数据库版本
5.7.26
事务隔离级别
RR
Case A
建表语句一
CREATE TABLE `test13` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` int(11) DEFAULT NULL,
`uid` int(11) DEFAULT NULL,
`env` varchar(64) NOT NULL DEFAULT '' COMMENT '使用环境',
PRIMARY KEY (`id`),
KEY `idx_uid` (`uid`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
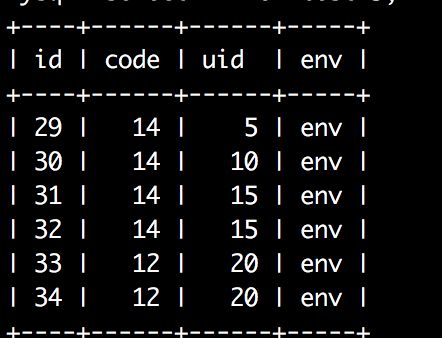
insert into `test13` (`code`,`uid`,`env`) values (14,5,'env'),(14,10,'env'),(14,15,'env'),(14,15,'env'),(12,20,'env'),(12,20,'env');
事务列表一
| 时间轴 | 事务1 | 事务2 |
|---|---|---|
| T1 | begin | begin |
| T2 | update test13 set code = 15 where uid in (5,20);Query OK, 0 rows affected(0.00 sec)Rows matched: 3 Changed: 0 Warnings: 0 | |
| T3 | update test13 set code = 13 where uid = 15; RROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction |
通过指令 show engine innodb status看到的信息是事务2在等待主键上的行锁

Case B
建表语句二
CREATE TABLE `x` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c` int(11) NOT NULL DEFAULT '0',
`d` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_c` (`c`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;
表记录

事务列表二
| 时间轴 | 事务1 | 事务2 |
|---|---|---|
| T1 | begin | begin |
| T2 | update x set d = 1 where c in (5,10);Query OK, 0 rows affected (0.00 sec)Rows matched: 2 Changed: 0 Warnings: 0 | |
| T3 | update x set d = 1 where c = 7;Query OK, 0 rows affected (0.00 sec)Rows matched: 1 Changed: 0 Warnings: 0 | |
| T4 | commit; | |
| T5 | commit; |
事务顺利执行,没有发生任何锁等待。
分析
参考MySQL 加锁处理分析
对上面的case进行分析。两个Case很类似,都是开启两个事务,第一个事务通过二级非唯一索引 使用 in 对记录进行更新,第二个事务通过同一个二级非唯一索引对记录进行等值更新
CaseB为例进行分析
事务1 首先会获取uid索引上面行记录为5和10上Next-key lock,分别是(3,5),5,(5,7),(7,10),10,(10,12) 然后再获取对应主键上面的记录锁
事务2 首先会获取uid索引上面行记录为7上的Next-key lock, 分别是(5,7),7,(7,10) 然后获取对应主键上面的记录锁
因为gap锁之间是可以相互兼容的,uid上面的行锁没有冲突,对应的主键也没有发生竞争,所以CaseB可以顺利执行。
caseA中事务2为什么会等待事务1持有的锁呢?
首先对CaseA的Update语句转为对应的Select语句查看对应的查询计划


我惊奇的发现第一条SQL没有使用上索引,而是执行了全表扫描,这就意味全表加锁,获取了主键所有的行锁 ,而第二条SQL是走索引的,但是与第一条SQL发生了锁竞争。
第二个疑问,为什么Case B没有发生锁竞争,接下来对CaseB进行转换Select

发现这条SQL是走索引的,跟我之前分析的一致。
那么问题就转换为为什么 CaseA中的第一条SQL就走全表扫描?
索引的区分度过低?
我们都知道当索引的区分度过低时,sql优化器会放弃走索引,直接走全表扫描,但是CaseA中的第二条SQL同样也走了索引,并且在执行下面的SQL,增加区分度后,第一条SQL还是走了全表扫描
insert into `test13` (`code`,`uid`,`env`) values (14,51,'env'),(14,101,'env'),(14,151,'env'),(14,152,'env'),(12,201,'env'),(12,203,'env');
选择的数据有问题?
对比两个case,索引的区分度差不多,主要的区别在于条件的数据不同,CaseA中的(5,20)存在重复数据,CaseB中的(5,10)中没有重复数据,那么我们换一批数据试试

当查询条件变成(5,51)的时候,这条SQL是正常走索引的。
把uid=20的重复数据删除一条看看效果,发现SQL正常走索引

重新执行CaseA的事务列表
| 时间轴 | 事务1 | 事务2 |
|---|---|---|
| T1 | begin | begin |
| T2 | update test13 set code = 15 where uid in (5,20); Query OK, 2 rows affected (0.00 sec) Rows matched: 2 Changed: 2 Warnings: 0 |
|
| T3 | update test13 set code = 13 where uid = 15; Query OK, 2 rows affected (0.00 sec) Rows matched: 2 Changed: 2 Warnings: 0 |
|
| T4 | commit; | |
| T5 | commit; |
事务可以正常执行。
总结
当我们分析数据库加锁分析的时候,一定通过实际操作来分析,不要犯经验注意错误
对Update语句的分析可以现转化为对应的Select语句查看查询计划,看看SQL的执行情况
对于普通的二级非唯一索引,当我们修改数据的时候要注意重复的记录,尽量通过ID来更新