spark经典之单词统计
准备数据
既然要统计单词我们就需要一个包含一定数量的文本,我们这里选择了英文原著《GoneWithTheWind》(《飘》)的文本来做一个数据统计,看看文章中各个单词出现频次如何。为了便于大家下载文本。可以到GitHub上下载文本以及对应的代码。我将文本放在项目的目录下。
首先我们要读取该文件,就要用到SparkContext中的textFile的方法,我们尝试先读取第一行。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
println(sc.textFile("./GoneWithTheWind").first())
}
}
java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
public class WordCountJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("WordCountJava");
JavaSparkContext sc = new JavaSparkContext(conf);
System.out.println(sc.textFile("./GoneWithTheWind").first());
}
}
python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("HelloWorld")
sc = SparkContext(conf=conf)
print(sc.textFile("./GoneWithTheWind").first())
得到输出
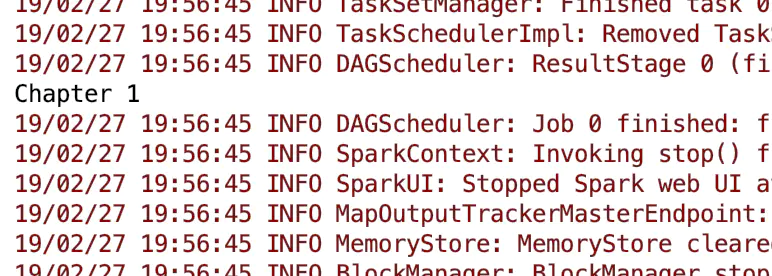
Chapter 1
以scala为例,其余两种语言也差不多。第一步我们创建了一个SparkConf
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
这里我们设置Master为local,该程序名称为WordCount,当然程序名称可以任意取,和类名不同也无妨。但是这个Master则不能乱写,当我们在集群上运行,用spark-submit的时候,则要注意。我们现在只讨论本地的写法,因此,这里只写local。
接着一句我们创建了一个SparkContext,这是spark的核心,我们将conf配置传入初始化
val sc = new SparkContext(conf)
最后我们将文本路径告诉SparkContext,然后输出第一行内容
println(sc.textFile("./GoneWithTheWind").first())
开始统计
接着我们就可以开始统计文本的单词数了,因为单词是以空格划分,所以我们可以把空格作为单词的标记。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
//设置数据路径
val text = sc.textFile("./GoneWithTheWind")
//将文本数据按行处理,每行按空格拆成一个数组
// flatMap会将各个数组中元素合成一个大的集合
val textSplit = text.flatMap(line =>line.split(" "))
//处理合并后的集合中的元素,每个元素的值为1,返回一个元组(key,value)
//其中key为单词,value这里是1,即该单词出现一次
val textSplitFlag = textSplit.map(word => (word,1))
//reduceByKey会将textSplitFlag中的key相同的放在一起处理
//传入的(x,y)中,x是上一次统计后的value,y是本次单词中的value,即每一次是x+1
val countWord = textSplitFlag.reduceByKey((x,y)=>x+y)
//将计算后的结果存在项目目录下的result目录中
countWord.saveAsTextFile("./result") } } java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class WordCountJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("WordCountJava");
JavaSparkContext sc = new JavaSparkContext(conf);
//设置数据的路径
JavaRDD textRDD = sc.textFile("./GoneWithTheWind");
//将文本数据按行处理,每行按空格拆成一个数组,flatMap会将各个数组中元素合成一个大的集合
//这里需要注意的是FlatMapFunction中,第一个表示输入,第二个表示输出
//与Hadoop中的map-reduce非常相似
JavaRDD splitRDD = textRDD.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator(); } }); //处理合并后的集合中的元素,每个元素的值为1,返回一个Tuple2,Tuple2表示两个元素的元组 //值得注意的是上面是JavaRDD,这里是JavaPairRDD,在返回的是元组时需要注意这个区别 //PairFunction中,第一个String是输入值类型 //第二第三个,String, Integer是返回值类型 //这里返回的是一个word和一个数值1,表示这个单词出现一次 JavaPairRDD splitFlagRDD = splitRDD.mapToPair(new PairFunction() { @Override public Tuple2 call(String s) throws Exception { return new Tuple2<>(s,1); } }); //reduceByKey会将splitFlagRDD中的key相同的放在一起处理 //传入的(x,y)中,x是上一次统计后的value,y是本次单词中的value,即每一次是x+1 JavaPairRDD countRDD = splitFlagRDD.reduceByKey(new Function2() { @Override public Integer call(Integer integer, Integer integer2) throws Exception { return integer+integer2; } }); //将计算后的结果存在项目目录下的result目录中 countRDD.saveAsTextFile("./resultJava"); } } python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("HelloWorld")
sc = SparkContext(conf=conf)
# 设置数据的路径
textData = sc.textFile("./GoneWithTheWind")
# 将文本数据按行处理,每行按空格拆成一个数组,flatMap会将各个数组中元素合成一个大的集合 splitData = textData.flatMap(lambda line:line.split(" ")) # 处理合并后的集合中的元素,每个元素的值为1,返回一个元组(key,value) # 其中key为单词,value这里是1,即该单词出现一次 flagData = splitData.map(lambda word:(word,1)) # reduceByKey会将textSplitFlag中的key相同的放在一起处理 # 传入的(x,y)中,x是上一次统计后的value,y是本次单词中的value,即每一次是x+1 countData = flagData.reduceByKey(lambda x,y:x+y) #输出文件 countData.saveAsTextFile("./result") 运行后在住目录下得到一个名为result的目录,该目录如下图,SUCCESS表示生成文件成功,文件内容存储在part-00000中

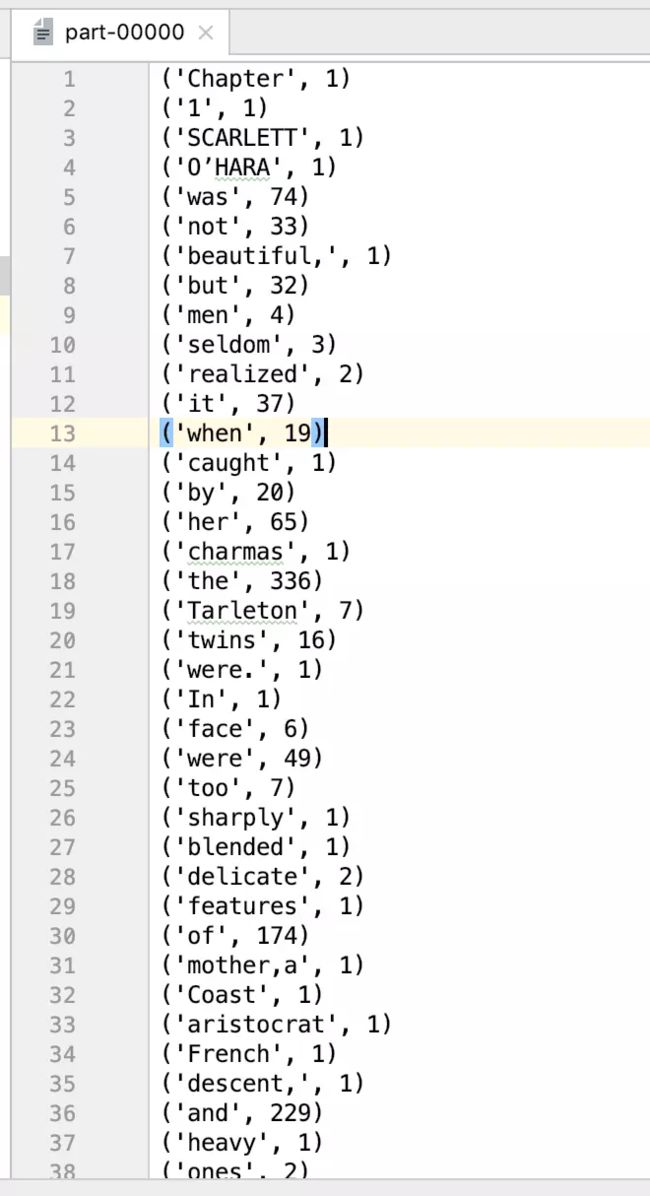
我们可以查看文件的部分内容:
('Chapter', 1)
('1', 1)
('SCARLETT', 1)
('O’HARA', 1)
('was', 74) ('not', 33) ('beautiful,', 1) ('but', 32) ('men', 4) ('seldom', 3) ('realized', 2) ('it', 37) ('when', 19) ('caught', 1) ('by', 20) ('her', 65) ('charmas', 1) ('the', 336) ('Tarleton', 7) ('twins', 16) ('were.', 1) ('In', 1) ('face', 6) ('were', 49) ... ... ... ...
这样就完成了一个spark的真正HelloWorld程序--单词计数。对比三个语言版本的程序,发现一个事实那就是,用scala和python写的代码非常简洁而且易懂,而Java实现的则相对复杂,难懂。当然这个易懂和难懂是相对而言的。如果你只会Java无论如何你都应该从中能看懂java的程序,而简洁的scala和python对你来说根本看不懂。这也无妨,语言只是工具,重点看你怎么用。况且,我们使用java8的特性也可以写出简洁的代码。
java8实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class WordCountJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("WordCountJava");
JavaSparkContext sc = new JavaSparkContext(conf);
countJava8(sc);
}
public static void countJava8(JavaSparkContext sc){
sc.textFile("./GoneWithTheWind")
.flatMap(s->Arrays.asList(s.split(" ")).iterator())
.mapToPair(s->new Tuple2<>(s,1))
.reduceByKey((x,y)->x+y)
.saveAsTextFile("./resultJava8"); } } spark的优越性在这个小小的程序中已经有所体现,计算一本书的每个单词出现的次数,spark在单机上运行(读取文件、生成临时文件、将结果写到硬盘),加载-运行-结束只花费了2秒时间。
对程序进行优化
程序是否还能再简单高效呢?当然是可以的,我们可以用countByValue这个函数,这个函数正是常用的计数的方法。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
//设置数据路径
val text = sc.textFile("./GoneWithTheWind")
//将文本数据按行处理,每行按空格拆成一个数组
// flatMap会将各个数组中元素合成一个大的集合
val textSplit = text.flatMap(line =>line.split(" "))
println(textSplit.countByValue())
}
}
运行得到结果
Map(Heknew -> 1, “Ashley -> 1, “Let’s -> 1, anarresting -> 1, of. -> 1, pasture -> 1, war’s -> 1, wall. -> 1, looks -> 2, ain’t -> 7,.......

java实现
public class WordCountJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("WordCountJava");
JavaSparkContext sc = new JavaSparkContext(conf);
countJava(sc);
}
public static void countJava(JavaSparkContext sc){
//设置数据的路径
JavaRDD textRDD = sc.textFile("./GoneWithTheWind");
//将文本数据按行处理,每行按空格拆成一个数组,flatMap会将各个数组中元素合成一个大的集合
//这里需要注意的是FlatMapFunction中,第一个表示输入,第二个表示输出
//与Hadoop中的map-reduce非常相似
JavaRDD splitRDD = textRDD.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator(); } }); System.out.println(splitRDD.countByValue()); } } 运行得到结果
{Heknew=1, “Ashley=1, “Let’s=1, anarresting=1, of.=1, pasture=1, war’s=1, wall.=1, looks=2, ain’t=7, Clayton=1, approval.=1, ideas=1,
python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("HelloWorld")
sc = SparkContext(conf=conf)
# 设置数据的路径
textData = sc.textFile("./GoneWithTheWind")
# 将文本数据按行处理,每行按空格拆成一个数组,flatMap会将各个数组中元素合成一个大的集合 splitData = textData.flatMap(lambda line:line.split(" ")) print(splitData.countByValue()) 运行得到结果:
defaultdict('int'>, {'Chapter': 1, '1': 1, 'SCARLETT': 1, 'O’HARA': 1, 'was': 74, 'not': 33, 'beautiful,': 1, 'but': 32, 'men': 4,
转自:https://juejin.im/post/5c768f5b6fb9a049b348a811