目录
- LinkedList 源码学习
- LinkedList继承体系
- LinkedList核心源码
- Deque相关操作
- 总结
LinkedList 源码学习
前文传送门:Java小白集合源码的学习系列:ArrayList
本篇为集合源码学习系列的LinkedList学习部分,如有叙述不当之处,还望评论区批评指正!
LinkedList继承体系

LinkedList和ArrayList一样,都实现了List接口,都代表着列表结构,都有着类似的add,remove,clear等操作。与ArrayList不同的是,LinkedList底层基于双向链表,允许不连续地址的存储,通过节点之间的相互引用建立联系,通过节点存储数据。
LinkedList核心源码
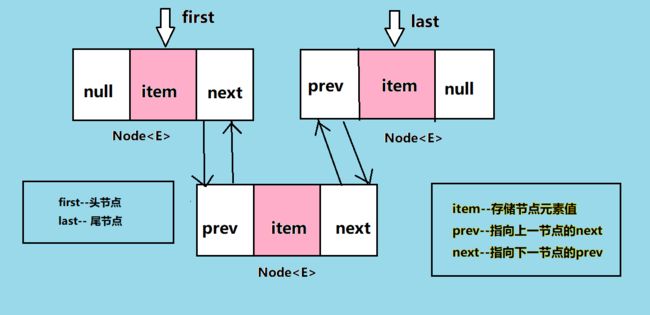
既然是基于节点的,那么我们来看看节点在LinkedList中是怎样的存在:
//Node作为LinkedList的静态内部类
private static class Node {
E item;//节点存储的元素值
Node next;//后向指针
Node prev;//前向指针
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 我们发现,Node作为其内部类,拥有三个属性,一个是用来指向前一节点的指针prev,一个是指向后一节点的指针next,还有存储的元素值item。
我们来看看LinkedList的几个基本属性:
/*用transient关键字标记的成员变量不参与序列化过程*/
transient int size = 0;//记录节点个数
/**
* first是指向第一个节点的指针。永远只有下面两种情况:
* 1、链表为空,此时first和last同时为空。
* 2、链表不为空,此时第一个节点不为空,第一个节点的prev指针指向空
*/
transient Node first;
/**
* last是指向最后一个节点的指针,同样地,也只有两种情况:
* 1、链表为空,first和last同时为空
* 2、链表不为空,此时最后一个节点不为空,其next指向空
*/
transient Node last;
//需要注意的是,当first和last指向同一节点时,表明链表中只有一个节点。 了解基本属性之后,我们看看它的构造方法,由于不必在乎它存储的位置,它的构造器也是相当简单的:
//创建一个空链表
public LinkedList() {
}
//创建一个链表,包含指定传入的所有元素,这些元素按照迭代顺序排列
public LinkedList(Collection c) {
this();
//添加操作
addAll(c);
}其中addAll(c)其实调用了addAll(size,c),由于这里size=0,所以相当于从头开始一一添加。至于addAll方法,我们暂时不提,当我们总结完普通的添加操作,也就自然明了这个全部添加的操作。
//把e作为链表的第一个元素
private void linkFirst(E e) {
//建立临时节点指向first
final Node f = first;
//创建存储e的新节点,prev指向null,next指向临时节点
final Node newNode = new Node<>(null, e, f);
//这时newNode变成了第一个节点,将first指向它
first = newNode;
//对原来的first,也就是现在的临时节点f进行判断
if (f == null)
//原来的first为null,说明原来没有节点,现在的newNode
//是唯一的节点,所以让last也只想newNode
last = newNode;
else
//原来链表不为空,让原来头节点的prev指向newNode
f.prev = newNode;
//节点数量加一
size++;
//对列表进行改动,modCount计数加一
modCount++;
} 相应的,把元素作为链表的最后一个元素添加和第一个元素添加方法类似,就不赘述了。我们来看看我们一开始遇到的addAll操作,感觉有一点点麻烦的哦:
//在指定位置把另一个集合中的所有元素按照迭代顺序添加进来,如果发生改变,返回true
public boolean addAll(int index, Collection c) {
//范围判断
checkPositionIndex(index);
//将集合转换为数组,果传入集合为null,会出现空指针异常
Object[] a = c.toArray();
//传入集合元素个数为0,没有改变原集合,返回false
int numNew = a.length;
if (numNew == 0)
return false;
