R语言前身是S语言,S语言是由AT&T Bell实验室的Rick Becker、John Chambers、Allan Wilks开发的一种用于进行数据探索、统计饭呢西、作图的解释性语言。
最初S语言的实现版本主要是S-PLUS,S-PLUS是一个商业软件,基于S语言由MathSoft公司的统计科学部进一步完善。R语言最初由新西兰大学的Ross Ihaka和Robert Gentleman开发。因为R语言是基于S语言的一个GUN项目,所以也可以当作S语言的一种实现,通常使用S语言编写的代码可不不做修改地在R语言环境下运行。
R语言是一套开源的数据分析解决方案,几乎可以独立完成数据处理、数据可视化、数据建模、模型评估等工作,而且可以完美配合其它工具进行数据交互会。具体来说,R语言具有以下优势:
- R语言作为一种GNU项目开放了全部源代码,用户可以免费下载使用和修改。
- R语言可以运行在多种平台上,包括Windows、UNIX、MacOS。
- R语言可以轻松地从各种类型的数据源导入数据,包括文本文件、数据管理系统、统计系统乃至Hadoop、Spark等,同样可以将数据输出并写入这些系统中。
- R语言内置多种统计学及数据分析功能,因为有S的血缘,所以R语言比其它统计学或数学专用的变成语言有更强大的面向对象的功能。
- R语言拥有顶尖的制图能力,不仅包括lattcie包、ggplot2包对复杂数据进行可视化,更有rCharts包、recharts包、plotly包实现数据交互可视化,甚至可以利用功能强大的shiny包实现R与Web整合部署,构建网页应用,帮助不懂CSS、HTML的用户利用R快速搭建自己的数据分析APP应用。
R语言也存在固有的缺点,目前主要问题包括
- R语言是一种解释性语言,和其它编程语言相比,速度略显慢一些。随着硬件和R自身的发展,这个问题已经被慢慢弱化,如果能够熟练运用向量化运算,可大大提高速度,使用R内置的分析函数效率高很多,因为很多函数都是由C或Fortran编写的。
- R所有的计算实际是基于内存进行的,这就意味着在处理数据过程中,数据必须完整地转入内存,这在处理小型数据是没有任何问题的,但遇到大数据时就会变得很严重。但是这个问题也得到了一定的解决,利用并行包提升R的性能,或利用R结合Hadoop进行大数据分析工作。
- 由于R语言的自由各种包的编写者来自不同领域,所以一定程度上比较混乱,没有统一的命名格式,参数格式不一,源代码和文档质量良莠不齐。
下载安装
- 下载地址 https://cran.r-project.org/mirrors.html
- R-3.6.2 Windows版本 https://cloud.r-project.org/bin/windows/base/R-3.6.2-win.exe
- R语言IDE https://rstudio.com/
RStudio
RStudio IDE只能用于R开发,不能用它编写其它语言的程序,但能得到一些R特有的功能。RStudio的好处是可以通过浏览器远程执行,可以现在功能强大的服务器上运行R,然后在手机上远程访问而不会损失计算能力。
Rattle
Rattle是一个用于数据挖掘的R的图形交互界面GUI,可用于快捷处理常见的数据挖掘问题。从数据的整理到模型的评价,Rattle给出了完整的解决方案。Rattle和R平台量好的交互性,为用户使用R语言解决复杂问题开启了方便之门。Rattle易学易用,不要求很多的R语言基础,如今已被广泛地应用于数据挖掘实践和教学之中。
在RStudio中若没有安装rattle包则出现下列错误
> library(rattle)
Error in library(rattle) : 不存在叫‘rattle’这个名字的程辑包
RStudio安装rattle包
> install.packages("RGtk2")
Warning message:
package ‘RGtk2’ is not available (for R version 3.6.2 Patched)
