Scala语法
至于scala语法而言,大致上和Java的语法类似,增加了一些函数式编程,具体语法可以参考Scala语法
Scala是一种针对 JVM 将函数和面向对象技术组合在一起的编程语言。Scala编程语言近来抓住了很多开发者的眼球。它看起来像是一种纯粹的面向对象编程语言,而又无缝地结合了命令式和函数式的编程风格。
Scala也是一种函数式语言,其函数也能当成值来使用。
Scala被特意设计成能够与Java和.NET互操作。它用scalac这个编译器把源文件编译成Java的class文件(即在JVM上运行的字节码)。你可以从Scala中调用所有的Java类库,也同样可以从Java应用程序中调用Scala的代码。
-
数据类型

- 变量
基于变量的数据类型,操作系统会进行内存分配并且决定什么将被储存在保留内存中。因此,通过给变量分配不同的数据类型,你可以在这些变量中存储整数,小数或者字母。
在 Scala 中,使用关键词 "var" 声明变量,使用关键词 "val" 声明常量(不能修改)。
var myVar : String = "Foo"
val myVar : String = "Too"
在 Scala 中声明变量和常量不一定要指明数据类型,在没有指明数据类型的情况下,其数据类型是通过变量或常量的初始值推断出来的。
所以,如果在没有指明数据类型的情况下声明变量或常量必须要给出其初始值,否则将会报错。
var myVar = 10;
val myVal = "Hello, Scala!";
- Scala 访问修饰符
私有(Private)成员
用 private 关键字修饰,带有此标记的成员仅在包含了成员定义的类或对象内部可见,同样的规则还适用内部类。
保护(Protected)成员
在 scala 中,对保护(Protected)成员的访问比 java 更严格一些。因为它只允许保护成员在定义了该成员的的类的子类中被访问。而在java中,用protected关键字修饰的成员,除了定义了该成员的类的子类可以访问,同一个包里的其他类也可以进行访问。
公共(Public)成员
Scala中,如果没有指定任何的修饰符,则默认为 public。这样的成员在任何地方都可以被访问。 - 输入输出
输出和C语言差不多,用print()即可。输入用readLine函数从控制台读取一行输入。如果要读取数字,Boolean或者是字符,你可以用readInt,readDouble,readByte等
val name =readLine("Your name:")
print("Your age:")
val age=readInt()
printf("Hello,%s! you are %d years old \n",name,age)
- 循环
是Scala 中没有i++,i--操作。
A for (i <- 1 to (10)) {
println("Number is :" + i)
}
B for (ch<-"Hello")
{
println(ch)
}
C for (i<-0 to 10 ;form=10-i)println(form)
D for(i<-0 to 10 if i%2=0) println(form)
E for(i<-0 until (b.length,2)){//跳步0,2,4,6.。。。。
val t= b(i)
b(i)=b(i+1)
b(i+1)=t
}
- 数组
数组分为可变和不可变长度
#不可变长度
val nums=new Array[Int](10)
val s = Array("Hello", "World")
s(0) = "Goodbye"
#可变长度
import scala.collection.mutable.ArrayBuffer
val b= ArrayBuffer[Int]()
b+=1 //添加元素+=在尾端添加
b+=(1,2,34,5,6)
b.trimEnd(5) //尾端删除5个元素
b.insert(2, 6)
b.insert(2, 7, 8, 9)
b.remove(2)
b.remove(2, 3)
b.toArray
- 其它操作和Java类似,使用时查API即可。
安装Scala
- Java 设置
确保你本地以及安装了 JDK 1.5 以上版本,并且设置了 JAVA_HOME 环境变量及 JDK 的bin目录。 - 安装Scala
从官网下载Scala 安装包,解压安装:
tar zxvf scala-2.11.7.tgz
设置Scala环境变量设置
SCALA_HOME=/opt/scala-2.11.7
PATH=$PATH:$SCALA_HOME/bin
export SCALA_HOME PATH
Scala 已正常安装。
安装Spark
由于用的cloudera Hadoop发行版,所以直接添加即可。使用Apache Hadoop可以看这里。
输入spark-shell启动Spark的时候报错



