一、简介
retry是一个用于错误处理的模块,功能类似try-except,但更加快捷方便,本文就将简单地介绍一下retry的基本用法。
二、基本用法
retry:
作为装饰器进行使用,不传入参数时功能如下例所示:
from retry import retry @retry() def demo(): print('错误') raise demo()
我们编写了每次运行都会通过raise报错的自定义函数demo(),利用默认参数的retry()进行装饰,运行结果如下:

可以看到,retry()在这里的功能,是在其装饰的函数运行报错后重新运行该函数,在上例中的效果就是反复运行demo(),这也是retry()的基本用法,下面介绍其几个主要参数:
exceptions:传入指定的错误类型,默认为Exception,即捕获所有类型的错误,也可传入元组形式的多种指定错误类型
tries:定义捕获错误之后重复运行次数,默认为-1,即为无数次
delay:定义每次重复运行之间的停顿时长,单位秒,默认为0,即无停顿
backoff:呈指数增长的每次重复运行之间的停顿时长,需要配合delay来使用,譬如delay设置为3,backoff设置为2,则第一次间隔为3*2**0=1秒,第二次3*2**1=2秒,第三次3*2**2=4秒,以此类推,默认为1
max_delay:定义backoff和delay配合下出现的等待时间上限,当delay*backoff**n大于max_delay时,等待间隔固定为该值而不再增长
下面我们通过几个直观的例子来更加深刻地认识上述参数:
import time from retry import retry '''记录初始时刻''' start_time = time.clock() @retry(delay=1,tries=4,backoff=2) def demo(start_time): '''将当前时刻与初始时刻的时间差(单位:S)作差并四舍五入''' print(round(time.clock()-start_time,0)) raise demo(start_time)
在上例中,我们设置delay为1,tries为4,backoff为2,通过我们的自定义函数来记录每次重复运行与初始时刻的时间差,这样第一次与第二次间隔时间为1*2**0=1,第二次与第三次间隔为1*2**1=2,第三次与第四次间隔4,运行结果如下,到达预定的运行状况后程序就会报错从而终止运行:
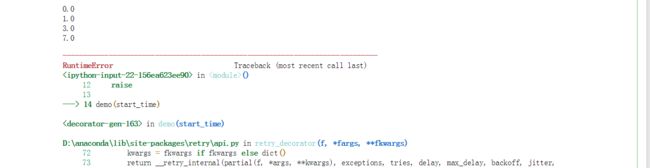
符合我们上面的计算结果,下面我们设置一个较小的max_delay:
import time from retry import retry '''记录初始时刻''' start_time = time.clock() @retry(delay=1,tries=10,backoff=2,max_delay=20) def demo(start_time): '''将当前时刻与初始时刻的时间差(单位:S)作差并四舍五入''' print(round(time.clock()-start_time,0)) raise demo(start_time)
运行结果如下:
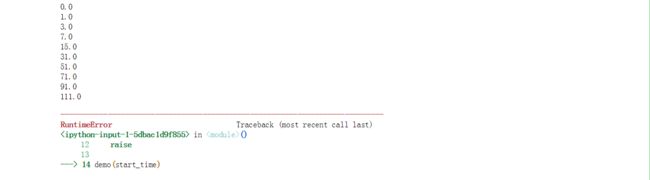
可以看到,在delay和backoff共同控制下的间隔时长超过20秒后,之后的每一次间隔时长都固定为20秒,直到所有的tries运行结束。
利用retry,我们可以在譬如网络爬虫过程中更加简洁灵活地控制错误处理过程,使得代码具有更好的可读性,以上就是本文的基本内容,如有笔误,望指出。