基本原因是此包被移除或者你的网根本打不开下载这个包的URL
在RStudio菜单的Tools>Global Options>Packages中,有一个CRAN mirror选项,没设置过的时候自动选择Global CDN,这是国外的镜像地址,下载速度慢且容易发生上述错误,可以下拉选择China开头的镜像网站,选一个离自己近的就可以。
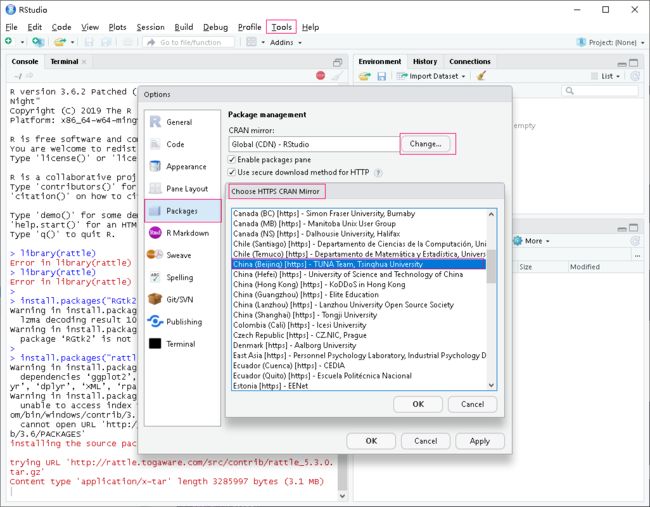
使用biocLite软件对包进行安装
> source("http://bioconductor.org/biocLite.R")
#指定一个离你最近的国内镜像
> options(BioC_mirror="http://mirrors.ustc.edu.cn/bioc/")
> biocLite("包名")
> install.packages("rattle", repos="http://rattle.togaware.com")
> library(rattle)
> rattle()
> install.packages("RGtk2")
trying URL 'https://mirrors.tuna.tsinghua.edu.cn/CRAN/bin/windows/contrib/3.6/RGtk2_2.20.36.zip'
Content type 'application/zip' length 16558916 bytes (15.8 MB)
downloaded 15.8 MB
package ‘RGtk2’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\junchow\AppData\Local\Temp\Rtmp8IyEgQ\downloaded_packages
> install.packages("rattle");
The downloaded binary packages are in
C:\Users\junchow\AppData\Local\Temp\Rtmp8IyEgQ\downloaded_packages
> library(rattle)
Rattle: A free graphical interface for data science with R.
XXXX 5.3.0 Copyright (c) 2006-2018 Togaware Pty Ltd.
键入'rattle()'去轻摇、晃动、翻滚你的数据。
完成Rattle成功后,Rattle的标签栏会集成数据导入、数据探索、数据检验、数据转化、数据建模、模型评估功能。可通过鼠标单击的方式完成一整套数据挖掘工作,并利用Log日志查看每个操作的R脚本实现,借此学习R语言的代码规范及编写。

快速入门
R语言是区分大小写的及时性语言,程序内置的函数可以满足基本的数据分析需求。
例如:在命令行提示符后输入一条指令1+1或一次性执行脚本文件中的一组命令。R语言是解释型语言,输入命令后可以实时响应,类似计算器。如果R检测到输入的命令行未结束,会给出一个提示符+加号,提示需要在下一行继续输入未完的命名,直到语法输入完整为止。不然R会有unexpected end of inport的错误提示。
> 1+
+
> 1+1
[1] 2
标准赋值
R语言的标准赋值符号是<-也可以使用=
例如:将序列1:10赋予给变量a
> a = 1:10
> a
[1] 1 2 3 4 5 6 7 8 9 10
> a<-1:5
> a
[1] 1 2 3 4 5
例如:计算1到5的算数平均数,冒号会创建一个从第一个数字到第二个数字的序列,每个相隔为1,计算得到的序列称为一个矢量。mean是计算算数平均值的函数,括号内的向量被称为函数的参数。
> mean(1:10)
[1] 5.5
help
- 如果想要直到某个函数或数据集的信息可输入一个问号
?加上函数名称 - 如果想查找某个函数可输入两个问号
??后跟函数关键词