- 测试SparkPi
在spark的bin目录下输入./run-example SparkPi 10(迭代次数)计算PI的值。
第一次运行的时候报错说找不到main class,检查发现没有配置JAVA_HOME,所以用命令echo $JAVA_HOME检查一下是否配置好了。
然后就可以正确运行了,并得到结果。
- 测试wordcount
当程序一旦打包好,就可以使用bin/spark-submit脚本启动应用了. 这个脚本负责设置spark使用的classpath和依赖,支持不同类型的集群管理器和发布模式:
./bin/spark-submit \
--class
--master \
--deploy-mode \
--conf = \
... # other options
\
[application-arguments]
--class: 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)
--master: 集群的master URL (如 spark://23.195.26.187:7077)
--deploy-mode: 是否发布你的驱动到worker节点(cluster) 或者作为一个本地客户端 (client) (default: client)*
--conf: 任意的Spark配置属性, 格式key=value. 如果值包含空格,可以加引号“key=value”.
application-jar: 打包好的应用jar,包含依赖. 这个URL在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path都包含同样的jar.
application-arguments: 传给main()方法的参数
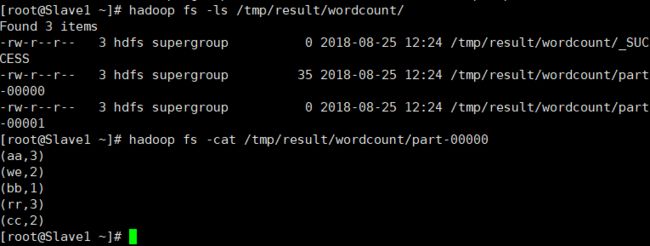
使用命令./spark-submit --class testSpark.WordCount --master yarn-cluster /usr/tmp/WordCount.jar /tmp/input/words.txt /tmp/result/wordcount/使用集群模式运行jar包,并指明了主类和输入输出
第一次执行的时候报错了,但是只是说

查看日志找到具体错误,输入的文件地址错了。


Spark Shell
spark shell 是spark自带的一个快速原型开发的工具,在spark目录下面的bin目录下面。把这个理解为在python交互界面下写python代码就行了。
写一个wordcount
-
load数据集

sc是在进入spark shell 时候创建一个spark content 就是spark上下文的意思,val 是scala语法中声明常量的方式(val 定义的值实际上是一个常量,如果你试图改变他的值,解析器会报错,声明值或变量但不做初始化也会报错。),通过println可以看到读入的文件被处理成一个MappedRDD的对象。这个sc.textFile的操作就把的数据load到内存中了。
- 调用flatMap方法计算wordCount
val wordCounts = textFile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey((a,b)=>a+b) - 由于Scala语言的特性,此时wordCounts还不是执行计算后的值,还只是定义着计算的方法,需要用collect()来执行这个计算。

