hi,大家好,最近生活越来越单一,突然一瞬间觉得要做些什么事情,本来就想着好好工作,却发现到处是壁垒,其实归结起来还是积累不够,不善于总结导致的结果,未来若干年,我们可能期望遇到问题时,能给一个合理的解决方法。时至今日,我每天都是不断的在忙碌,忙碌,忙碌...,却又不知道在忙碌什么,所以希望在此记录总结下,以方便日后用到时,能够快速用到。相当于大脑的一个备份吧。
本位主要讲解mybatis代码分析,mybatis是一个orm框架,目前主流的持久化框架有哪些
| 框架名 | 优势 | 劣势 |
|---|---|---|
| hibernate | 提供了丰富API,高度封装 | 底层sql自动生成,很难优化 |
| myabtis | 自己编写sql,可优化,可遵循相同的规范,代码可自动生成 | |
| springjdbc | 对原生jdbc封装,高度灵活 | 很多代码需要手写 |
封装性太强,就不容易解耦,不能解耦,就会受限于框架本身,就不足够灵活。太灵活,又会影响开发效率,需要手写太多的代码。都有各自的优劣势,需要自己根据场景来选择
下文是一片关于jdbc、springjdbc、mybatis性能比较的文章
http://blog.sina.com.cn/s/blog_539d361e0100z15p.html
mybatis源码环境
gitHub地址:https://github.com/mybatis/mybatis-3.git
建议大家去fork,这样可以自己方便调试并提交。也方便记录。
架构图如下(不知道为啥引用不了图片连接):
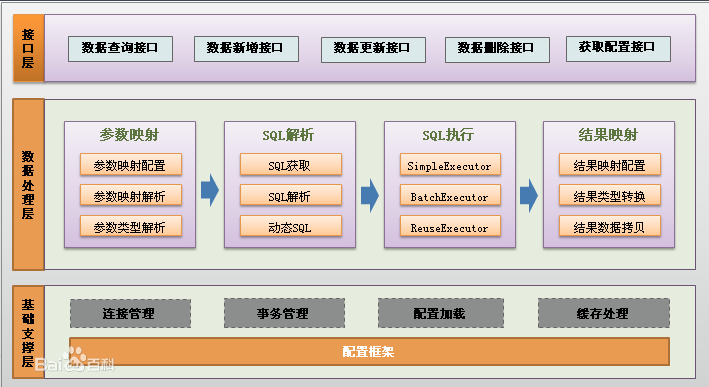
其中基础支撑层的配置框架模块应该包含了我们常用的日志模块、资源加载、反射模块、类型转换、解析器模块。
fork下来整个代码块结构如下:

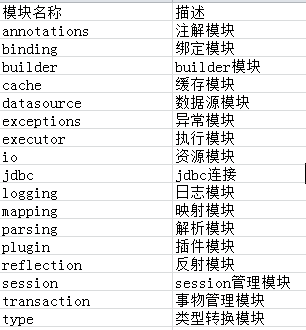
我们该如何入手呢,根据开发流程,首先接触的xml配置,当然是先从xml配置解析入手了。进而一步步看它是如何运作的。看前面那黑洞洞,定是那贼巢穴,待俺前去,杀他个干干净净。
xml解析
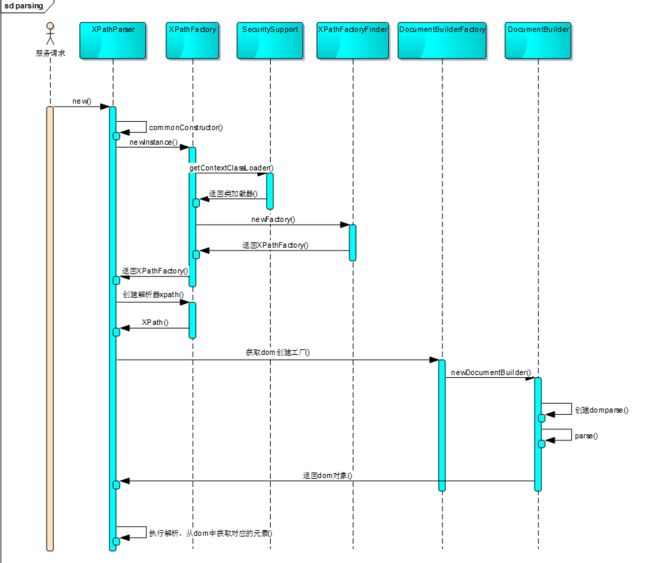
mybatis3.0 xml解析底层是通过DOM、XPath来实现的,其解析时序图如下:
XPath
XPath是一种查询xml文档的语言,就好比SQL语言查询数据库,通常XPath与DOM进行结合使用,XPath通过执行表达式来获取xml中的元素。
XPath对应的表达式常用如下:
| nodename | 选取此节点的所有子节点 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
eg:
//zolfxpathparse_test.xml
杨梅
1
袋
10.00
10.00
脆谷乐
1
盒
20.00
20.00
对上面代码进行解析:
public class ZolfXPathParseTest {
@Test
public void testXmlPath(){
try {
//创建document 文档构建器
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
//构建document文档
Document document = builder.parse("D:\\mybatis3\\src\\test\\java\\resources\\zolfxpathparse_test.xml");
//创建解析构建器
XPathFactory xPathFactory = XPathFactory.newInstance();
//构建解析器
XPath xPath = xPathFactory.newXPath();
//解析表达式
XPathExpression expr = xPath.compile("//product[name='杨梅']/price/text()");
//执行解析
Object obj = expr.evaluate(document, XPathConstants.NODESET);
NodeList nodes = (NodeList)obj;
for(int i=0;i通过上面代码我们可以知道XPath其实就是从xml中获取所需的元素的。对xml的构建dom树的过程是DocumentBuilder实现的。
XPathParser.java
mybatis中主要通过XPathParser来进行解析。其代码如下:
private final Document document;//domcument对象
private boolean validation;//是否开启验证,
private EntityResolver entityResolver;//用于加载本地DTD文件
private Properties variables;//mybatis-config.xml中属性集合
private XPath xpath;//上文序列图中XPath对象
对应的解析时:
提供了evalString、evalLong、evalBooleal、evalInteger等解析方法。
//XPathParser.java
public String evalString(Object root, String expression) {
String result = (String) evaluate(expression, root, XPathConstants.STRING);
result = PropertyParser.parse(result, variables);
return result;
}
他们都调用了evaluate方法
//XPathParser.java
private Object evaluate(String expression, Object root, QName returnType) {
try {
return xpath.evaluate(expression, root, returnType);
} catch (Exception e) {
throw new BuilderException("Error evaluating XPath. Cause: " + e, e);
}
}
PropertyParser.java

eg:下面代码解析
Properties props = new Properties();
props.setProperty(PropertyParser.KEY_ENABLE_DEFAULT_VALUE, "true");
props.setProperty("key", "value");
props.setProperty("tableName", "members");
props.setProperty("orderColumn", "member_id");
props.setProperty("a:b", "c");//冒号是默认分隔符,冒号后面代表默认值
PropertyParser.parse("SELECT * FROM ${tableName:users} ORDER BY ${orderColumn:id}", props)
//ProperyParser.java
public static String parse(String string, Properties variables) {
//占位符处理器
VariableTokenHandler handler = new VariableTokenHandler(variables);
//占位符解析器
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
return parser.parse(string);
}
//GenericTokenParser.java
public String parse(String text) {
if (text == null || text.isEmpty()) {
return "";
}
// 搜索占位符起始位置
int start = text.indexOf(openToken, 0);
if (start == -1) {
return text;
}
//占位符转字节
char[] src = text.toCharArray();
int offset = 0;
final StringBuilder builder = new StringBuilder();
//占位符的值 eg:value:aaa
StringBuilder expression = null;
while (start > -1) {
if (start > 0 && src[start - 1] == '\\') {
// 如果是开始转义字符,则直接将前面字符串添加到builder.
builder.append(src, offset, start - offset - 1).append(openToken);
offset = start + openToken.length();
} else {
// 搜索占位符结束位置
if (expression == null) {
expression = new StringBuilder();
} else {
expression.setLength(0);
}
builder.append(src, offset, start - offset);
offset = start + openToken.length();
int end = text.indexOf(closeToken, offset);
while (end > -1) {
if (end > offset && src[end - 1] == '\\') {
//如果是转义结束字符,则继续
expression.append(src, offset, end - offset - 1).append(closeToken);
offset = end + closeToken.length();
end = text.indexOf(closeToken, offset);
} else {
expression.append(src, offset, end - offset);
offset = end + closeToken.length();
break;
}
}
if (end == -1) {
builder.append(src, start, src.length - start);
offset = src.length;
} else {
//将expression值交给TokenHandler处理,并将处理结果添加到builer中 builder.append(handler.handleToken(expression.toString()));
offset = end + closeToken.length();
}
}
start = text.indexOf(openToken, offset);
}
if (offset < src.length) {
builder.append(src, offset, src.length - offset);
}
return builder.toString();
}
代码调试信息如下:

TokenHandler主要从properties对象中获取expression的值,如果没有则返回默认值