//创建两个临时节点,暂时表示新表的头和尾
Node pred, succ;
//相当于从原集合的尾部添加
if (index == size) {
//暂时让succ置空
succ = null;
//让pred指向原集合的最后一个节点
pred = last;
} else {
//如果从中间插入,则让succ指向指定索引位置上的节点
succ = node(index);
//让succ的prev指向pred
pred = succ.prev;
}
//增强for循环遍历赋值
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
//创建存储值尾e的新节点,前向指针指向pred,后向指针指向null
Node newNode = new Node<>(pred, e, null);
//表明原链表为空,此时让first指向新节点
if (pred == null);
first = newNode;
else
//原链表不为空,就让临时节点pred节点向后移动
pred.next = newNode;
//更新新表的头节点为当前新创建的节点
pred = newNode;
}
//这种情况出现在原链表后面插入
if (succ == null) {
//此时pred就是最终链表的last
last = pred;
} else {
//在index处插入的情况
//由于succ是node(index)的临时节点,pred因为遍历也到了插入链表的最后一个节点
//让最后位置的pred和succ建立联系
pred.next = succ;
succ.prev = pred;
}
//新长度为原长+增长
size += numNew;
modCount++;
return true;
} - 注意:遍历赋值的过程相当于从pred这个临时节点开始,依次向后创建新节点,并将pred向后移动,直到新传入集合的最后一个元素,这时再将pred和succ两个建立联系,实现无缝链接。
再来看看,在链表中普通删除元素的操作是怎么样的:
//取消一个非空节点x的连结,并返回它
E unlink(Node x) {
//同样的,在调用这个方法之前,需要确保x不为空
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
//明确x与上一节点的联系,更新并删除无用联系
//x为头节点
if (prev == null) {
//让first指向x.next的临时节点next,宣布从下一节点开始才是头
first = next;
} else {
//x不是头节点的情况
//让x.prev的临时节点prev的next指向x.next的临时节点
prev.next = next;
//删除x的前向引用,即让x.prev置空
x.prev = null;
}
//明确x与下一节点的联系,更新并删除无用联系
//x为尾节点
if (next == null) {
//让last指向x.prev的临时节点prev,宣布上一节点是最后的尾
last = prev;
} else {
//x不是尾节点的情况
//让x.next的临时节点next的prev指向x.prev的临时节点
next.prev = prev;
//删除x的后向引用,让x.next置空
x.next = null;
}
//让x存储元素置空,等待GC宠信
x.item = null;
size--;
modCount++;
return element;
} 总结来说,删除操作无非就是,消除该节点与另外两个节点的联系,并让与它相邻的两个节点之间建立联系。如果考虑边界条件的话,比如为头节点和尾节点的情况,需要再另加分析。总之,它不需要向ArrayList一样,拷贝数组,而是改变节点间的地址引用。但是,删除之前需要找到这个节点,我们还是需要遍历滴,就像下面这样:
//移除第一次出现的元素o,找到并移除返回true,否则false
public boolean remove(Object o) {
//传入元素本身就为null
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {
//调用上面提到的取消节点连结的方法
unlink(x);
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
//删除的元素不为null,比较值的大小
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
} 总结一下从前向后遍历的过程:
- 创建一个临时节点指向first。
- 向后遍历,让临时节点指向它的下一位。
- 直到临时节点指向last的下一位(即x==null)为止。