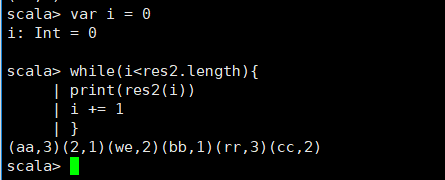
res2表示得到的结果,是一个Array类型的,如果要取出每一个值,可以用Scala的循环。
配置Spark应该程序开发、运行环境
在开发Spark程序的时候,总是先在本地进行开发,所以就需要spark的开发环境,等调试程序确保无误的时候再把程序打包到本地Spark运行,所以这就需要在本地配置Spark的运行环境。最后再把jar包提交到分布式环境运行。(当然,如果你不想在本地测试jar包而直接拿到集群上去跑可以不配置本地spark,但是后面需要spark/lib文件里的一些jar包,需单独下载)
- 配置JDK1.8
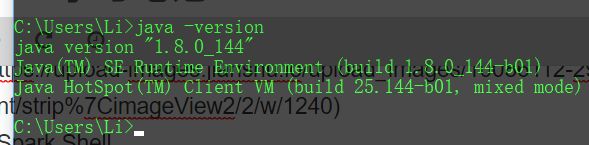
这个需要配置JAVA_HOME,PATH,CLASSPATH。这个相信大多数的都已经配置了的,至于每个环境变量的具体的作用可以看这里。配置完成后验证一下是否成功,当看到Java信息就成功了。
- Scala的安装
首先从DOWNLOAD PREVIOUS VERSIONS下载到对应的版本,在这里需要注意的是,Spark的各个版本需要跟相应的Scala版本对应,比如我这里使用的Spark 1.6.0,Scala使用的 2.10.6版本。记得下载二进制版本的Scala。

安装完后默认是自动将bin配置到了path环境变量,可以验证一下是否自动配置了。

- Spark的安装
park的安装非常简单,直接去Download Apache Spark。有两个步骤:
选择好对应Hadoop版本的Spark版本,如下图中所示;
然后点击spark-1.6.2-bin-hadoop2.6.tgz,等待下载结束即可。
下载完成后将文件进行解压(可能需要解压两次),最好解压到一个盘的根目录下,并重命名为Spark,简单不易出错。并且需要注意的是,在Spark的文件目录路径名中,不要出现空格,类似于“Program Files”这样的文件夹名是不被允许的。
然后就是配置环境变量,把\Spark\bin加入path。
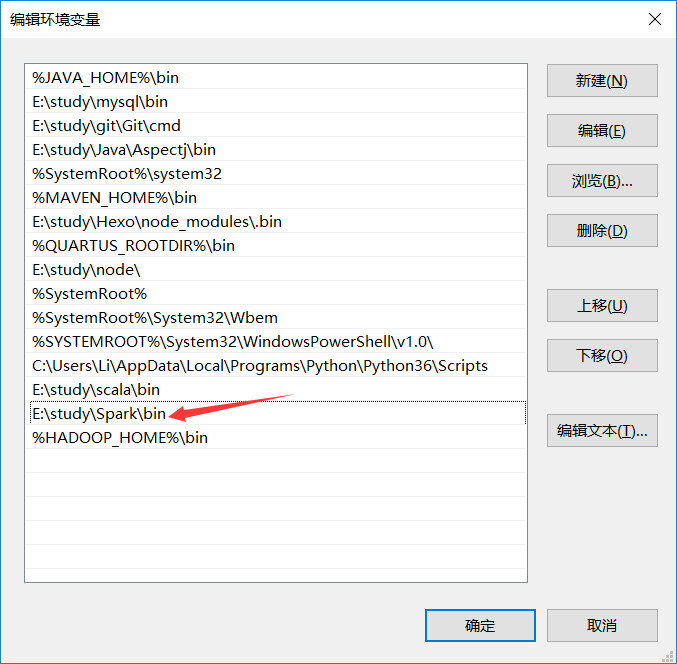
- Hadoop安装
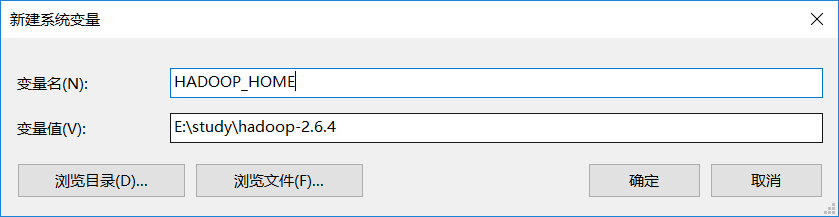
系统变量设置后,就可以在任意当前目录下的cmd中运行spark-shell,但这个时候很有可能会碰到各种错误,这里主要是因为Spark是基于Hadoop的,所以这里也有必要配置一个Hadoop的运行环境。在Hadoop Releases里可以看到Hadoop的各个历史版本,这里由于下载的Spark是基于Hadoop 2.6的(在Spark安装的第一个步骤中,我们选择的是Pre-built for Hadoop 2.6),我这里选择2.6.4版本,选择好相应版本并点击后,进入详细的下载页面,并下载’hadoop-2.6.4.tar.gz’文件
下载并解压到指定目录,然后到环境变量部分设置HADOOP_HOME为Hadoop的解压目录,然后把它下面的bin目录页加入path

