zipkin
- 。。。 。。。
这里我们获取到了{应用名}
最后,我们再配置一个Active Choices Reactive Parameter==>HISTORY,用于获取历史版本,选择单选框,关联SERVICE参数

我们执行shell试下
- [root@sz-rjy-ops-ansible-config-23-222 config]# service=config
- [root@sz-rjy-ops-ansible-config-23-222 config]# cd /data/backup/$service/ && ls | sort -nr | head -n10
- 20181113_1505
- 20181113_1502
- 20181113_1437
- 20181113_1434
- 20181113_1432
- 20181113_1425
- 20181113_1415
- 20181112_1118
- 20181112_1110
- 20181112_1105
获取到了历史的备份点。
作为可选项,我们还可以加个Active Choices Reactive Parameter==>INFO的动态参数构建,用于获取config.xml里的job描述,这里要关联三个参数ENV,GROUP,SERVICE
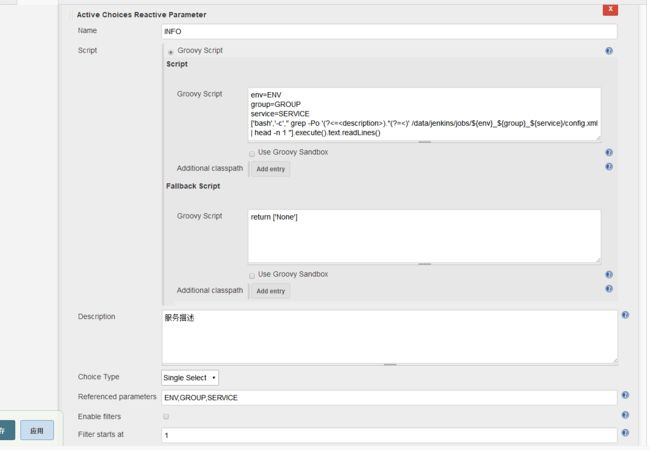
shell内执行效果如下:
- [root@sz-rjy-ops-ansible-config-23-222 config]# env=STG
- [root@sz-rjy-ops-ansible-config-23-222 config]# group=AIO
- [root@sz-rjy-ops-ansible-config-23-222 config]# service=config
- [root@sz-rjy-ops-ansible-config-23-222 config]# grep -Po '(?<=
).*(?=<)' /data/jenkins/jobs/${env}_${group}_${service}/config.xml | head -n 1 - 配置中心
正确获取到了描述信息。
我们正确获取到了{环境},{项目分组},{应用名}以及{历史备份点}等信息,但是还没有关联的inventory,既然inventory信息在config.xml中已有,我们可以通过声明ENV,GROUP,SERVICE环境变量,再通过脚本获取这几个值来拼接出config.xml所在位置,再通过解析xml来获取主机host,得到一个ansible动态inventory,(不单单是host,我们可以在xml里获取各种我们定义的值来作为inventory vars变量为我们所用!)
