统计学习的基本概念(复习篇)
-
总体(population):根据研究目的确定的同类对象的全体(集合) 样本(sample):从总体中随机抽取的部分具有代表性的研究对象。
-
参数(Parameter):反映总体特征的统计指标,如总体均数、标准差等,是固定的常量。
-
统计量(statistic):反映样本特征的统计指标,如样本均数、标准差等,是在参数附近波动的随机变量。
-
统计资料分布(statistical distribution):定量(计量)资料、定性(计数)资料、等级资料。
计量资料统计描述:
- 集中趋势:均数(mean)、中位数(median)、众数(mode)。
- 离散趋势:极差(range)、四分位间距(interquartile range)、标准差(standard deviation)(或方差(variance))、变异系数(variable coefficient)。
注:四分位数(Quartile)是统计学中分位数的一种,即把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值就是四分位数。第三四分位数与第一四分位数的差距又称四分位距(InterQuartile Range, IQR)。
在概率论和统计学中,变异系数,又称“离散系数”(英文:coefficient of variation),是概率分布离散程度的一个归一化量度,其定义为标准差与平均值之比
二项分布(Bionomial Distribution):
-
说起二项分布(binomial distribution),不得不提的前提是伯努利试验(Bernoulli experiment),也即n次独立重复试验。伯努利试验是在同样的条件下重复、相互独立进行的一种随机试验。
伯努利试验的特点是:
(1)每次试验中事件只有两种结果:事件发生或者不发生,如硬币正面或反面,患病或没患病;
(2)每次试验中事件发生的概率是相同的,注意不一定是0.5;
(3)n次试验的事件相互之间独立。
举个实例,最简单的抛硬币试验就是伯努利试验,在一次试验中硬币要么正面朝上,要么反面朝上,每次正面朝上的概率都一样p=0.5,且每次抛硬币的事件相互独立,即每次正面朝上的概率不受其他试验的影响。如果独立重复抛n=10次硬币,正面朝上的次数k可能为0,1,2,3,4,5,6,7,8,9,10中的任何一个,那么k显然是一个随机变量,这里就称随机变量k服从二项分布。
n次抛硬币中恰好出现k次的概率为:P(X=k) = C(n,k) * pk*(1-p)n-k
这就是二项分布的分布律,记作X~B(n,p),其中C(n,k)是组合数,在数学中也叫二项式系数,这就是二项分布名称的来历。判断某个随机变量X是否符合二项分布除了满足上述的伯努利试验外,关键是这个X是否表示事件发生的次数。二项分布的数学期望E(X)=np,方差D(X)=np*(1-p)。
泊松分布(poisson distribution)
泊松分布描述的是一个离散随机事件在单位时间内发生的次数, 其对应的场景是我们统计已知单位事件内发生某事件的平均次数λ, 那么我们在一个单位事件内发生k次的概率是多大呢?
比如说医院产房里统计历史数据可知, 平均每小时出生3个宝宝,那么在接下来的一个小时内, 出生 0 个宝宝, 1 个宝宝, …, 3 个宝宝, …10 个宝宝, n 个宝宝的概率分别是多少呢? 泊松分布给出了定量的结果 :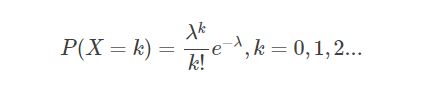
其中 P(X=k) 描述的就是在单位时间内事件 X发生 k次的概率, λ代表在单位时间内事件发生的平均次数, 也就是泊松分布的期望, 同时也是方差.
一个场景可以用泊松分布来描述, 需要满足三个条件:
-
-
均值稳定. 即 λ在任意划定的单位时间长度内,应该是一个稳定的数值.
-
事件独立. 事件之间相互独立, 若相关, 则泊松分布失效.
-
在一个极小的时间内, 事件发生的次数应趋近于0. 比如说:产房平均 1 小时出生 3 个宝宝, 那我任意指定1ms, 那这1ms 内出生的宝宝数趋近于 0 .
-
大数定理(Law of large numbers)
设随机变量$X_1,X_2,X_3,...,X_n$是一列互相独立的随机变量(或者两两不相关),并且分别存在期望$E(X_k)$,则对于任意小的正数ε有: $$ \lim_{x→∞}P(|\frac{1}{n}\sum_{k=1}^nX_k-\frac{1}{n}\sum_{k=1}^nE(X_k)|<ε) $$ 理解:随着样本数量n的增加,样本的平均数(总体中的一部分)将接近于总体样本的平均数,所以在统计推断中一般使用样本平均数估计总体平均数的值。
下面我们用简单的python代码来客观展现出大数定理:
import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt # 防止中文乱码 mpl.rcParams['font.sans-serif']=[u'simHei'] mpl.rcParams['axes.unicode_minus']=False # 定义数据量大小 numberSize = 200 # 生成服从正态分布的随机数据,其均值为0 randData = np.random.normal(scale=100, size=numberSize) # 保存随机每增加一个数据后算出来的均值 randData_average = [] # 保存每增加一个数据后的数据和 randData_sum = 0 # 通过循环计算每增加一个数据后的均值 for index in range(len(randData)): randData_average.append((randData[index] + randData_sum) / (index + 1.0)) # 定义作图的x值和y值 x = np.arange(0,numberSize,1) y = randData_average # 作图设置 plt.title('大数定律') plt.xlabel('数据量') plt.ylabel('平均值') # 作图并展示 plt.plot(x,y) plt.plot([0,numberSize], [0,0], 'r') plt.show()
结果如下:

由上图即可进一步验证我们的结论,随着数据量的增加,均值越来越接近实际均值0。
即当我们的样本数据量足够大的时候,我们就可以用样本的平均值来估计总体平均值。
- 正态分布(Normal distribution):正态分布又叫高斯分布,若随机变量$X$服从一个数学期望为μ、方差为σ2的正态分布,记为N(μ,σ2):(这个我单写过一章学习)
其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布