例如:查看中位数函数median的帮助文档
> ?median
> help("median")
> ??median
> help.search("median")
其中?median相当于help("median"),??median相当于help.search("median")。

默认情况下,help只能查找已经加载到内存中扩展包的函数和数据。如果想要查找未加载到内存扩展包中的函数和数据,需要指定help函数的package参数所指向的具体包名和将try.all.package参数设置为TRUE。
例如:查找shiny包中的nunExample函数
> help("runExample")
No documentation for ‘runExample’ in specified packages and libraries:
you could try ‘??runExample’
> help("runExample", package="shiny")
Error in find.package(if (is.null(package)) loadedNamespaces() else package, :
there is no package called ‘shiny’
> help("runExample", try.all.packages=TRUE)
No documentation for ‘runExample’ in specified packages and libraries:
you could try ‘??runExample’
> ??runExample
appropos
使用appropos函数可以找出所有名字中含有关键字的函数,只在载入的包中搜索。
> apropos("plot")
[1] ".rs.api.savePlotAsImage"
[2] ".rs.replayNotebookPlots"
[3] "assocplot"
[4] "barplot"
example
大多数函数已经 有相应的例子帮助了解函数的工作原理,可以通过example函数来查看。
> example("median")
median> median(1:4) # = 2.5 [even number]
[1] 2.5
median> median(c(1:3, 100, 1000)) # = 3 [odd, robust]
[1] 3
data
可通过data函数查看datasets包中的数据集
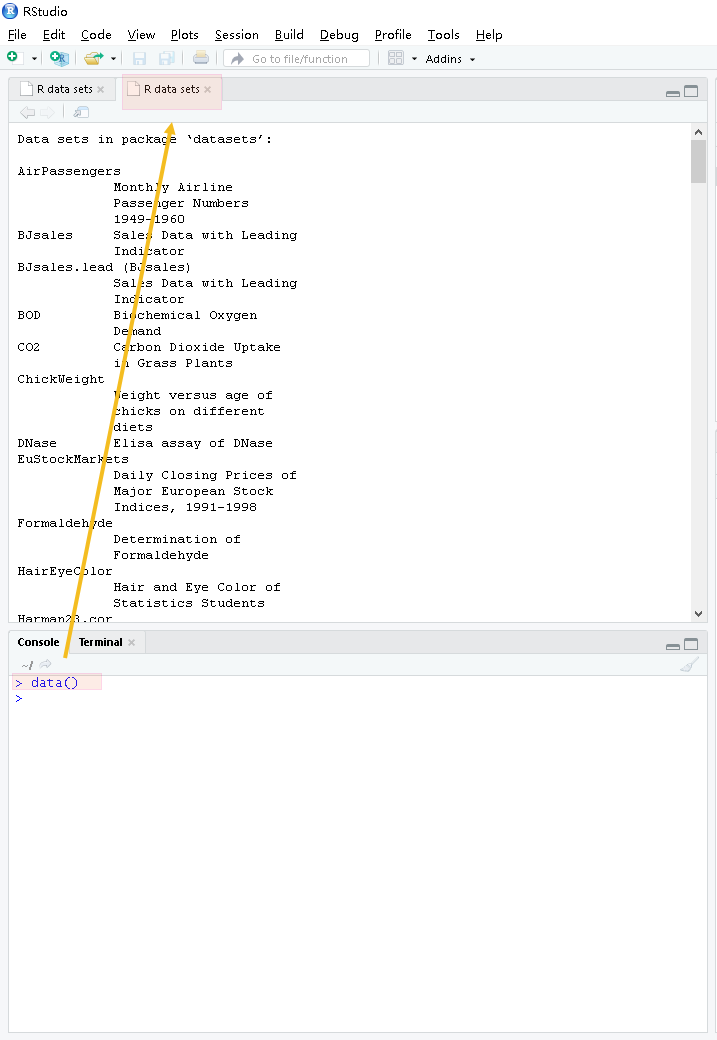
如果要查看本地安装包的所有数据集可使用命令data(package=.packages(all.available=TRUE)进行查看
> data(package=.packages(all.available=TRUE))
Warning messages:
1: In data(package = .packages(all.available = TRUE)) :
數據機从程序包'base'移到了程序包'datasets'
2: In data(package = .packages(all.available = TRUE)) :
數據機从程序包'stats'移到了程序包'datasets'
工作空间
工作空间workspace是当前R的工作环境,存储所有用户定义的对象,诸如向量、矩阵、函数、数据框、列表、模型、图形等。
例如:创建对象后查看当前工作空间下的对象
安装rCharts
> install.packages("devtools")
> library(devtools)
载入需要的程辑包:usethis
> install_github('ramnathv/rCharts')
WARNING: Rtools is required to build R packages, but is not currently installed.
