0.概述
线性回归不仅可以做回归问题的处理,也可以通过与阈值的比较转化为分类的处理,但是其假设函数的输出范围没有限制,这样很大的输出被分类为1,较少的数也被分为1,这样就很奇怪。而逻辑回归的假设函数的输出范围是0~1。
当数据集中含有误差点时,使用线性回归相应的误差也会很大。
逻辑回归其实是分类算法,但是由于历史原因被称为逻辑回归。
逻辑回归的假设函数以线性回归的假设函数为基础,通过S形函数进行复合形成的复合函数。
虽然逻辑回归的代价函数和线性回归的代价函数在形式上是一样的,但是假设函数不一样,因而实际上是不一样的。
逻辑回归是一种非常强大,甚至可能世界上使用最为广泛的一种分类算法。
1.分类问题
逻辑回归是一种分类算法
在分类问题中,要预测的变量y是离散的值
逻辑回归是目前最流行使用最广泛的一种学习算法
2.假说表示
假设函数的要求:由于逻辑回归这种分类器要求的输出值在0和1之间,因此需要想出一个满足预测值在0到1之间的假设函数
逻辑回归的假设模型:
其中,X代表特征向量,g代表逻辑函数(logistic function)是一个常用的逻辑函数为S形函数(Sigmoid function)。
S形函数(Sigmoid function):
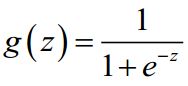
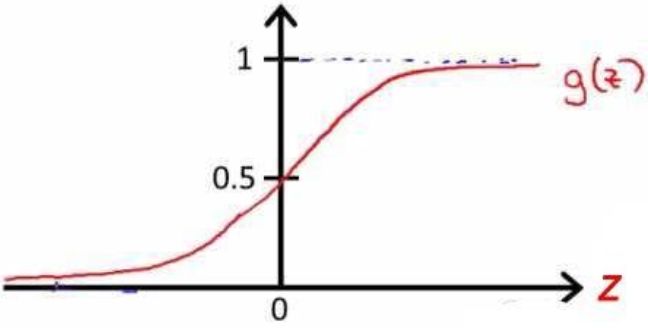
该函数的图像为:
合起来,我们得到逻辑回归模型的假设:
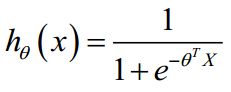
hθ(x)的作用是,对于给定的输入变量,根据选择的参数计算输出变量=1 的可能性(estimated probablity)即
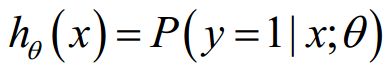
假设函数的值为0.7,则表示有70%的几率y为正向类。
3.决策边界
决策边界(decision boundary)由假设函数决定,理论上可以为任意曲线。
4.代价函数
对于线性回归模型,代价函数是所有模型误差的平方和。但是在逻辑回归中,假设函数带入到误差平方和模型中,假设函数将会是一个非凸函数(non-convex function),这样有许多局部最小值,这将影响梯度下降算法寻找全局最小值。
逻辑回归的代价函数:
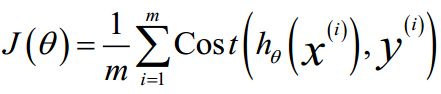
,其中
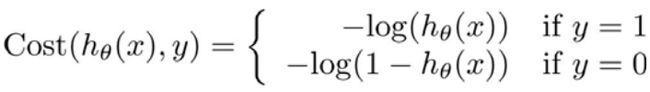
将构建的 Cost(hθ(x),y)简化如下:
逻辑回归的代价函数是关于输入变量theta 0、theta 1、…、theta n的一个函数。
带入代价函数得到:
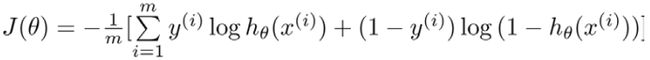
在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能使代价函数最小的参数了。
梯度下降:
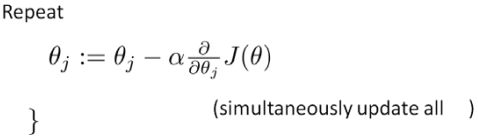
求导后得到:
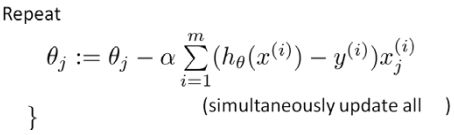
5.简化的代价函数和梯度下降
逻辑回归和线性回归的梯度下降公式看上去一样,都是:
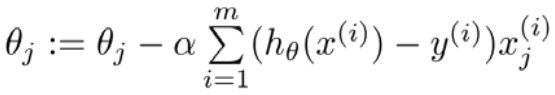
但是其假设函数不一样
线性回归假设函数:
逻辑回归假设函数:
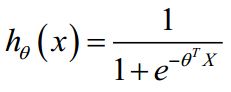
6.高级优化
除了梯度下降法,还有共轭梯度法、BFGS(变尺度法)和L-BFGS(限制变尺度法),这三种算法的优点是不需要手动选择学习率,比梯度下降法快,缺点是更加复杂。
7.多类别分类:一对多
我们将谈到如何使用逻辑回归 (logistic regression)来解决多类别分类问题,具体来说,可以通过一个叫做”一对多” (one-vs-all) 的分类算法。
假设一个训练集有三个类别,可以转化为三个两元分类的问题。
最后,在我们需要做预测时,我们将所有的分类机都运行一遍,然后对每一个输入变量,都选择最高可能性的输出变量。
各种可能性的概率之和为1。
8.代码
(1)原始模型
"""
功能:逻辑回归
说明:
作者:唐天泽
博客:http://blog.csdn.net/u010837794/article/details/
日期:2017-08-14
"""
"""
导入项目所需的包
"""
import numpy as np
import matplotlib.pyplot as plt
# 使用交叉验证的方法,把数据集分为训练集合测试集
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
# 加载iris数据集
def load_data():
diabetes = datasets.load_iris()
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
diabetes.data, diabetes.target, test_size=0.30, random_state=0)
return X_train, X_test, y_train, y_test
# 使用LogisticRegression考察线性回归的预测能力
def test_LogisticRegression(X_train, X_test, y_train, y_test):
# 选择模型
cls = LogisticRegression()
# 把数据交给模型训练
cls.fit(X_train, y_train)
print("Coefficients:%s, intercept %s"%(cls.coef_,cls.intercept_))
print("Residual sum of squares: %.2f"% np.mean((cls.predict(X_test) - y_test) ** 2))
print('Score: %.2f' % cls.score(X_test, y_test))
if __name__=='__main__':
X_train,X_test,y_train,y_test=load_data() # 产生用于回归问题的数据集
test_LogisticRegression(X_train,X_test,y_train,y_test) # 调用 test_LinearRegression