然后再cmd下启动spark,报错如下
主要是因为Hadoop的bin目录下没有winutils.exe文件的原因造成的。这里的解决办法是:
- 去 https://github.com/steveloughran/winutils 选择你安装的Hadoop版本号,然后进入到bin目录下,找到
winutils.exe文件,下载方法是点击winutils.exe文件,进入之后在页面的右上方部分有一个Download按钮,点击下载即可。 - 下载好
winutils.exe后,将这个文件放入到Hadoop的bin目录下,我这里是E:\study\hadoop-2.6.4\bin。 - 在打开的cmd中输入
E:\study\hadoop-2.6.4\bin\winutils.exe chmod 777 /tmp/hive这个操作是用来修改权限的。注意前面的F:\Program Files\hadoop\bin部分要对应的替换成实际你所安装的bin目录所在位置。
经过这几个步骤之后,然后再次开启一个新的cmd窗口,如果正常的话,应该就可以通过直接输入spark-shell来运行Spark了。
看到这两句话就说明成功了
Spark context available as sc.
SQL context available as sqlContext.
配置集成开发环境IDEA
配置前提
- JDK安装。 请自行前往oracle官方网站下载安装,并在command命令行窗口确认java -version 可以返回版本号,否则的话要去系统环境变量设置位置确认是否java已经被添加到PATH中
- Scala下载安装。移步官网 http://www.scala-lang.org/ 下载并安装即可。同第1步,要在command命令行下确认敲击scala可以进入交互式命令窗口,否则请确认环境变量的配置。
- spark源代码下载。官方网站 http://spark.apache.org/downloads.html 上提供有各种hadoop版本的预编译版spark代码,理论上要根据你在用的hadoop版本来相应选择,本文仅作配置说明,故任选其中一即可。笔者下载的是spark1.5, 对应hadoop2.6预编译的版本,解压即可。
- Intellij IDEA下载。https://www.jetbrains.com/idea/ 上可以下载免费的community版本。
配置开始
- 安装IDEA 的scala插件
第一次安装时,在plugins处输入scala关键词搜索,在联网环境下点击安装即可。