Please download and install Rtools custom from http://cran.r-project.org/bin/windows/Rtools/.
Downloading GitHub repo ramnathv/rCharts@master
ramnathv-rCharts-479a4f9/inst/apps/leaflet_chloropleth/data/regions_gcs.js: truncated gzip input
tar.exe: Error exit delayed from previous errors.
Error: Failed to install 'rCharts' from GitHub:
Does not appear to be an R package (no DESCRIPTION)
In addition: Warning messages:
1: In utils::untar(tarfile, ...) :
‘tar.exe -xf "C:\Users\junchow\AppData\Local\Temp\Rtmp8IyEgQ\file64485266372c.tar.gz" -C "C:/Users/junchow/AppData/Local/Temp/Rtmp8IyEgQ/remotes644847884327"’ returned error code 1
2: In system(cmd, intern = TRUE) :
running command 'tar.exe -tf "C:\Users\junchow\AppData\Local\Temp\Rtmp8IyEgQ\file64485266372c.tar.gz"' had status 1
tidyverse
R包是函数、数据、文档的集合,是对R基础功能的扩展,学会如何使用R包才能真正掌握R语言的精华。tidyverse中的R包有着同样的数据处理与编程理念,他们的设计从根本上是为了协同工作。
安装tidyverse
> install.packages("tidyverse")
使用library函数加载R包
> library(tidyverse)
── Attaching packages ─────────────────────────────────────── tidyverse 1.3.0 ──
tibble 2.1.3 dplyr 0.8.3
tidyr 1.0.0 stringr 1.4.0
readr 1.3.1 forcats 0.4.0
purrr 0.3.3
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
检查更新
> tidyverse_update()
All tidyverse packages up-to-date
数据对象
R语言拥有很多存储数据的对象类型,包括向量、矩阵、数组、数据框、列表。它们在存储数据的类型、创建方式、结构复杂度,以及用于定位和访问其中个别元素的标记等方面有所不同。
数据类型
R语言中的数据类型主要包括数值型(numeric)、逻辑型(logical)、日期型(date)、字符型(character)、复数型(complex)、原味性(raw 二进制形式保存数据)。此外可能是缺省值(NA)和空值(NULL)。其中最常用的4种类型分别是数值型、逻辑型、日期型、字符型。
对象种存储的数据类型可以使用mode()函数进行查看
判别和转换数据对象类型的函数
| 数据类型 | 判别函数 | 转换函数 |
|---|---|---|
| 数值型(numeric) | is.numeric() | as.numeric() |
| 字符型(character) | is.character() | as.character() |
| 逻辑型(logical) | is.logical() | as.logical() |
| 整数型(integer) | is.integer() | as.integer() |
| 复数型(complex) | is.complex() | as.complex() |
| 空值(NULL) | is.null() | as.null() |
R语言数据对象的基本属性是长度和类型属性,可使用length()函数读取对象的长度,通过mode()函数读取对象的类型。
向量vector
- R语言最基础的数据对象是向量,向量是以一维数组的方式管理数据。
- 多数情况下都会使用长度大于1的向量,可使用
c()函数(combine 合并)和对应参数来创建一个向量。 - 向量的数据类型可以是字符型、逻辑型(TRUE/T、FALSE/F)、数值型、复数型。
- 向量的长度是含有元素的个数,可使用
length()函数进行读取。
例如:创建数值型向量
> (v<-c(1,2,3,4,5,6,7))
[1] 1 2 3 4 5 6 7
> mode(v)
[1] "numeric"
> length(v)
[1] 7
例如:创建字符型向量
> (v = c("hello", "world"))
[1] "hello" "world"
> mode(v)
[1] "character"
> length(v)
[1] 2
例如:创建逻辑型向量
> (v<-c(TRUE, FALSE, T, F))
[1] TRUE FALSE TRUE FALSE
