以爬取英雄联盟所有的英雄数据为例
其实呀我们都知道爬虫这个功能比较常见,而且各大主流语言都支持,只不过就是擅长或者不擅长,简单或者不简单的区别了。
今天我要分享的就时NodeJs的爬虫玩法。
先陈述一下我们的示例需求:
- 爬取英雄联盟所有英雄的属性信息
英雄属性列表:
Hero:
title:英雄的称号
name:英雄的名字
position:英雄的定位
ability:英雄的能力life:生命
physicalAttack:物理攻击
magicAttack:魔法攻击
difficulty:操作难度
- 将爬取到的数据拼接为json格式
- 将json数据存入数据库中(以MySQL为例)
需求说了完了,接下来我们要安装需要的库,cheerio和mysql:
npm i cheerio mysql
或者
yarn add cheerio mysql
这里使用的npm或者yarn都可以(只要你喜欢就行)。
接下来我们需要在我们的mysql数据库中创建一个表:
DROP TABLE IF EXISTS `hero`;
CREATE TABLE `hero` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(20) NOT NULL,
`name` varchar(20) NOT NULL,
`position` varchar(50) NOT NULL,
`life` smallint(5) unsigned NOT NULL DEFAULT '0',
`physical_attack` smallint(5) unsigned NOT NULL DEFAULT '0',
`magic_attack` smallint(5) unsigned NOT NULL DEFAULT '0',
`difficulty` smallint(5) unsigned NOT NULL DEFAULT '0',
`create_time` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
注意:这里没有给出创建数据库的代码,记得选择一个或者创建一个新的数据库,然后再运行以上代码
完了之后我们就要开始写代码了(代码中会进行详细的注释,以方便各位理解):
// 引入cheerio库(它可以让我们像使用jQuery一样操作我们所爬取到的html代码)
const cheerio = require("cheerio");
// 引入NodeJs自带的http模块
const http = require("http");
// 引入mysql库(用于连接mysql,存储我们爬取到的英雄数据)
const mysql = require("mysql");
//数据库信息根据自己的情况来配
const sqlInfo = {
// 数据库主机名
"host": "127.0.0.1",
// 用户名
"user": "root",
// 密码
"password": "",
// 端口
"port": 3306,
// 连接的数据库名(你创建或选择的那个数据库)
"database": "test"
};
// 为了偷懒,给console.log函数绑定一个固定的宿主对象(说白了,都是为了少写几个字母)
const log = console.log.bind(console);
// 创建mysql数据库连接
const con = mysql.createConnection(sqlInfo);
// 连接数据库
con.connect();
// 封装一个用来爬虫的函数
// 参数解释:url是要爬取站点的网址(要带协议http://或者https://),func是对爬取成功的数据处理的回调函数
function getData(url, func) {
// 定义个变量用来存储爬取到的html数据
let html = "";
// 调用http模块的get方法请求url地址对应网站的html代码数据
http.get(url, res => {
// NodeJs是基于事件的(其主要特征之一),所以,只要有数据获取到,它就会触发data事件,我们要做的就是监听这个事件
res.on("data", data => {
// 事件给我们传递了一个data值,它就是网站html代码的一部分,我们要做的就是累加它
html += data;
});
// 同样的,到底这个获取数据的事情什么时候能结束呀,那就是这个end事件,它就会通知我们数据获取完毕,我们要做的同样就是监听它
res.on("end", () => {
