在自然语言处理技术里,分词是重要的一环。而搜索引擎,Ai,等技术也都需要分词这一环。
开源的分词软件有Jieba, 许多项目使用它进行分词,可以自定义词库。对中文,英文等语言都可以进行分词。还有个专门针对日文的分词软件MeCab。
这里对Jieba和腾讯云, 百度云NLP都测试了下。理论上腾讯云和百度云分词会比Jieba默认词库分词的更好!因为他们数据多,训练的词库会更加精确。可是百度云的分词爆出历史遗留Bug了
Jieba分词
安装
pip install jieba
代码
# -*-coding:utf-8-*-
import jieba
import jieba.analyse
text = "中國運動會中国运动会䁋,人生苦短,我用Python"
seg_list = jieba.cut(text, cut_all=True)
print("Cur all全模式: {}".format("/ ".join(seg_list)))
seg_list = jieba.cut(text, cut_all=False)
print("Cur all精准: {}".format("/ ".join(seg_list)))
seg_list = jieba.cut_for_search(text)
print("Search模式: {}".format("/ ".join(seg_list)))
Result
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.680 seconds.
Prefix dict has been built succesfully.
Cur all全模式: 中/ 國/ 運/ 動/ 會/ 中国/ 国运/ 运动/ 运动会/ / / / 人生/ 苦短/ / / 我/ 用/ Python
Cur all精准: 中國/ 運動會/ 中国/ 运动会/ 䁋/ ,/ 人生/ 苦短/ ,/ 我用/ Python
Search模式: 中國/ 運動會/ 中国/ 运动/ 运动会/ 䁋/ ,/ 人生/ 苦短/ ,/ 我用/ Python
腾讯云NLP之分词
腾讯云产品网页上没有提供体验,所以只能自己写代码调用体验
# -*- coding: utf-8 -*-
import json
from tencentcloud.common import credential
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.nlp.v20190408 import nlp_client, models
from account import ACC
cred = credential.Credential(ACC["tc"]["SECRET_ID"], ACC["tc"]["SECRET_KEY"])
client = nlp_client.NlpClient(cred, "ap-guangzhou")
req = models.LexicalAnalysisRequest()
req.text = "中國運動會中国运动会䁋,人生苦短,我用Python"
try:
resp = client.LexicalAnalysis(req)
r = json.loads(resp.to_json_string())
for k, tks in r.items():
for v in tks:
print("{}: {}".format(k, v))
except TencentCloudSDKException as err:
print(err)
Result
PosTokens: {'Word': '中國', 'BeginOffset': 0, 'Pos': 'ns', 'Length': 2}
PosTokens: {'Word': '運動會', 'BeginOffset': 2, 'Pos': 'n', 'Length': 3}
PosTokens: {'Word': '中国', 'BeginOffset': 5, 'Pos': 'ns', 'Length': 2}
PosTokens: {'Word': '运动会', 'BeginOffset': 7, 'Pos': 'n', 'Length': 3}
PosTokens: {'Word': '䁋', 'BeginOffset': 10, 'Pos': 'n', 'Length': 1}
PosTokens: {'Word': ',', 'BeginOffset': 11, 'Pos': 'w', 'Length': 1}
PosTokens: {'Word': '人生苦短', 'BeginOffset': 12, 'Pos': 'n', 'Length': 4}
PosTokens: {'Word': ',', 'BeginOffset': 16, 'Pos': 'w', 'Length': 1}
PosTokens: {'Word': '我', 'BeginOffset': 17, 'Pos': 'r', 'Length': 1}
PosTokens: {'Word': '用', 'BeginOffset': 18, 'Pos': 'p', 'Length': 1}
PosTokens: {'Word': 'Python', 'BeginOffset': 19, 'Pos': 'nx', 'Length': 6}
NerTokens: {'Word': '中國', 'BeginOffset': 0, 'Length': 2, 'Type': 'LOC'}
NerTokens: {'Word': '中国', 'BeginOffset': 5, 'Length': 2, 'Type': 'LOC'}
百度云自然语言处理之分词
百度上有提供体验页面,所以就直接上去测试了,没想到爆出了百度的老Bug。估计百度很多系统使用了非UTF-8编码。
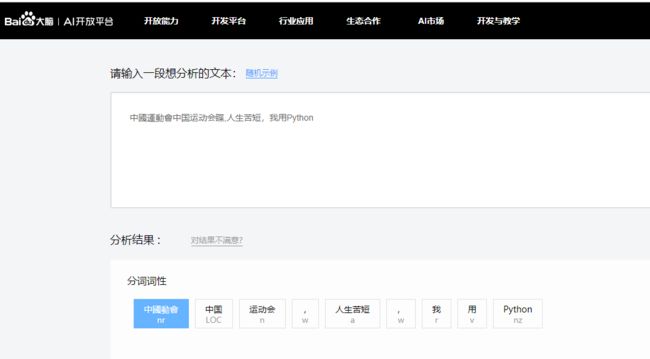
QQ截图20190806165123.png

QQ截图20190806165113.png
结果发现:繁体字“運”字和“䁋”字不见了。如果你使用百度的sdk调用不忽略异常的话,就会抛出异常!
最后
由于阿里云也没有提供网页上的体验,而且他的分词不免费,所以就没法测试了。
百度和腾讯都有自己的搜索引擎,所以他们对中文分词这块有足够的数据支撑!阿里的话也有商城的搜索引擎。其他就不知道了,没空研究!