> mode(v)
[1] "logical"
> length(v)
[1] 4
- 向量的元素必须具有相同数据类型,若不是则会强行执行类型转换。
例如:数值型 + 字符型 = 字符串
> v1 = c(1,2,3)
> v2 = c("a", "b", "c")
> v = c(v1, v2)
> v
[1] "1" "2" "3" "a" "b" "c"
> mode(v)
[1] "character"
> length(v)
[1] 6
例如:数值型 + 逻辑型= 数值型
> v1 = c(1,2,3)
> v2 = c(T,F,T)
> v = c(v1, v2)
> v
[1] 1 2 3 1 0 1
> mode(v)
[1] "numeric"
> length(v)
[1] 6
例如:字符型 + 逻辑型 = 字符型
> v1 = c("a", "b", "c")
> v2 = c(T, T, F)
> v = c(v1, v2)
> v
[1] "a" "b" "c" "TRUE" "TRUE"
[6] "FALSE"
> mode(v)
[1] "character"
> length(v)
[1] 6
向量运算
R语言是矢量化语言,其中最强大之一的函数的向量化,意味着操作会自动应用于向量的每个元素,而无需遍历。
例如:创建1~10序列组成的向量,对向量种每个元素进行开方根。
> v = seq(1:10)
> (round(sqrt(v), 2))
[1] 1.00 1.41 1.73 2.00 2.24 2.45 2.65 2.83 3.00 3.16
向量的四则运算
例如:向量相加
> rm(list = ls())
> v1 = c(1,2,3)
> v2 = c(1.1, 2.2, 3.3)
> (v1+v2)
[1] 2.1 4.2 6.3
- 如果向量的长度不同则R语言会利用循环规则重复较短的向量元素,直到得到向量长度于较长向量的长度相同。
> rm(list = ls())
> (v1 <- c(1,2,3,4,5,6,7))
[1] 1 2 3 4 5 6 7
> (v2 <- c(10, 20))
[1] 10 20
> (v <- v1 + v2)
[1] 11 22 13 24 15 26 17
Warning message:
In v1 + v2 :
longer object length is not a multiple of shorter object length
警告:长对象的长度不是短对象长度的整数倍
生成数列
R语言中使用冒号:自动生成增量为1或-1的数列
例如:生成1到10增量为1的等差数列
> rm(list = ls())
> 1:10
[1] 1 2 3 4 5 6 7 8 9 10
例如:生成10到1增量为-1的等差数列
> 10:1
[1] 10 9 8 7 6 5 4 3 2 1
对于增量不为1的数列可使用seq()序列函数生成
seq(from=1, to=1, by=((to-from) / (length.out-1)), length.out=NULL, along.with=NULL, ...)
| 参数 | 描述 |
|---|---|
| from | 等差数列的首项数值,默认为1。 |
| to | 等差数列的尾项数值,默认为1。 |
| by | 等差数值 |
| length.out | 产生向量的长度,可简写为len |
如果只给出首项和尾项数据则等差数值by将自动匹配为1或-1
> seq(1, 10)
[1] 1 2 3 4 5 6 7 8 9 10
> seq(10, 1)
[1] 10 9 8 7 6 5 4 3 2 1
> seq(0, -10)
[1] 0 -1 -2 -3 -4 -5 -6 -7 -8 -9 -10
如果给出首项和尾项以及长度则会自动计算等差数值
> seq(1, 10, length.out=5)
[1] 1.00 3.25 5.50 7.75 10.00
> seq(1, 10, length.out=4)
[1] 1 4 7 10
如果给出首项和等差数值和长度则会自动计算尾项
> seq(1, by=2, length.out=10)
[1] 1 3 5 7 9 11 13 15 17 19
重复数列
R语言中的rep()函数为重复函数可将向量重复若干次
rep(x, time=1, each=1, length.out=1)
| 参数 | 描述 |
|---|---|
| x | 预重复的序列 |
| times | 重复次数 |
| each | 设置向量元素先重复的次数 |
| length.out | 设置重复数列的长度,可简写为len |
> rep(1:3)
[1] 1 2 3
> rep(1:3, times=2)
[1] 1 2 3 1 2 3
> rep(1:3, each=2)
[1] 1 1 2 2 3 3
> rep(1:3, c(2, 1, 2))
[1] 1 1 2 3 3
> rep(1:3, times=2, len=4)
[1] 1 2 3 1
如果设置的长度大于数列长度则会以循环补齐的方式补全
> rep(1:3, times=2, len=8)
[1] 1 2 3 1 2 3 1 2
字母序列
R语言中的letters和LETTERS函数可用于生成26个英文字母的小写和大写字符序列
> letters