// 执行到这一步,(不出意外的话)说明html里面就已经是url地址所对应的网站的html代码了,我们用cheerio来装载这个html代码,它会把这html进行dom分析,最终给我返回一个类似jQuery的对象,我们可以利用它来对这个庞大的html中的数据进行方便快捷的获取
let $ = cheerio.load(html);
// 执行我们的自定义处理函数,并传入这个$对象
func && type func === 'function' && func($);
});
});
}
// 函数分装完了,我们就要调用它了
getData("http://lol.duowan.com/hero/", $ => {
// 定义一个数组,用来存放没个英雄的详情页面的url
let urlArr = [];
// 通过html中的特定结构选择英雄的a链接,循环并取出其href
// 有人可能就问了,这个特定结构我怎么知道呢?你问对了,打开那个url,右键审查元素就可以了
$("#champion_list li a").each((index, val) => {
urlArr.push($(val).attr("href"));
});
// 最后我们再对这个英雄详情链接数组进行遍历,获取每个英雄的详细信息
urlArr.forEach(item => {
// 继续调用我们封装的方法
getData(item, $h => {
// 这里呢,我们通过它网站详情页面的dom结构呢,获取英雄的一些属性信息
let hero = {};
// 英雄的昵称(称号)
hero.title = $h(".hero-intro__bd .hero-title").text();
// 英雄的姓名
hero.name = $h(".hero-intro__bd .hero-name").text();
// 英雄的定位(因为定位可能有多个,所以是个数组)
hero.position = [];
// 处理英雄定位(还是根据他的dom结构解析就可以了)
$h(".hero-intro__bd .hero-position span.hero-tag").each((index, val) => {
hero.position.push($h(val).text());
});
// 英雄的能力(包括多种能力,所以是个对象)
hero.ability = {};
// 英雄能力的数组
let arr = ["life", "physicalAttack", "magicAttack", "difficulty"];
// 遍历dom结构获取相应的英雄能力
$h(".hero-intro__bd .hero-ability span.hero-attribute em i").each((index, val) => {
// 这里呢因为它网站上把英雄的能力数值直接给以css的样式显示出来了,所以我们要获取其样式进行解析
let w = $h(val).attr("style");
hero.ability[arr[index]] = w.replace(/^width:(\d)\d%$/ig, "$1");
});
// 输出一个提示
log("一个英雄数据获取完毕!");
// 开始插入数据库了(SQL语句大家应该都会写,我们就不过多阐述了)
con.query("insert into hero(title, name, position, life, physical_attack, magic_attack, difficulty, create_time) values(?, ?, ?, ?, ?, ?, ?, now())", [
hero.title,
hero.name,
hero.position.join(","),
hero.ability["life"],
hero.ability["physicalAttack"],
hero.ability["magicAttack"],
hero.ability["difficulty"]
], function(err) {
// 这里呢,插入很可能出错,所以还是要走个形式判断一下嘛(虽然可能性基本为0只要数据库能连接上)
if (err) {
// 输出错误
log(err);
} else {
// 到这里,一条英雄的数据就插入成功了
log("一条英雄数据插入完毕!");
}
});
});
});
});
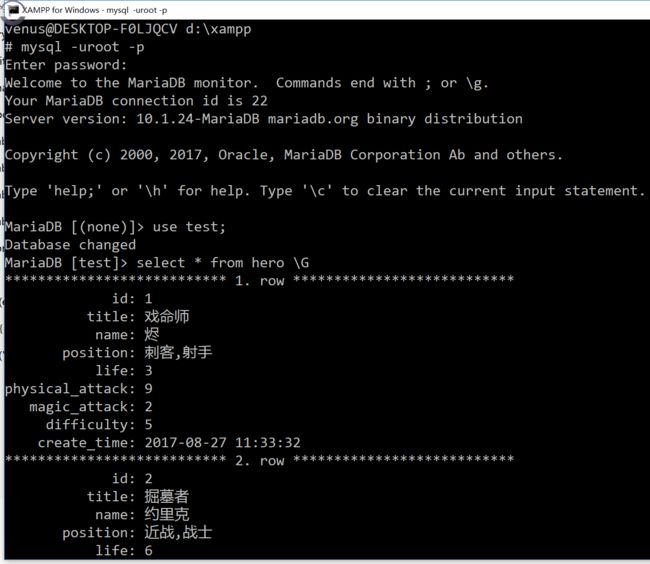
最后爬完之后呢,就可以在数据命令行界面(图形化工具当然更好啦)查询一下,看下效果了:
1503819587841284.png
有什么问题欢迎评论,我如果看到了,会尽我所学为你解答!