然后就可以看到下载进度
完了之后记得重启,不然还是不能用 -
创建项目并导入相应依赖包
直接在新建项目界面选择scala项目即可
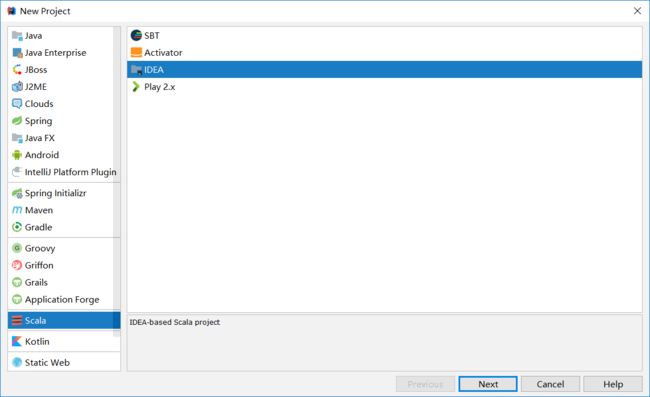
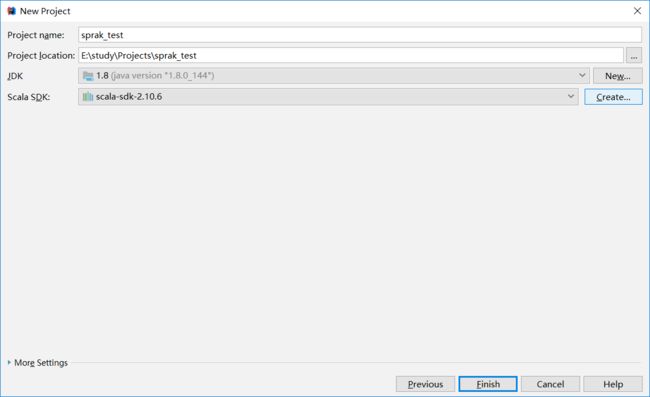
Project SDK是java的jdk,如果没有默认加载出来,点击New,手工定位到jdk的目录提交上来即可。Scala SDK那里如果默认没有加载出来,点击Create,在弹出的窗口中安默认勾选的System点击OK即可。便可以看到项目结构了。
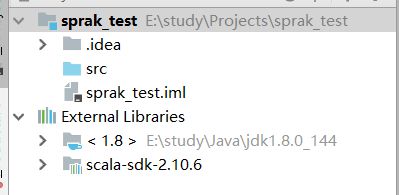
接下来,我们导入上面下载好的spark源码。按下图指引操作, 在+号处选择java, 然后定位到你上面步骤中将spark程序解压到的目录位置,选择lib目录下的spark-assembly-1.5.0-hadoop2.6.0.jar文件,确认。
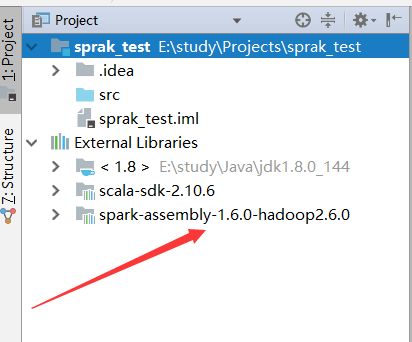
当看到项目外部包里面出现了刚刚导入的包就行了。
程序开发
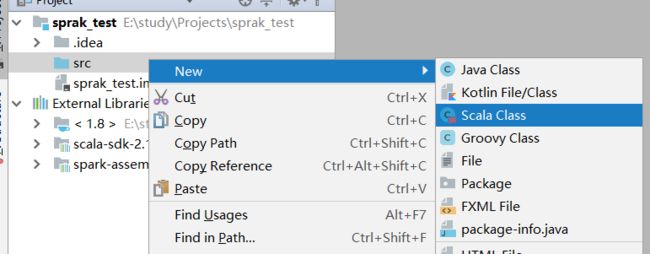
创建scala class,类型选择object(如果右键没有Scala class选项是因为没有把src目录作为你的Sources文件夹属性,右键src有个选项把它设置为Sources文件夹即可,也可以去项)。
写一个分布式的wordcount(如果想写本地spark的话就不用RDD,像以前那样写代码即可)
import org.apache.spark.SparkConf //使用spark的相关操作
import org.apache.spark.SparkContext //获取SparkContext上下文对象
object MyTest {
def main(args: Array[String]){
if (args.length != 2 || args(0) == null || args(1) == null){ //查看传如参数是否为2且不为空
System.exit(1);
}
val conf = new SparkConf() //获取spark环境的配置,用于传如上下文
val sc = new SparkContext(conf)
val line = sc.textFile(args(0))
//wordcount的算法,用flatMap实现
val result = line.flatMap(_.split("[^a-zA-Z]+")).map((_, 1)).reduceByKey(_+_)
result.saveAsTextFile(args(1)) //保存结果到指定文件夹
sc.stop() //关闭上下文对象
}
}
最后配置编译生成的jar包名字和地址。(这里项目名字spark写成sprak了。。。)
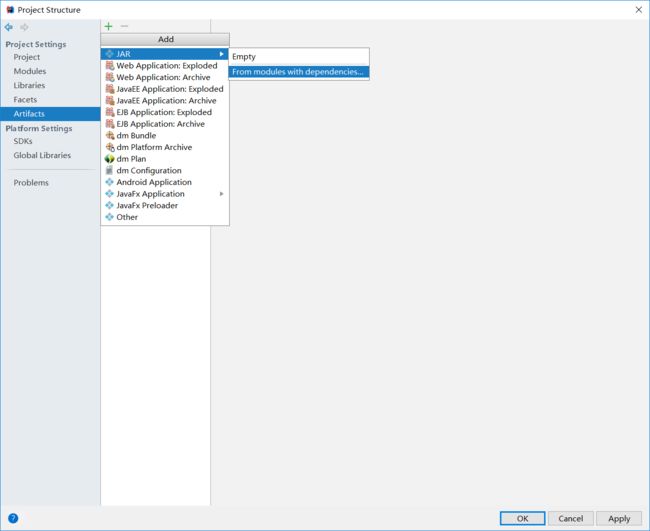
进入到如图的项目管理界面,选择图中的目录,打包时的main class选择你的主类,我这里是MyTest