当然特殊情况特殊考虑,上面的remove方法目的是找到对应的元素,只需要在循环中加入相应的逻辑判断即可。下面这个相当重要的辅助方法就是通过遍历获取指定位置上的节点:有了这个方法,我们就可以同过它的前后位置,推导出其他不同的方法:
//获得指定位置上的非空节点
Node node(int index) {
//在调用这个方法之前会确保0<=inedx>1比较,如果index比size的一半小,从前向后遍历
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
//退出循环的条件,i==indx,此时x为当前节点
return x;
} else {
//从后向前遍历
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} 与此同时还有indexOf和lastIndexOf方法也是通过上面总结的遍历过程,加上计数条件,计算出指定元素第一次或者最后一次出现的索引,这里以indexOf为例:
//返回元素第一次出现的位置,没找到就返回-1
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
} 其实就是我们上面讲的遍历操作嘛,大差不差。有了这个方法,我们还是可以很轻松地推导出另外的contains方法。
public boolean contains(Object o) {
return indexOf(o) != -1;
}然后还是那对基佬方法:get和set。
//获取元素值
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//用新值替换旧值,返回旧值
public E set(int index, E element) {
checkElementIndex(index);
//获取节点
Node x = node(index);
//存取旧值
E oldVal = x.item;
//替换旧值
x.item = element;
//返回旧值
return oldVal;
} 接下来是我们的clear方法,移除所有的元素,将表置空。虽然写法有所不同,但是基本思想是不变的:创建节点,并移动,删除不要的,或者找到需要的,就行了。
public void clear() {
for (Node x = first; x != null; ) {
//创建临时节点指向当前节点的下一位
Node next = x.next;
//下面就可以安心地把当前节点有关的全部清除
x.item = null;
x.next = null;
x.prev = null;
//x向后移动
x = next;
}
//回到最初的起点
first = last = null;
size = 0;
modCount++;
} Deque相关操作
我们还知道,LinkedList还继承了Deque接口,让我们能够操作队列一样操作它,下面是截取不完全的一些方法:
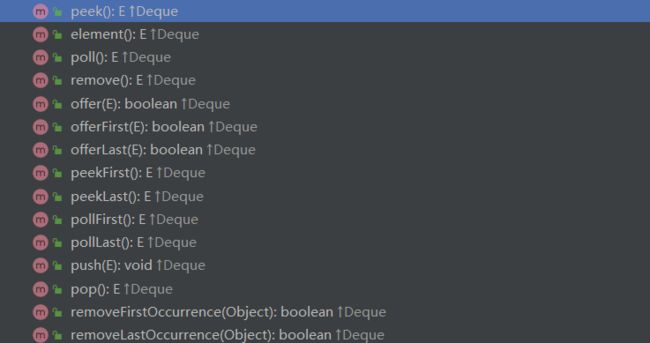
我们从中挑选几个分析一下,几个具有迷惑性方法的差异,比如下面这四个:
public E element() {
return getFirst();
}
public E getFirst() {
final Node f = first;
//如果头节点为空,抛出异常
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E peek() {
final Node f = first;
return (f == null) ? null : f.item;
}
public E peekFirst() {
final Node f = first;
return (f == null) ? null : f.item;
} - element:调用getFirst方法,如果头节点为空,抛出异常。
- getFirst:如果头节点为空,抛出异常。
- peek:头节点为空,返回null。
- peekFirst:头节点为空,返回null。
与之类似的还有:
- pollFirst和pollLast方法删除头和尾节点,如果为空,返回null。
- removeFirst和removeFirst如果为空,抛异常。
如果有兴趣的话,可以研究一下,总之还是相对简单的。
总结
而LinkedList底层基于双向链表实现,不需要连续的内存存储,通过节点之间相互引用地址形成联系。
对于无索引位置的插入来说,例如向后插入,时间复杂度近似为O(1),体现出增删操作较快。但是如果要在指定的位置上插入,还是需要移动到当前指定索引位置,才可以进行操作,时间复杂度近似为O(n)。
Linkedlist不支持快速随机访问,查询较慢。
线程不安全,同样的,关于线程方面,以后学习时再进行总结。