我们在jenkins下拉到构建选项,添加一个Executor shell
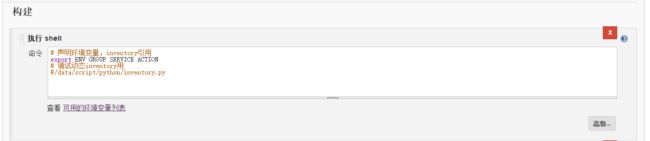
我们将ENV,GROUP,SERVICE声明到了执行的环境变量中,
我们再看看inventory这个脚本是如何获取的。
- cat /data/script/python/inventory.py
- #!/usr/bin/python
- # -- encoding: utf-8 --
- ## pip install xmltodict ##
- import xmltodict
- import json
- import re
- import os
- # 从环境变量获取参数
- # 账号密码你做了信任就不需要,自己看着办
- options = {
- 'ENV': os.getenv('ENV'),
- 'GROUP': os.getenv('GROUP'),
- 'SERVICE': os.getenv('SERVICE'),
- 'ACTION': os.getenv('ACTION'),
- 'ansible_user': 'stguser',
- 'ansible_password': 'abc',
- 'ansible_become_pass': '123',
- 'ansible_become_method': 'su',
- 'ansible_become_user': 'root',
- 'ansible_become': True
- }
- def getXml(env,group,service):
- ''' 拼接对应项目的jenkinx config.xml路径'''
- file = '/data/jenkins/jobs/{}_{}_{}/config.xml'.format(env,group,service)
- return file
- def getData(file):
- data = dict()
- xml = open(file)
- try:
- xmldata = xml.read()
- finally:
- xml.close()
- convertedDict = xmltodict.parse(xmldata)
- # maven2 项目模板数据提取
- if convertedDict.has_key('maven2-moduleset'):
- name = convertedDict['maven2-moduleset']['rootModule']['artifactId']
- _ansi_obj = convertedDict['maven2-moduleset']['postbuilders']['org.jenkinsci.plugins.ansible.AnsiblePlaybookBuilder']
- # 可能有多个playbbok,只要是inventory一样就无所谓取哪一个(这里取第一个,如果多个不一样,自己想办法合并)
- if isinstance(_ansi_obj,list):
- host_obj = _ansi_obj[0]['inventory']['content']
- else:
- host_obj = _ansi_obj['inventory']['content']
- data['hosts'] = re.findall('[\d+\.]{3,}\d+',host_obj)
- # 如果设置了参数化构建,把只读参数作为ansible参数
- if convertedDict['maven2-moduleset']['properties'].has_key('hudson.model.ParametersDefinitionProperty'):
- parameter_data = convertedDict['maven2-moduleset']['properties']['hudson.model.ParametersDefinitionProperty']['parameterDefinitions']['com.wangyin.ams.cms.abs.ParaReadOnly.WReadonlyStringParameterDefinition']
- # 这里使用的自由风格模板模板,数据结构与maven2不一样,需要拆开判断
- if convertedDict.has_key('project'):
- host_obj = convertedDict['project']['builders']['org.jenkinsci.plugins.ansible.AnsiblePlaybookBuilder']['inventory']['content']
- data['hosts'] = re.findall('[\d+\.]{3,}\d+',host_obj)
- # 如果设置了参数化构建,把只读参数作为ansible参数
- if convertedDict['project']['properties'].has_key('hudson.model.ParametersDefinitionProperty'):
- parameter_data = convertedDict['project']['properties']['hudson.model.ParametersDefinitionProperty']['parameterDefinitions']['com.wangyin.ams.cms.abs.ParaReadOnly.WReadonlyStringParameterDefinition']
- # 插入参数化构建参数(我这里是只读字符串参数)
- try:
- for parameter in parameter_data:
- data[parameter['name']] = parameter['defaultValue']
- except:
- pass
- #print(json.dumps(convertedDict,indent=4))
- return data
- def returnInventory(xmldata,**options):
- ''' 合并提取的数据,返回inventory的json'''
- inventory = dict()
- inventory['_meta'] = dict()
- inventory['_meta']['hostvars'] = dict()
- inventory[options['SERVICE']] = dict()
- inventory[options['SERVICE']]['vars'] = dict()
- # 合并xmldata提取的数据
- for para_key,para_value in xmldata.items():
- # 单独把hosts列表提取出来,其他的都丢vars里
- if para_key == 'hosts':
- inventory[options['SERVICE']][para_key] = para_value
- else:
- inventory[options['SERVICE']]['vars'][para_key] = para_value
- # 合并options里的所有东西到vars里
- for opt_key,opt_value in options.items():
- inventory[options['SERVICE']]['vars'][opt_key] = opt_value
- return inventory
- if __name__ == "__main__":
- xmldata = getData(getXml(options['ENV'],options['GROUP'],options['SERVICE']))
- print(json.dumps(returnInventory(xmldata,**options),indent=4))
我们看看执行结果
- [root@sz-rjy-ops-ansible-config-23-222 config]# export ENV=STG GROUP=AIO SERVICE=config
- [root@sz-rjy-ops-ansible-config-23-222 config]# /data/script/python/inventory.py
- {
- "config": {
- "hosts": [
- "10.20.24.81",
- "10.20.24.82"
- ],
- "vars": {
- "ansible_become_method": "su",
- "GROUP": "AIO",
- "SERVER_PORT": "8888",
- "SERVICE": "config",
- "ansible_become_user": "root",
- "ansible_become": true,
- "ansible_user": "stguser",
- "ENV": "STG",
- "ansible_become_pass": "abc",
- "ACTION": null,
- "ansible_password": "123"
- }
- },
- "_meta": {
- "hostvars": {}
- }
- }
可以看到能正常的获取到一个动态inventory的json了
最后我们看下jenkins里的ansible配置,inventory执行了python脚本,并传入了一个extra vars 的HISTORY参数

2)Ansible role
目录结构
- playbooks/spring-rollback.yml # 入口文件
- roles/spring-rollback
- ├── defaults
- │ └── main.yml # 默认参数
- ├── README.md
- └── tasks
- ├── common.yml # 公共配置
- ├── main.yml # 主配置
- ├── rollback.yml # 回滚任务
playbooks/spring-rollback.yml
- ---
- - hosts: all
- pre_tasks:
- - assert:
- that:
- - "HISTORY != ''"
- fail_msg: '请选择一个正确的历史版本!'
- roles:
- - spring-rollback
defaults/main.yml
- ---
- # defaults file for rollback
- # 备份路径
- BACKUP: "/data/backup/{{ SERVICE }}/{{ HISTORY }}"
- OWNER: stguser
tasks/main.yml
- ---
- # tasks file for rollback
- - include_tasks: common.yml
- - include_tasks: rollback.yml
- loop: "{{ play_hosts }}"
- run_once: true
- become: yes
tasks/common.yml
- ---
- - shell: "ls -d /data/*{{ SERVICE }}"
- register: result
- - set_fact:
- src_package: "{{ BACKUP }}"
- dest_package: "{{ result.stdout }}"
tasks/rollback.yml
- ---
- - block:
- - name: 回滚{{ SERVICE }}至{{ HISTORY }}历史版本
- shell: |
- [[ -d {{ dest_package }} ]] && rm -rf {{ dest_package }}/*
- \cp -ra {{ src_package }}/* {{ dest_package }}/
- - name: Restart Service
- systemd: name={{ SERVICE }} state=restarted enabled=yes daemon_reload=yes
- become: yes
- - name: Wait for {{ SERVER_PORT }} available
- wait_for:
- host: "{{ ansible_default_ipv4.address }}"
- port: "{{ SERVER_PORT }}"
- delay: 5
- timeout: 30
- when: (SERVER_PORT is defined) or (SERVICE_PORT != '')
- delegate_to: "{{ item }}"
3)回滚演示
回滚前,我们先看看源文件的MD5
- ## 以下为应用服务器
- # md5sum /data/service-8888-config/config.jar
- aedebf60226bfa213e256c3602c59669 config.jar
- # md5sum /data/backup/config/20181113_1505/config.jar
- 6de7651f725133bd74f66873c025aafd /data/backup/config/20181113_1505/config.jar
执行回滚操作。
再次对比MD5
- [stguser@sz-rjy-service-java-aio-24-81 service-8888-config]$ md5sum config.jar
- 6de7651f725133bd74f66873c025aafd config.jar
可以发现,服务以及回滚到了我们指定的版本
服务管理
相同的,我们可以根据前面这个方式,配置一个管理服务的job,用于服务的启停(服务都是注册的systemd)
怎么实现这里就不再阐述了,对于其他的项目(tomcat/nginx)都是类似的,各位可以根据自己实际情况去做出一定的调整。