产品设计和优化基于数据而高于数据。数据是反映产品效果的一种有力辅助手段,因此,在设计产品、迭代功能前,最好都提前规划好本次“更新换代”的数据统计分析体系,并在上线后不断观察,根据数据反馈指导进一步的产品优化。然而,面对繁杂的数据指标和功能流程,该如何快速而清晰搭建起合适的数据衡量体系,是一个很重要的问题。
无论是搭建一套完整的体系,还是单纯用于衡量某个功能/优化的上线效果,一般而言,可以从下面四个步骤进行:
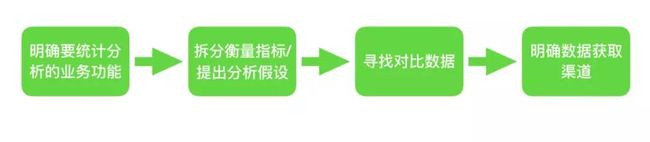
一、明确要统计分析的业务功能
数据是产品效果的表达方式,在搭建数据体系前,必须先明确业务类型、明确验证目标:
1、业务
不同的行业领域,其关注点是有很大差异的。
互联网金融领域,看重的是保有量非0的用户数、用户的资金保有量、申购量、用户财富指数等;电商行业,看重的是产生购买行为的用户数、用户购买金额、购买频次、复购周期等;社交类产品,看重的是用户活跃程度,如日活跃时长、社区活跃度(评论、发帖)等。
2、场景
是功能优化迭代验证效果?是差异化竞争的对比分析?是基于用户场景的拉新、留存、促活?还是流失场景的挽留?
产品数据体系,一般而言可以分为数据统计、数据分析两大类。
数据统计更多与产品功能效果挂钩,用于衡量某一个产品指标,如用户数量、DAU、MAU、用户购买金额等;数据分析则更多用于产品路径流程剖析、问题发现、迭代指导、运营效果反馈等场景。
不同的业务、不同的目标,决定了我们要选取什么数据指标来衡量。
二、拆分衡量指标/提出分析假设
明确了业务场景、统计/分析目标,下一步则是继续拆分合适的衡量指标;对于数据分析需求来说,还需要在此之前提出分析的假设。以下举例说明:
1、分析某个产品功能的转化率
转化率一般可分为注册转化率、申购转化率、场景用户转化率、入口转化率等,亦即“用户对某款产品路转粉”的过程。
进一步拆分,转化率链路上的关键数据,分别有:曝光UV → 点击UV → 转化用户数,对应的则是“用户看到 → 用户感兴趣并尝试 → 用户被转化”的行为。
将转化率放到场景中做分析,目标一般有两种:看某个产品/运营流程的转化效果,统计新用户从接触到最终被成功转化的转化率,多用漏斗模型来表现转化率数据;对于多渠道多入口触达的产品,或产品功能正在进行A/B
test,需通过比较多渠道多入口的转化率,对比每一个路径的效果。这两种模型在之前的《思维 | 数据驱动决策的10种思维》的文章中有提到。
2、通过活跃度分析指导产品优化方向
活跃度指标可分为用户登录/访问频次、场景设置频次、申购/购买频次、互动频次等,主要是看用户在产品上的留存和活跃程度,比如用户近30天内登录过10次,用户近90天内发生了30次申购行为。
有些产品/功能上线后,用户抱着尝鲜的态度被转化,使用为数不多的几次后即流失,即可明确下一阶段工作重点是提升用户的留存率。相反,有的产品用户留存率很高,但深究发现用户大部分处于不活跃状态,即可明确下一阶段的工作重点是用户促活。

3、监控用户健康度
产品的健康度在某种意义上说跟活跃度有点交叉,有些广义的概念可把活跃度包含于健康度内。
比如,ARPU值、用户流动性、会员体系下的用户升降级速度…都是衡量一款产品健康度的指标。
以会员体系下的用户升降级速度为例:设计一套会员体系时,数据体系的搭建就必须有事前规划测算、事中验证跟踪、事后调整这3个阶段。事前的规划测算一般需花费较大的时间和精力演算,因为一旦会员规则对外放开了,就不好轻易做调整。也因此,第3个阶段的调整,最好是能避免则避免。