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n"
[15] "o" "p" "q" "r" "s" "t" "u" "v" "w" "x" "y" "z"
> LETTERS
[1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N"
[15] "O" "P" "Q" "R" "S" "T" "U" "V" "W" "X" "Y" "Z"
向量索引
R语言中若需要访问向量中部分或个别元素可通过在向量名称后跟方括号[]中添加向量索引的方式来实现。
- 向量的初始位置为1
- 向量索引会根据元素在向量中的位置挑选中元素
- 向量索引为负数表示排除向量中相应位置的元素并返回其它位置的元素
- 可使用向量索引来选择多个元素
- 可使用逻辑向量条件选择元素
- 可使用表达式选择元素
例如:从5个随机数中挑选出位置为1, 3, 5的三个元素
> rm(list = ls())
> set.seed(1234)
> x = rnorm(5)
> x
[1] -1.2070657 0.2774292 1.0844412 -2.3456977 0.4291247
> x[c(1,3,5)]
[1] -1.2070657 1.0844412 0.4291247
例如:从5个随机数中删除第1、第2、第3个
> rm(list = ls())
> set.seed(1234)
> (x = rnorm(5))
[1] -1.2070657 0.2774292 1.0844412 -2.3456977 0.4291247
> x[c(-1, -2, -3)]
[1] -2.3456977 0.4291247
例如:保留首位删除中间
> rm(list = ls())
> set.seed(1234)
> (x = rnorm(5))
[1] -1.2070657 0.2774292 1.0844412 -2.3456977 0.4291247
> x[c(T,F,F,F,T)]
[1] -1.2070657 0.4291247
禁止混合使用正负值
> rm(list = ls())
> set.seed(1234)
> (v = rnorm(5))
[1] -1.2070657 0.2774292 1.0844412 -2.3456977 0.4291247
> v[c(1, -2)]
Error in v[c(1, -2)] : only 0's may be mixed with negative subscripts
例如:提取所有整数的元素
> rm(list = ls())
> set.seed(1234)
> (v = rnorm(5))
[1] -1.2070657 0.2774292 1.0844412 -2.3456977 0.4291247
> v>0
[1] FALSE TRUE TRUE FALSE TRUE
> v[v>0]
[1] 0.2774292 1.0844412 0.4291247
R语言中的which()函数将返回逻辑向量中为真的位置
例如:找出向量中大于50的元素的索引位置
-
sample()函数用于对序列继续宁无放回随机抽取多个元素组成向量 -
which()函数用于从逻辑向量中获取条件为真的元素的索引位置 -
which.min()函数用于从逻辑向量中获取元素最小值的索引位置 -
which.max()函数用于从逻辑向量中获取元素最大值的索引位置
> rm(list = ls())
> set.seed(1234)
> (v = sample(1:100, 10))
[1] 28 80 22 9 5 38 16 4 86 90
> which(v>50)
[1] 2 9 10
> which.min(v)
[1] 8
> which.max(v)
[1] 10
矩阵maxtrix
R语言中利用矩阵matrix描述二维数组,矩阵和向量相似,其内部元素可以是实数、复数、字符、逻辑值等数据。
矩阵matrix使用两个下标来访问元素,比如m[i,j]表示矩阵m中第i行第j列的数据。
R语言中使用matrix()函数以向量形式输入矩阵中的元素,使用ncol和nrow属性设置矩阵的列数和行数,从而创建一个矩阵。
> rm(list = ls())
> set.seed(1234)
> (v = sample(1:100, 16))
[1] 4 100 21 40 84 56 67 93 5 66 47 97 96 48 3 41
> (m = matrix(v, nrow=4, ncol=4))
[,1] [,2] [,3] [,4]
[1,] 4 84 5 96
[2,] 100 56 66 48
[3,] 21 67 47 3
[4,] 40 93 97 41
默认举证是按列填充,若需按行填充则需设置byrow参数为真。
> (v = seq(1:10))
[1] 1 2 3 4 5 6 7 8 9 10
> (m = matrix(v, ncol=5, nrow=2, byrow=T))
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 6 7 8 9 10
数组 array
R语言中利用array描述多维数组,多维数组有一个特征属性叫做dim维数向量,dim维数向量的长度是多维数组的维数,dim内的元素对应维度的长度。矩阵只是数组的特殊情况,因为它只具有两个维度。