本章节以及后续章节的源码,当然也可以从我的github下载,在源码中我自己加了一些中文注释。
美国社会保障总署(SSA)提供了一份从1880年到现在的婴儿名字频率数据。你可以用这个数据集做很多事,例如:
计算指定名字(可以是你自己的,也可以是别人的)的年度比例。
计算某个名字的相对排名。
计算各年度最流行的名字,以及增长或减少最快的名字。
分析名字趋势:元音、辅音、长度、总体多样性、拼写变化、首尾字母等。
分析外源性趋势:圣经中的名字、名人、人口结构变化等。
美国社会保障总署将该数据库按年度制成了多个数据文件,其中给出了每个性别/名字组合的出生总数。这些文件的原始档案可以在这里获取:http://www.ssa.gov/oact/babynames/limits.html。
下载"National data"文件names.zip,解压后的目录中含有一组文件(如yob1880.txt)。
一、对所有婴儿姓名的预处理
1、文件是一个非常标准的以逗号隔开的格式,所以可以用pandas.read_csv将其加载到DataFrame中

这些文件中仅含有当年出现超过5次的名字。为了简单起见,我们可以用births列的sex分组小计表示该年度的births总计:
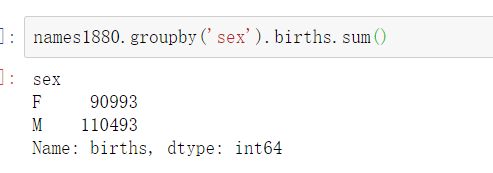
由于该数据集按年度被分隔成了多个文件,所以第一件事情就是要将所有数据都组装到一个DataFrame里面,并加上一个year字段。使用pandas.concat即可达到这个目的:
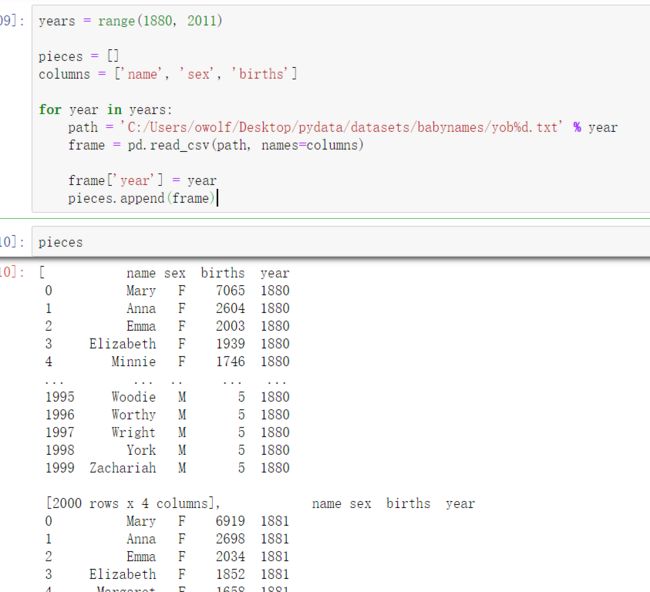
pieces是许多个DataFrame的集合:

每一个DataFrame的数据如下:

这里需要注意几件事情。第一,concat默认是按行将多个DataFrame组合到一起的;第二,必须指定ignore_index=True,因为我们不希望保留read_csv所返回的原始行号。现在我们得到了一个非常大的DataFrame,它含有全部的名字数据。有了这些数据之后,我们就可以利用groupby或pivot_table在year和sex级别上对其进行聚合了
2、以年为索引,性别为列,出生数为值。统计每年的男女出生总数

3、插入一个prop列,用于存放指定名字的婴儿数相对于总出生数的比例。prop值为0.02表示每100名婴儿中有2名取了当前这个名字。因此我们先按year和sex分组,然后再将新列加到各个分组上:

4、在执行这样的分组处理时,一般都应该做一些有效性检查,比如验证所有分组的prop的总和是否为1。

5、取出该数据的一个子集:每对sex/year组合的前1000个名字



这样也可以:



二、分析命名趋势
有了完整的数据集和刚才生成的top1000数据集,我们就可以开始分析各种命名趋势了。首先将前1000个名字分为男女两个部分:

1、生成一张按year和name统计总出生数透视表

2、用DataFrame的plot方法绘制几个名字的曲线图


结论:从图中可以看出,这几个名字在美国人民的心目中已经风光不再了。
三、评估命名多样性的增长
1、一种解释是父母愿意给小孩起常见的名字越来越少。这个假设可以从数据中得到验证。一个办法是计算最流行的1000个名字所占的比例,我按year和sex进行聚合并绘图。

结论:从图中可以看出,名字的多样性确实出现了增长(前1000项的比例降低)。
2、另一个验证办法是计算占总出生人数前50%的不同名字的数量,这个数字不太好计算。我们只考虑2010年男孩的名字:

在对prop降序排列之后,我们想知道前面多少个名字的人数加起来才够50%。虽然编写一个for循环确实也能达到目的,但NumPy有一种更聪明的矢量方式。先计算prop的累计和cumsum,然后再通过searchsorted方法找出0.5应该被插入在哪个位置才能保证不破坏顺序:

由于数组索引是从0开始的,因此我们要给这个结果加1,即最终结果为117。拿1900年的数据来做个比较,这个数字要小得多:

3、现在就可以对所有year/sex组合执行这个计算了。按这两个字段进行groupby处理,然后用一个函数计算各分组的这个值:



结论:从图中可以看出,女孩名字的多样性总是比男孩的高,而且还在变得越来越高。
四、最后一个字母的变革
1、 近百年来,男孩名字在最后一个字母上的分布发生了显著的变化。为了了解具体的情况,我首先将全部出生数据在年度、性别以及末字母上进行了聚合:


选出具有一定代表性的三年:

2、接下来我们需要按总出生数对该表进行规范化处理,以便计算出各性别各末字母占总出生人数的比例:


3、有了这个字母比例数据之后,就可以生成一张各年度各性别的条形图了


结论: 可以看出,从20世纪60年代开始,以字母"n"结尾的男孩名字出现了显著的增长。
4、回到之前创建的那个完整表,按年度和性别对其进行规范化处理,并在男孩名字中选取几个字母,最后进行转置以便将各个列做成一个时间序列:



5、有了这个时间序列的DataFrame之后,就可以通过其plot方法绘制出一张趋势图

五、变成女孩名字的男孩名字(以及相反的情况)
另一个有趣的趋势是,早年流行于男孩的名字近年来“变性了”,例如Lesley或Leslie。回到top1000数据集,找出其中以"lesl"开头的一组名字:


利用这个结果过滤掉其他的名字,并按名字分组计算出生数以查看相对频率

然后利用这个结果过滤其他的名字,并按名字分组计算出生数以查看相对频率:

按性别和年度进行聚合,并按年度进行规范化处理:




快速学习:
第一节 NumPy基础(一)
第二节 NumPy基础(二)
第三节 Pandas入门基础
第四节 数据加载、存储
第五节 数据清洗
第六节 数据合并、重塑
第七节 数据聚合与分组运算
第八节 数据可视化
第九节 pandas高级应用
第十节 时间序列
第十一节 Python建模库
数据分析案例--1880-2010年间全美婴儿姓名的处理
数据分析案例--MovieLens 1M数据集
数据分析案例--USA.gov数据
数据分析案例--2012联邦选举委员会数据库
数据分析案例--USDA食品数据库