然后就编译可以输出你的包了。build -> build artifacts -> spark_dev:jar -> build, 然后就开始编译了,在最下面可以看到进行的状态。到输出JAR包的目录下去看看,发现确实成功生成了一个jar文件。(此处打好的jar包如果要提交到数平的Spark集群上运行,请打开此jar包文件,观察其中是否有一个scala的文件夹,删除了!否则可能与线上的scala版本冲突,不冲突可不删除)
这里可能会报错java.lang.outofmemoryerror

配置jar包output选项,因为运行环境中已经有相关包,所以其他包删除,只保留’compile output’那一项,这时再build就不会内存溢出。
本地测试代码
在cmd中输入命令
>spark-submit --class MyTest --master local E:\study\Projects\sprak_test\out\artifacts\sprak_test_jar\sprak_test.jar E:\words.txt E:\out
表示把刚刚的jar包提交到spark执行,local本地模式,输入文件和输入路径。最后得到结果:
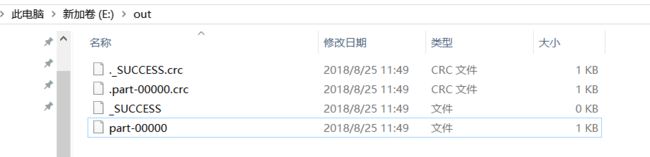

编写spark程序
以下内容基于spark1.6.0
spark程序可以用Java、python和scala编写,由于spark本身是由scala编写,再加上scala的语法特定决定了scala是编写spark程序的最合适的语言。
基本概念
- RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
- DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系;
- Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据;
- 应用:用户编写的Spark应用程序;
- 任务:运行在Executor上的工作单元;
- 作业:一个作业包含多个RDD及作用于相应RDD上的各种操作;
- 阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”。
架构设计
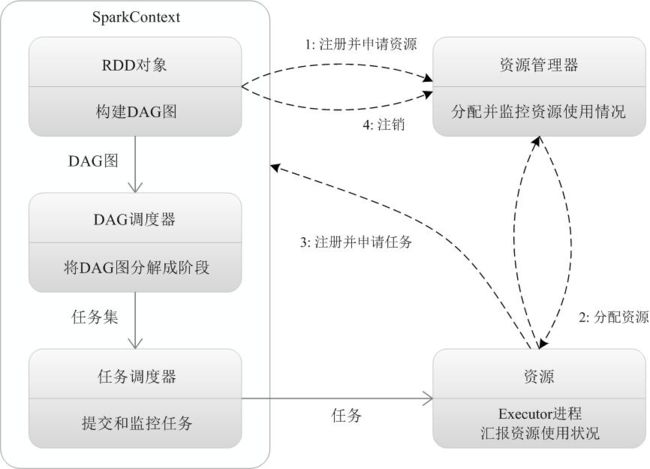
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。