Coefficients:[[ 0.40051422 1.30952762 -2.09555215 -0.9602869 ]
[ 0.3779536 -1.39504236 0.41399108 -1.09189364]
[-1.66918252 -1.18193972 2.39506569 2.00963954]], intercept [ 0.24918551 0.81149187 -0.97217565]
Residual sum of squares: 0.11
Score: 0.89
(2)在(1)的基础上使用多分类参数
"""
功能:逻辑回归
说明:
作者:唐天泽
博客:http://blog.csdn.net/u010837794/article/details/
日期:2017-08-14
"""
"""
导入项目所需的包
"""
import numpy as np
import matplotlib.pyplot as plt
# 使用交叉验证的方法,把数据集分为训练集合测试集
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
# 加载iris数据集
def load_data():
diabetes = datasets.load_iris()
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
diabetes.data, diabetes.target, test_size=0.30, random_state=0)
return X_train, X_test, y_train, y_test
# 使用LogisticRegression考察线性回归的预测能力
def test_LogisticRegression_multiomaial(X_train, X_test, y_train, y_test):
# 选择模型
cls = LogisticRegression(multi_class='multinomial',solver='lbfgs')
# 把数据交给模型训练
cls.fit(X_train, y_train)
print("Coefficients:%s, intercept %s"%(cls.coef_,cls.intercept_))
print("Residual sum of squares: %.2f"% np.mean((cls.predict(X_test) - y_test) ** 2))
print('Score: %.2f' % cls.score(X_test, y_test))
if __name__=='__main__':
X_train,X_test,y_train,y_test=load_data() # 产生用于回归问题的数据集
test_LogisticRegression_multiomaial(X_train,X_test,y_train,y_test) # 调用 test_LinearRegression
Coefficients:[[-0.39772352 0.83347392 -2.28853669 -0.98142875]
[ 0.54455173 -0.29022825 -0.23370111 -0.65566222]
[-0.14682821 -0.54324567 2.5222378 1.63709097]], intercept [ 8.99974988 1.54361012 -10.54336001]
Residual sum of squares: 0.02
Score: 0.98
(3)考虑正则化系数
"""
功能:逻辑回归
说明:
作者:唐天泽
博客:http://blog.csdn.net/u010837794/article/details/
日期:2017-08-14
"""
"""
导入项目所需的包
"""
import numpy as np
import matplotlib.pyplot as plt
# 使用交叉验证的方法,把数据集分为训练集合测试集
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
# 加载iris数据集
def load_data():
diabetes = datasets.load_iris()
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
diabetes.data, diabetes.target, test_size=0.30, random_state=0)
return X_train, X_test, y_train, y_test
# 使用LogisticRegression考察线性回归的预测能力
def test_LogisticRegression_C(X_train, X_test, y_train, y_test):
Cs=np.logspace(-2,4,num=100)
scores=[]
for C in Cs:
# 选择模型
cls = LogisticRegression(C=C)
# 把数据交给模型训练
cls.fit(X_train, y_train)
scores.append(cls.score(X_test, y_test))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(Cs,scores)
ax.set_xlabel(r"C")
ax.set_ylabel(r"score")
ax.set_xscale('log')
ax.set_title("LogisticRegression")
plt.show()
if __name__=='__main__':
X_train,X_test,y_train,y_test=load_data() # 产生用于回归问题的数据集
test_LogisticRegression_C(X_train,X_test,y_train,y_test) # 调用 test_LinearRegression
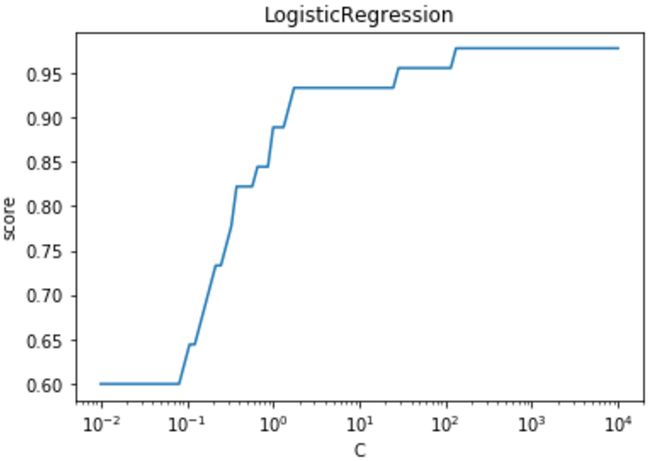
9.总结
10.参考资料
[1] ng CS229
[2] 李航 《统计学习方法》
[3] 华校专《Python大战机器学习》