
1.文本分类
转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结。
本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于Text-CNN模型在搜狗新闻数据集上二分类的Demo。
文本分类是自然语言处理领域最活跃的研究方向之一,从样本数据的分类标签是否互斥上来说,可以分为文本多分类与文本多标签分类。
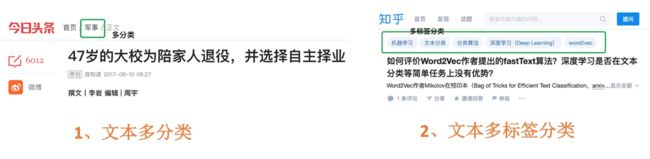
目前文本分类在工业界的应用场景非常普遍,从新闻的分类、商品评论信息的情感分类到微博信息打标签辅助推荐系统,了解文本分类技术是NLP初学者比较好的切入点,较简单且应用场景高频。

2.数据准备
在机器学习领域有一句话:数据决定了模型最终的高度,不断优化的模型只不过是为了不断逼近这个高度而已。
文本分类作为一种有监督学习的任务,毫无疑问的需要一个可用于有监督学习的语料集(X,Y)。本文中使用以下标记,X为特征,文本分类中即为文本序列,Y是标签,即文本的分类名称。
机器学习与传统编程技术的明显区别就是:机器学习是以数据为驱动的,传统的编程中,我们核心任务是人工设计分类规则(指令代码),然后实现输入特征X获得分类标签Y。而在机器学习的方式中,我们首要的是获得一个高质量的、大数据量的有监督语料集(X,Y),然后机器学习的方式会自动的从已构建的数据集上归纳出(训练出)一套分类规则(分类模型),最后我们利用获得的分类规则来实现对未标记文本的分类。
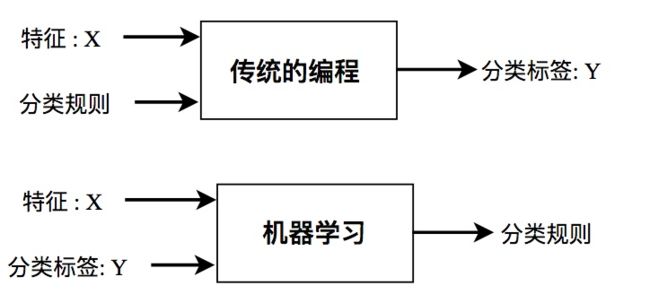
换言之,传统的编程方式输入的是指令代码,而机器学习输入的是结构化数据。
因此,在机器学习任务中,数据的质量与数量对最终模型的预测结果好坏具有决定性的作用。
常言道:Garbage in, garbage out!
在文本分类中,语料集(X,Y)的质量、数量决定了文本分类模型的分类效果。
语料集的质量:即数据集的特征X对应的标签Y是否标记的正确,一般在众包平台中会采用多人重复标记,然后基于投票的机制来控制语料集的标记质量。
语料集的数量:有监督语料集的标注复杂度,想要获得海量的高质量语料集的成本是十分高昂的,这也限制的语料集的数量。
在实际的文本分类任务中,一般通过搜集开源的数据集,或者利用爬虫获取结构化的网页信息来构建特定任务的语料集。不过,我还是更喜欢关注一些公开的竞赛项目,能够获得企业准备的高质量、应对真实业务场景的数据集,例如:kaggle、知乎的看山杯、mrc2018-cipsc等,但大多数情况下企业只给脱敏之后的数据.......

搜狗的新闻语料集:http://www.sogou.com/labs/resource/cs.php
3.文本的预处理
文本的预处理,主要针对剔除无意义的符号信息,或其它的冗余信息。例如,在使用爬虫获取的语料集上可能存在一些html的标签,这些符号对于文本分类任务来说应该是冗余的无意义信息,可以剔除掉。
此外,针对中文、日语等无空格切分字词的语言,还需要进行分词处理,将一段文本序列划分为合理的词(字)序列。
英文中天生的就有空格把每个词汇分割开来,所以不需要分词操作,但由于英文存在时态、缩写等问题,在预处理阶段会有词干提取、词性还原、大小写转换等。
中文分词的工具有非常多的方案,我一般习惯于使用Python版的JieBa分词工具包来进行分词的操作,使用非常的简单,使用pip install jieba就可以很方便的安装该工具包,jieba常用的API可以查看GitHub主页的实例。

推荐阅读:
中文分词原理【https://www.jianshu.com/p/6c085bf1086f】
JieBa的GitHub官网:https://github.com/fxsjy/jieba
3.文本的数值化【词向量技术】
文本的数值化,即使用数字代表特定的词汇,因为计算机无法直接处理人类创造的词汇。为了让计算机能够理解词汇,我们需要将词汇信息映射到一个数值化的语义空间中,这个语义空间我们可以称之为词向量空间(词向量模型)。
文本的数值化方式有很多种,例如:TF-IDF、BOW、One-Hot、分布式的表示方式(word2vec、Glove)等。
我一般常用的就是最经典的word2vec工具,该工具在NLP领域具有非常重要的意义!
word2ve工具,它是一种无监督的学习模型,可以在一个语料集上(不需要标记,主要思想是“具有相似邻近词分布的中心词之之间具有一定的语义相似度”),实现词汇信息到语义空间的映射,最终获得一个词向量模型(每个词汇对应一个指定维度的数组)。
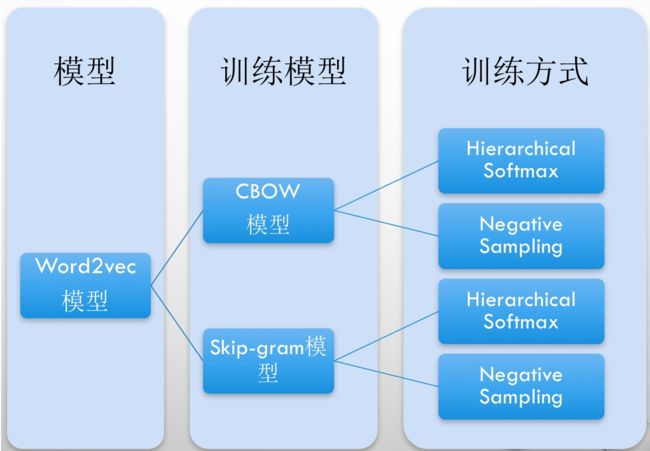
它的核心优势就是实现了两个词汇信息之间的语义相似度的可计算性,也可以理解为是一种迁移学习的思想,word2vec获取的意义空间信息作为后续文本分类模型的输入。
python 中使用word2vec工具也是非常的便利,通过pip install gensim安装gensim工具包,此包汇总包含了word2vec工具。
【注:Ubuntu与Mac系统安装的gensim包中word2vec的API存在一些差异!】
Gensim官网:https://radimrehurek.com/gensim/models/word2vec.html

今天大多数用于自然语言处理的深度学习模型都依赖词向量来代表单个单词的含义。对于不太熟悉这领域的人而言,可以这样简单的理解:我们把每一种语言中的每一个单词都与一串被叫做向量的数字联系起来了。

以上就是深度学习模型需要的数据格式的核心处理流程,在整个处理过程中样本数据的处理流程如下图所示:

4.文本分类模型
文本分类模型,可以大体上分为基于传统机器学习的文本分类模型,基于深度学习的文本分类模型,目前基于深度学习模型的文本分类模型已经成为了主流,下面基于CNN的文本分类模型。
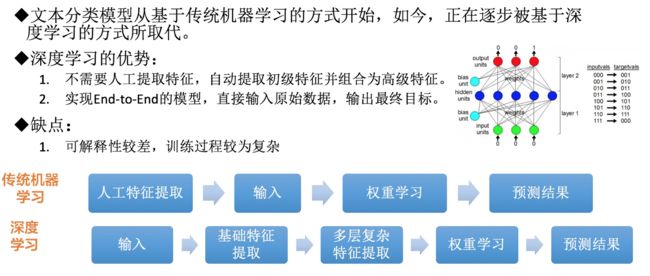
文本分类模型,从最经典的2013年Kim提出Text-CNN模型开始,深度学习模型在文本分类任务上具有广泛的应用。2016年Kim跳槽FaceBook后提出了工业界的文本分类模型的“新宠”—FastText。

为了实现文本分类模型,需要借助开源的深度学习框架,这样在开发中就不需要自己从零实现整个深度学习模型的各个功能模块。如果你之前做过Java Web开发的话,肯定也使用过SSH或SSM等框架来简化你的开发工作。
深度学习框架有很多优秀的框架,我一般使用比较流行的tensorflow计算框架,该框架的使用者比较多,可以查阅的学习资料非常多,Github上的开源代码也比较多,非常有利于我们学习。
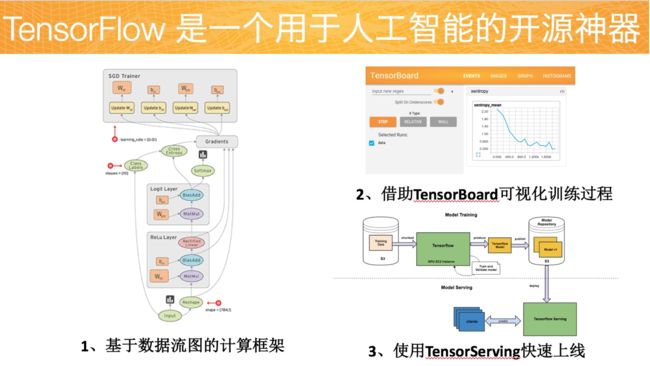
文本分类的技术路线【研二时实验室内部的技术分享PPT】:

目前深度学习在NLP的文本分类任务中已经具有比较广泛的探究,其中经典的深度学习模型结构有以下三种:
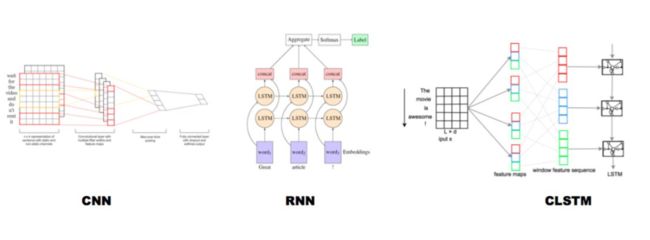
本文选择使用2013年Kim提出的Text-CNN模型作为文本分类模型,通过验证实验以及业界的共识,在文本分类任务中,CNN模型已经能够取到比较好的结果,虽然在某些数据集上效果可能会比RNN稍差一点,但是CNN模型训练的效率更高。所以,一般认为CNN模型在文本分类任务中是兼具效率与质量的理想模型。
卷积神经网络(CNN)的特点:
CNN的三个优点:
- sparse interaction(稀疏的交互)
- parameter sharing(参数共享)
- equivalent respresentation(等价表示)。
经典的简化卷积公式表示如下:

假设每个词用三维向量表示,左边是4个词,右边是卷积矩阵,那么得到输出为:
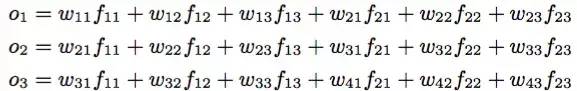
如果基于这个结果做1-MaxPool池化(最大值池化),那么就取卷积层结果 o 中的最大值,即提取最显著的特征。
针对海量的文本多分类数据,也可以尝试一下浅层的深度学习模型FastText模型,该模型的分类效率更高。
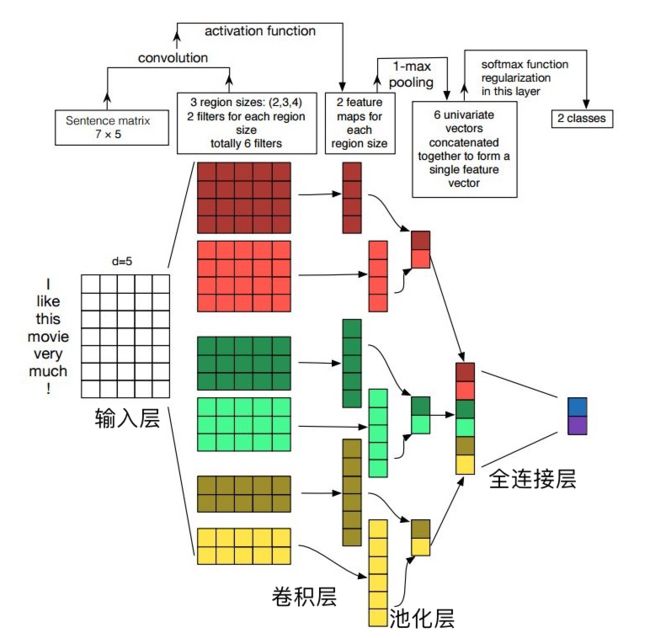
Kim提出的经典Text-CNN模型的整体网络架构如图所示,如果你学习过CNN或者CNN在图像中的使用,应该很容易就理解,因为该模型就是一个最简单、基础的CNN网络结构。
整个模型由四部分构成:输入层、卷积层、池化层、全连接层。
1.输入层(词嵌入层):
Text-CNN模型的输入层需要输入一个定长的文本序列,我们需要通过分析语料集样本的长度指定一个输入序列的长度L,比L短的样本序列需要填充(自己定义填充符),比L长的序列需要截取。最终输入层输入的是文本序列中各个词汇对应的分布式表示,即词向量。
对于输入层输入的词向量的表达方式,Text-CNN模型的作者Kim在论文中也分析了几个变种的方式:
1.static(静态词向量)
使用预训练的词向量,即利用word2vec、fastText或者Glove等词向量工具,在开放领域数据上进行无监督的学习,获得词汇的具体词向量表示方式,拿来直接作为输入层的输入,并且在TextCNN模型训练过程中不再调整词向量, 这属于迁移学习在NLP领域的一种具体的应用。
2.non-static(非静态词向量)
预训练的词向量+ 动态调整 , 即拿word2vec训练好的词向量初始化, 训练过程中再对词向量进行微调。
3.multiple channel(多通道)
借鉴图像中的RGB三通道的思想, 这里也可以用 static 与 non-static 两种词向量初始化方式来搭建两个通道。
4.CNN-rand(随机初始化)
指定词向量的维度embedding_size后,文本分类模型对不同单词的向量作随机初始化, 后续有监督学习过程中,通过BP的方向更新输入层的各个词汇对应的词向量。
2.卷积层:
在NLP领域一般卷积核只进行一维的滑动,即卷积核的宽度与词向量的维度等宽,卷积核只进行一维的滑动。
在Text-CNN模型中一般使用多个不同尺寸的卷积核。卷积核的高度,即窗口值,可以理解为N-gram模型中的N,即利用的局部词序的长度,窗口值也是一个超参数,需要在任务中尝试,一般选取2-8之间的值。

3.池化层:
在Text-CNN模型的池化层中使用了Max-pool(最大值池化),即减少了模型 的参数,又保证了在不定长的卷基层的输出上获得一个定长的全连接层的输入。
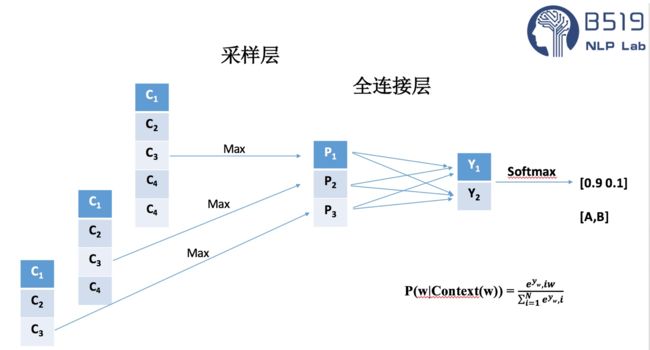
池化层除了最大值池化之外,也有论文讨论过 Top K最大值池化,即选取每一个卷积层输出的Top k个最大值作为池化层的输出。
卷积层与池化层在分类模型的核心作用就是特征提取的功能,从输入的定长文本序列中,利用局部词序信息,提取初级的特征,并组合初级的特征为高级特征,通过卷积与池化操作,省去了传统机器学习中的特征工程的步骤。
但TextCNN的一个明显缺点就是,卷积、池化操作丢失了文本序列中的词汇的顺序、位置信息,比较难以捕获文本序列中的否定、反义等语义信息。
4.全连接层:
全连接层的作用就是分类器,原始的Text-CNN模型使用了只有一层隐藏层的全连接网络,相当于把卷积与池化层提取的特征输入到一个LR分类器中进行分类。
至此,Text-CNN的模型结构就算大体了解了,有人把深度学习模型看作一个黑盒子,知道格式化的输入,我们就可以利用别人搭建好的模型框架训练在自己的数据集上实现一定的功能。但是在不同的数据集上,模型的最佳状态也不唯一,这就需需要我们在新的数据集上需要进行调优(调参)。
5.模型的效果评估与调优
针对分类问题,一般可以使用准确率、召回率、F1值、混淆矩阵等指标,在文本多标签分类中一般还会考虑标签的位置加权等问题。
分类模型中的主要参数:词向量的维度、卷积核的个数、卷积核的窗口值、L2的参数、DropOut的参数、学习率等。
这是在模型优化的过程中需要重点关注的参数。此外,一般数据集的类别不均衡问题对模型的影响也是比较显著的,可以尝试使用不同的方法,评估不同方案的模型效果。
文本分类中经常遇到的问题:
1.数据集类别不均衡
即语料集中,各个类别下的样本数量差异较大,会影响最终文本分类模型的效果。
主要存在两类解决方案:
(1)调整数据:数据增强处理,NLP中一般随分词后的词序列进行随机的打乱顺序、丢弃某些词汇然后分层的采样的方式来构造新的样本数据。

(2)使用代价敏感函数:例如图像识别中的Focal Loss等。
2.文本分类模型的泛化能力
首先,对于一个未知的样本数据,分类模型只能给出分类标签中的一个,无法解决不属于分类标签体系的样本。
我们无法预知未来的数据会是什么样的,也不能保证未来的所有分类情况在训练集中都已经出现过!
剩下影响分类模型泛化能力的就是模型过拟合的问题了。

如何防止过拟合?那就是老生常谈的问题了:
(1)数据上:交叉验证
(2)模型上:使用DropOut、BatchNorm、正则项、Early Stop。
3.关于模型的上线方案:
1、基于Java的:
请参考: https://www.ioiogoo.cn/2018/04/03/java%E8%B0%83%E7%94%A8keras%E3%80%81tensorflow%E6%A8%A1%E5%9E%8B/
2、基于Flask等python的web框架:
请参考:https://guillaumegenthial.github.io/serving.html

3、基于google官方的tensorflow Serving框架:
请参考:https://www.jianshu.com/p/c1cd2d127ae2
阿里的基于容器部署的方案:https://yq.aliyun.com/articles/60894?spm=a2c4e.11153959.blogcont60601.11.815eea72lw2ij
6.基于Text-CNN模型的中文文本分类Demo:
我从搜狗的开源的的新闻数据集(small版)中,选择了两个类别的数据:计算机与交通两个类别,构建了一个中文文本二分类的数据集。

实现文本二分类的Demo代码以及脚本运行的说明放在GitHub中:
https://github.com/x-hacker/CNN_ChineseTextBinaryClassify
以上就是简单的介绍了NLP中文本分类所涉及的主要流程,并给出了一个中文文本二分类的Demo代码。下面推荐一些拓展的资料,感兴趣的童鞋可以继续深入研究。
补充资源:
- 各种文本分类模型的实例代码:https://github.com/brightmart/text_classification
- 中文文本分类对比:https://github.com/Edward1Chou/Textclassification