Spark运行基本流程
(1)当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源;
(2)资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上;
(3)SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;
(4)任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
RDD
- RDD(弹性数据集)是Spark提供的最重要的
抽象的概念,它是一种有容错机制的特殊集合,可
以分布在集群的节点上,以函数式编操作集合的方
式,进行各种并行操作。 - 可以将RDD理解为一个具有容错机制的特殊集合,
它提供了一种只读、只能有已存在的RDD变换而来
的共享内存,然后将所有数据都加载到内存中,方
便进行多次重用。
获取RDD
- 从共享的文件系统(HDFS)
- 通过已存在的RDD转换
- 将已存在scala集合(只要是Seq对象)并行化 ,通过调用SparkContext的parallelize方法实现。
- 改变现有RDD的持久性;RDD是懒散,短暂的。
RDD的固化:cache缓存至内存;
save保存到分布式文件系统
操作RDD
- Transformation:根据数据集创建一个新的数据
集,计算后返回一个新RDD;例如:Map将数据
的每个元素经过某个函数计算后,返回一个新的分
布式数据集。
常见的Transformation操作有map、filter、flatMap、sort等等。 - Actions:对数据集计算后返回一个数值value给
驱动程序;例如:Reduce将数据集的所有元素用
某个函数聚合后,将最终结果返回给程序。
常见的Actions操作有count、collect等等。在此阶段才发生真正的计算
举个例子:
val a = sc.parallelize(1 to 9, 3)
scala> val b = a.map(_*2)
scala> a.collect
res10: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> b.collect
res11: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18)
此段代码的意思:
- 先调用SparkContext的parallelize方法将一个list并行化,获得RDD。
- 然后调用RDD上的map操作,使此RDD上元素乘2,返回一个新的RDD b。
- 接着对a、b这个RDD调用collect操作,返回Array对象。
- 其中SparkContext表示spark程序执行的上下文,即又spark的环境得到的。
其它的transformation和actions操作在具体运用的时候学习
Spark程序的三种运行模式
Local模式
该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上有没有问题。
其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。
- spark-submit 和 spark-submit --master local 效果是一样的
- (同理:spark-shell 和 spark-shell --master local 效果是一样的)
- spark-submit --master local[4] 代表会有4个线程(每个线程一个core)来并发执行应用程序。
Spark On Yarn模式
在Spark中,有Yarn-Client和Yarn-Cluster两种模式可以运行在Yarn上,通常Yarn-Cluster适用于生产环境,而Yarn-Clientr更适用于交互,调试模式。
优势
- Spark支持资源动态共享,运行于Yarn的框架都共享一个集中配置好的资源池
- 可以很方便的利用Yarn的资源调度特性来做分类·,隔离以及优先级控制负载,拥有更灵活的调度策略
- Yarn可以自由地选择executor数量
- Yarn是唯一支持Spark安全的集群管理器,使用Yarn,Spark可以运行于Kerberized Hadoop之上,在它们进程之间进行安全认证
此模式分为yarn-client和yarn-cluster
Yarn-cluster模式下作业执行流程:
- 客户端生成作业信息提交给ResourceManager(RM)
- RM在某一个NodeManager(由Yarn决定)启动container并将Application Master(AM)分配给该NodeManager(NM)
- NM接收到RM的分配,启动Application Master并初始化作业,此时这个NM就称为Driver
- Application向RM申请资源,分配资源同时通知其他NodeManager启动相应的Executor
- Executor向NM上的Application Master注册汇报并完成相应的任务
Yarn-client模式下作业执行流程:
- 客户端生成作业信息提交给ResourceManager(RM)
- RM在本地NodeManager启动container并将Application Master(AM)分配给该NodeManager(NM)
- NM接收到RM的分配,启动Application Master并初始化作业,此时这个NM就称为Driver
- Application向RM申请资源,分配资源同时通知其他NodeManager启动相应的Executor
- Executor向本地启动的Application Master注册汇报并完成相应的任务
分布式模式查看程序执行情况
把刚刚写好的wordcount的jar包sprak_test.jar提交到分布式的环境中去,并分别选择yarn-cluster和yarn-client运行模式,用相应的方法查看执行情况。(用户切换为hdfs)
-
yarn-client
首先执行命令hdfs dfs -rm -r /tmp/result/wordcount/删除输出路径,不然会报错。进入到spark的bin目录,然后还是和以前一样填写输出输出运行,只是运行模式改为yarn-client。
spark-submit --class MyTest --master yarn-client /usr/tmp/sprak_test.jar /tmp/input/words.txt /tmp/result/wordcount/
对于yarn-client模式的运行情况,会直接打印到终端。
也可以通过APP Name在端口18088查看情况