会员体系需要拟合升降级曲线,一般达到的效果就是升级先易后难,降级留有一定buffer值。升级太快降级太慢,有导致体系被击穿、成本hold不住等风险,升级太慢降级太快,用户不买账没粘性。升降级速度,体现的是该产品的健康程度。
4、用户流失节点分析
很多产品上线一段时间后,发现流失率越来越高,这个时候可关注用户在整个链路上的流失节点:用户主要是在哪一步开始流失的,用户流失的集中时间点是在什么时候,从流失节点着手进行产品优化、适当的流失挽留堵漏等操作。
如互金平台定投功能的使用,经过观察和分析可能会发现,用户在第一次扣款前后的流失率最高,且扣款高峰会伴随着流失高峰,可能的原因有以下:
扣款前:用户设置时仅抱着尝鲜的心态,在扣款(实际发生资金行为)前及时终止定投“止损”;或者对扣款行为的安全感不足。
扣款后:对资金的安全和流动性存在担忧;自身无法保证银行卡资金在扣款日是充足的,因资金不足扣款失败而放弃。
找到了可能的问题所在,即可对齐进行相应的用户教育和引导,降低流失率。一个水缸多个孔,堵住其中1个或几个,水流失的速度自然就慢了下来。
5、通过假设潜在用户画像进行投放验证
产品对用户做触达的时候,总会选择潜在目标用户,以提高转化率等各项指标。但何为“目标用户”,用户的年龄?用户所在的地区?用户的在线支付频次?需要通过多次投放尝试总结,可假设多个变量,通过调整潜在目标用户的画像进行用户包提取触达,比较多个投放渠道之间的数据差异,从而达到验证的目的。
三、寻找对比数据
没有对比的效果指标评价,都是耍流氓。一款产品上线效果,产品经理要看到其中的利弊,并且找到合适的参照物来对比效果,才可以做出评价和结论。
举个例子:一款社区类产品上线至今,总用户数100万,日均活跃用户8万人。
这个数据是好是坏?我们需要找到一个对比衡量的标准,对比竞品,我们这个活跃用户水平算是较高的?对比过去的日均活跃用户5万人,则很明显有了提高。
因此,得到产品的上线效果数据后,需要找到对应的产品做标的,而这个标的,可以是竞品、可以是历史经验数据沉淀、也可以是行业内默认的标准等。
四、明确获取数据渠道
规划好了数据衡量体系,接下来即是产品上线前的数据埋点工作和上线后的数据获取来源,有下面的一串口诀:转化数据点击流,用户属性渠道号,反馈抽样用问卷,广义普适第三方。
1、转化数据点击流
在看用户登录访问、购买等产品的路径转化数据时,常选择用户数为统计分析维度,这个时候,用相对简单的点击流埋点,一般可满足需求;主要统计产品流程中,每一步操作的用户数量,可形成漏斗模型。
2、用户属性渠道号
在申购金额、购买数量和金额、评论互动等带有用户属性的场景下,需要适当深挖,这个时候可以用渠道号等标记对用户进行“打标”,方便跟踪监控用户的后续行为。
3、反馈抽样用问卷
有的时候,我们需要探究用户行为原因,了解用户的主观操作意向,获取用户使用反馈时,通过上述的纯客观数据是难以得出合适的指导意见的,该情况下可以选择问卷的方式进行;可以获取足够反馈问题的样本数据。
4、广义普适第三方
有一些第三方数据平台,如友盟、TalkingData、微信指数、百度指数等数据平台,适用于监控大行业大领域数据。如通过微信指数,可知道某个词汇的近期网络搜索次数,环比增减情况,添加对比词汇等。

方法论讲完,是不是还有点似懂非懂?以下我们将以最近很火的luckin coffee为例,看看它是否有可复制的数据分析套路?
五、luckin coffee背后的数据分析
对于luckin coffee来说,品牌定位更多在“职场咖啡”与“社交咖啡”上,因此,在获客初始节点,进行了不同商圈的线下试点门店铺设,通过各类优惠福利做app的推广下载和刺激用户分享获客。该阶段,如若进行数据分析,则首先需要明确分析目标:
1、明确分析目标
线下不同商圈的试点效果
用户对职场咖啡的诉求及预期
app推广效果/社交咖啡营销裂变效果
2、拆分衡量指标/提出分析假设
针对上述3点,可进一步提出对应的分析假设并寻找、拆分衡量指标:
① IT白领办公区域的门店效果优于市中心商圈;外带门店销售量高于堂食门店
② 中午13:00~14:00和下午15:00~17:00是点单高峰;外卖订单30~40分钟内送达符合用户心理预期,30分钟内则可超出预期;职场白领更偏好美式,女生更偏好瑞纳冰系列等
③ 社交分享推广目标,如老用户人均分享3次/周,人均转化拉新3人/周,人均购买3杯/周,复购率在60%以上等

针对上述分析假设,为更客观进行数据比较,可将上述假设进一步抽象为数据衡量指标,例如:
① 用各商圈门店的日均销售咖啡杯数、各品类咖啡(价格)销售数量占比、外卖&堂食销售数量占比来衡量各试点门店的销售效果,辅助扩张铺设/缩减投入的决策;
② 收集购买咖啡的用户画像属性数据,匹配性别、年龄、购买时间段、品类爱好、客户对外送单的反馈等,进而筛选出业务主打客群,完善饮品和服务细节;
③ 通过数据埋点的方式,追踪客户的app
UV/PV、咖啡购买杯数、优惠券链接分享次数、通过该分享链接点击进入并注册转化的新用户数量、用户在注册1周内二次下单的占比等数据;可得出对应app下单转化率、分享率、分享点击率、老拉新转化数、复购率等可精准客观对比的数据。
3、寻找对比数据
很多人都用luckin
coffee来对标星巴克、连咖啡,将三者作为竞争对比。同理,如何衡量luckin
coffee交出的这份答卷数据的好坏,则可通过对标星巴克、连咖啡相关业务的数据情况,如星巴克门店日销售量、日销售额,星巴克用星说礼品卡的销售量、赠送量等,将两者进行数据对比,进而得出结论。
按照数据体系搭建的四步法则,在产品上线前后提前做好产品数据的统计分析布局,验证效果、功能优化不再无从下手!