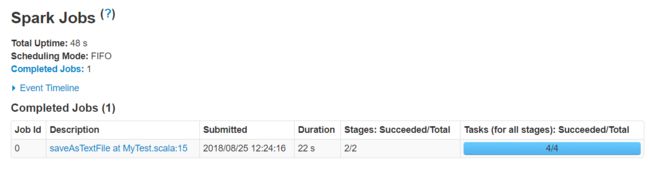
只是这个任务太快了,不能在webUi看到运行的过程。其结果如下:

-
yarn-cluster
首先执行命令hdfs dfs -rm -r /tmp/result/wordcount/删除输出路径,不然会报错。进入到spark的bin目录,然后还是和以前一样填写输出输出运行,只是运行模式改为yarn-cluster。
spark-submit --class MyTest --master yarn-cluster/usr/tmp/sprak_test.jar /tmp/input/words.txt /tmp/result/wordcount/
也是去18088端口查看信息(运行太快看不到信息)
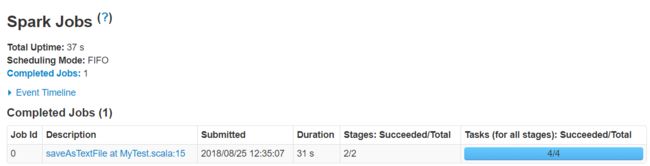

如果要查看详细情况,还可以点stdout查看具体运行日志
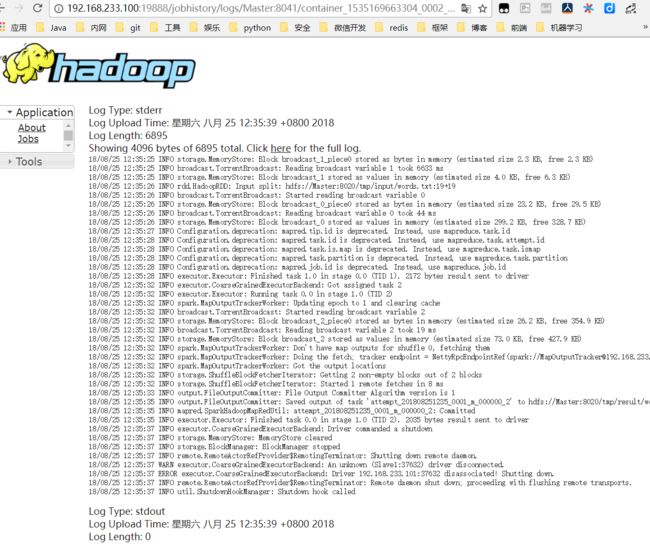
结果如下: