outline
- Generation
- Attention
- Tips for Generation
- Pointer Network
Generation
以下是使用RNN来生成句子的例子:
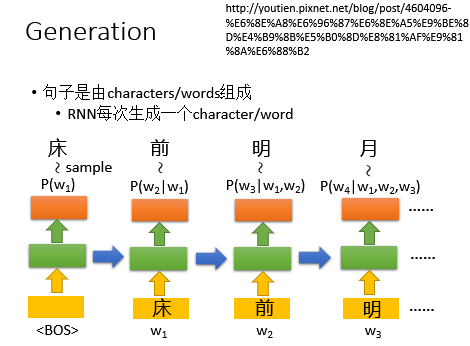
Tips:英文中的characters指的是:,words是 单词
中文中的characters指的是一个一个的字;words指的是词语,比如“葡萄”
RNN也可以用来生成图片:方法是将像素转化为句子,训练基于句子的语言模型
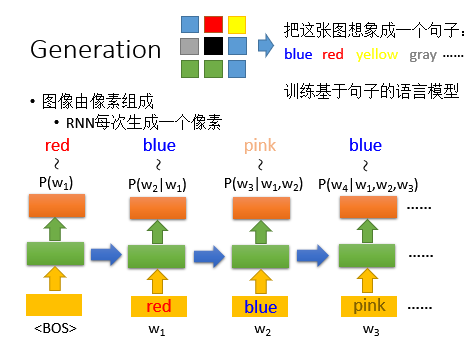
但是这个方法是有缺陷的,因为没有考虑到图像的几何关系,就比如下图:蓝色对下面灰色是有影响的,然而上一行的黄色对下一行的灰色是没有什么影响的。其实,如果使用的是RNN,在产生灰色的时候其实也已经考虑了前面所有的像素颜色,如果RNN 训练的够好,它可以学到三个像素之前的那个像素影响比较大。
一个比较理想的产生像素的方法是如右下角所示: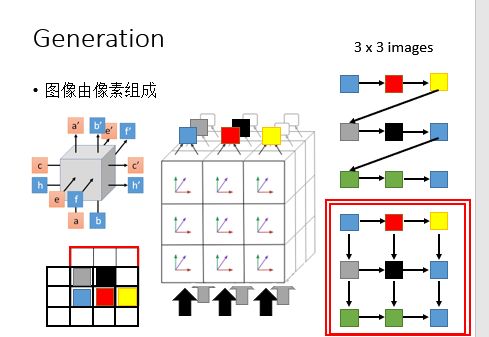
以下是一些其他的引用,比如说:
- 图像:
- Aaron van den Oord, Nal Kalchbrenner, Koray Kavukcuoglu, Pixel Recurrent Neural Networks, arXiv preprint, 2016
- Aaron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, Koray Kavukcuoglu, Conditional Image Generation with PixelCNN Decoders, arXiv preprint, 2016
- 视频:
- Aaron van den Oord, Nal Kalchbrenner, Koray Kavukcuoglu, Pixel Recurrent Neural Networks, arXiv preprint, 2016
- 手写体:
- Alex Graves, Generating Sequences With Recurrent Neural Networks, arXiv preprint, 2013
- 语音:
- Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior,Koray Kavukcuoglu, WaveNet: A Generative Model for Raw Audio, 2016
Conditional Generation
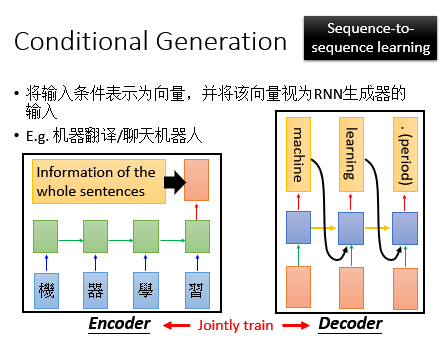
但是只能用RNN 生成的东西仅仅是不够的,为什么呢?因为只用RNN生成的东西,比如一个句子,看起来是合乎文法的句子,但是你没有办法控制要说什么;很多场合,我们需要的不是一个句子,而是一个和场景有关的句子或者是我们想要machine说的句子。如下图所示:

基于这种情况,我们需要将问题或者是需要被翻译的句子的所有信息丢到网络中,得到对应的答案或者翻译结果,这样的思想就是Encoder/Decoder思想,换句话说,就是我们的Seq2Seq。
首先,我们把问题或者需要被翻译的句子通过一个RNN或者LSTM进行Encoder,最后一个的输出就包含了这个句子的全部信息,然后我们把这个句子当作初始输入丢到另一个RNN或者LSTM中,然后通过这个得到对应的输出。
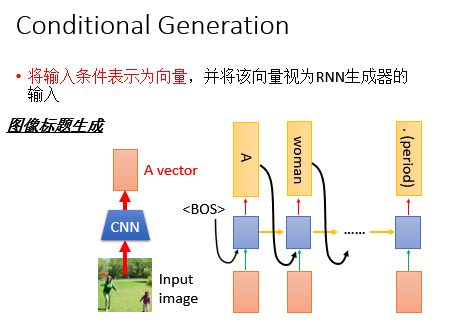
同样的方法,我们可以拿来做其他事情,比如:机器翻译/对话机器人等等。
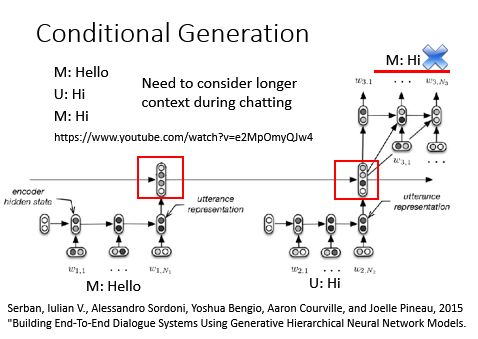
Attention——Dynamic Conditional Generation
机器翻译
我们以机器翻译作为例子: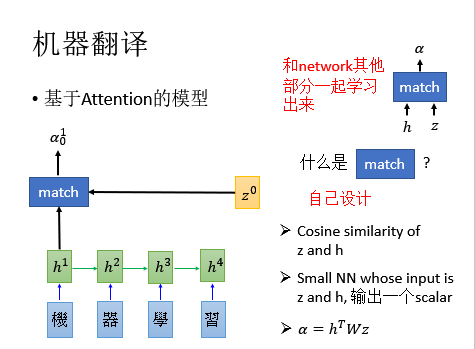
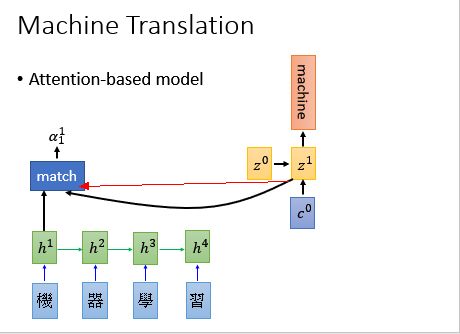
基于注意力的模型:
- 输入一个经过RNN 处理的句子,每一个时间点每一个词汇都可以用一个vactor进行表示,这个vector就是RNN的隐藏层的输出;
- 接下来,有一个初始的vector ,可以当作network的初始参数,可以根据训练数据学习出来。
- 如上图所示,我们有个函数,我们把和丢进去,得到,上标的意思是是和算匹配度,下标的意思是在时间为0的时候算相匹配的程度。函数可以自己设计。
- 举例来说:
①可以说其实是算和的Cosine similarity ;
②也可以说其实是一个神经网络,输入是和的连接,输出就是一个scalar;
③也可以说里面有一个参数,是一个matrix,是被学出来的,把和相乘,再乘以,会得到一个scalar :,即;
如果里面有参数的话,那么会跟network里面的其他部分一起学出来。
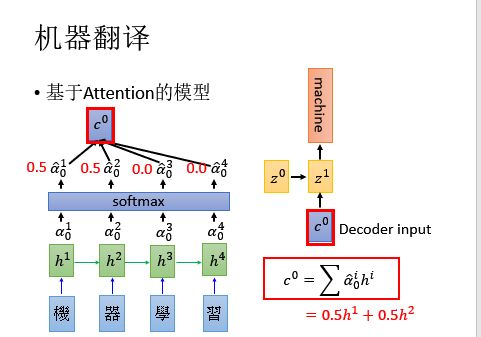
接下来,我们把得到的
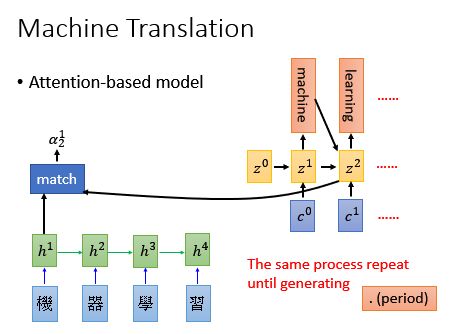
同理,得到:

重复这个生成的过程:
我们也可以把这个技术应用到语音识别当中:输入声音讯号,算match score,丢进去decoder;
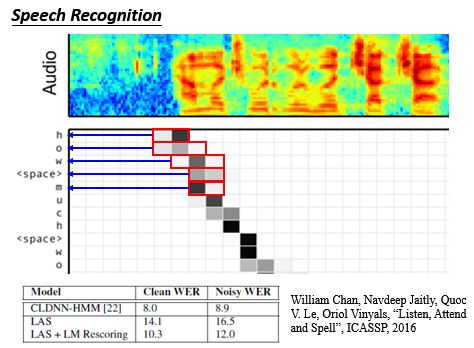
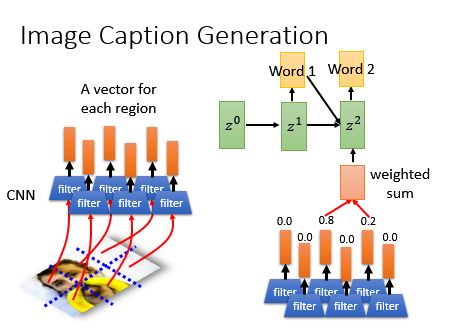
Image Caption Generation 图像标题生成
那么在图像标题生成中怎么加上基于Attention的模型呢?如果image用一个vector来做是没法描述的,所以你可以用一组vector来进行描述:
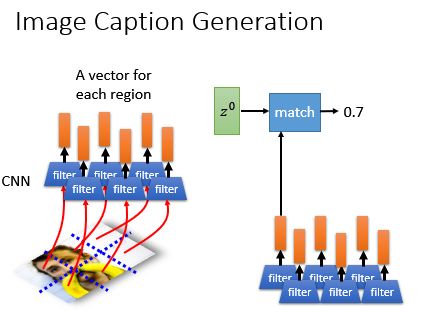
同时,在算出其他的匹配分数,做加权和,然后丢进去RNN里面,得到第一个单词:

同理:
以下是从一些文献中找出来的结果:这个图怎么看呢?

以下是一些不好的失败的例子:

Memory Network
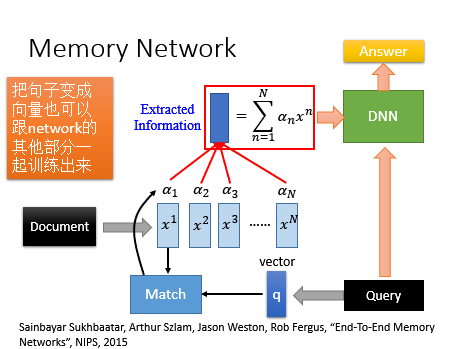
Memory Network是在memory上面做attention,Memory Network最开始也是最常见的应用是在阅读理解上面,如下图所示:一篇文章,有问题,肯能不能生成答案,文章里面有很多句子组成,每个句子表示成一个vector,假设有个句子,向量表示成,问题也用一个向量描述出来,接下来算问题与句子的匹配分数,然后做加权和,然后丢进去DNN里面,最后就可以得到答案了。
Memory Network有一个更复杂的版本,这个版本是这样的,算match的部分跟抽取infromation的部分不见得是一样的,如果他们是不一样的,其实你可以得到更好的performance。把文档中的同一句子用两组向量表示;对这一组vector算Attention,但是它是用这一组向量来表示infromation,把这些Attention乘以的加和得到提取的信息,放入DNN,得到答案。Hopping是指的是反复进行。
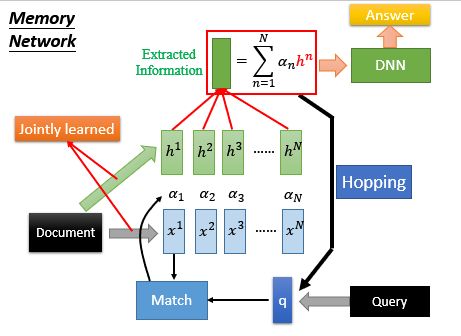
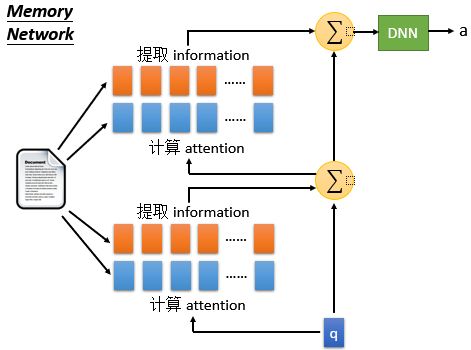
上图中 Hopping是指的是反复进行运算,我们可以任认为machine在反复思考答案对不对。下面我们用下图来进一步解释一下 Hopping:
如下图所示,我们用蓝色的vector计算attention,用橙色的vector做提取information。蓝色和蓝色,橙色和橙色的vector不一定是一样的。以下是两次加和后丢进去DNN得到答案。所以整件事情可以看作两个layer的神经网络。
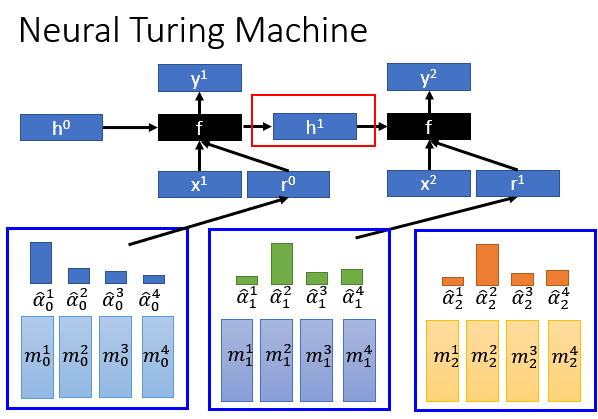
Neural Turing Machine
刚刚讲的Memory Network是在memory上面做attention,然后从memory里面把information抽取出来,然而 Neural Turing Machine不仅仅从memory里抽取information,他还可以根据你的match score去修改存在memory里面的内容(具备读和写的功能)如下图:
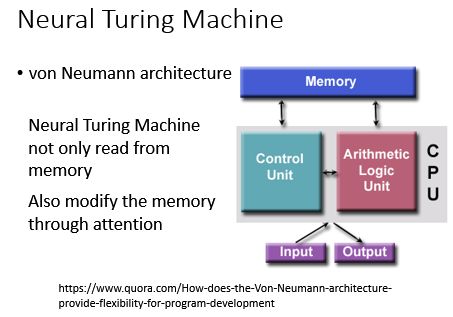
怎么去实现这个呢?
首先,有一组memory,即一组vector序列
接下来,有一组初始的attention的weight,,
根据初始的attention的weight和memory的vector序列,可以提取出information,得到vector ,把它交给另外一个神经网络,即一个函数,你可以任意设计这个函数,然后这个会输出几个vector,他们会去操控memory;
-
的作用就是用来产生attention的,把它与做cosine similarity,得到四个match score,接下来,在做softmax,就可以得到新的attention的distribution了。
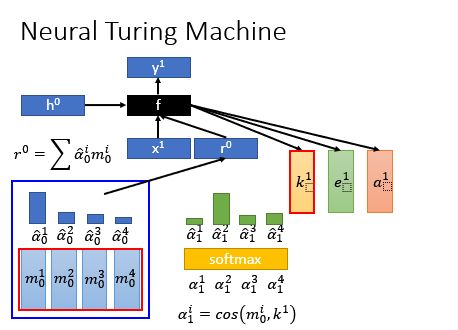
其实这是一个简化再简化的版本,真正的Neural Turing Machine它从加产生attention的步骤有五步: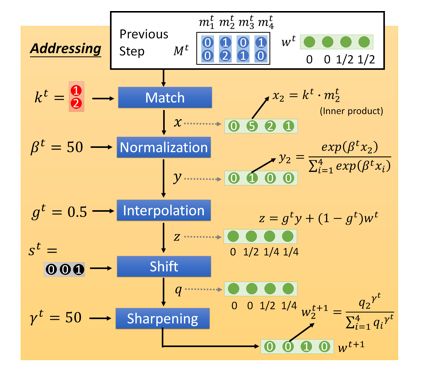
-
我们产生了attention之后,另外两个vector ,就回去修改memory中的值, 的作用是把原来memory里面的值清空; 的作用是要把新的值写进去。怎么去做呢?用这个公式:
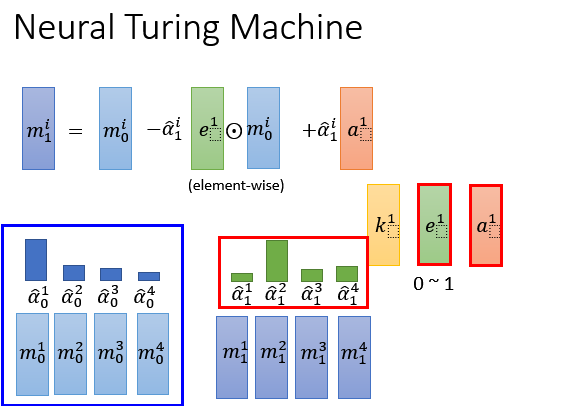
-
接下来,根据中间的四个vector 可以得到,然后加上新的人输入,然后就可以得到新的输出;
注意:这个函数可以是recurrent network,前一个时间点的不止会输出control memory的那些vector,他还会输出另外一个vector ,丢进去下一个中,产生操控memory的参数
Tips for Generation
接下来要讲training,如果要产生句子的时候有哪些技巧。
举例来说我们今天要做vedio的generation,我们给machine看一段如下的视频,如果你今天用的是Attention-based model的话,那么machine在每一个时间点会给vedio里面的每一帧(每一张image)一个attention,那我们 用来代表attention,上标代表是第个component,下标代表是时间点。那么下标是1的四个会得到,下标是2的四个会得到,下标是3的四个会得到,下标是4的四个会得到。
但是可能会有Bad Attention,如下图所示,举个例子,在得到第二个词的时候,attention(柱子最高的地方)主要在woman那儿,得到第四个词的时候,attention主要也在woman那儿,这样子得到的就不是一个好句子。
一个好的attention应该cover input所有的帧,而且每一帧的cover最好不要太多。最好的是:每一个input 组件有大概相同attention 权重。举一个最简单的例子,在本例中,希望在处理过程中所有attention的加和接近于一个值: ,这里的 是类似于learning rate的一个参数。用这个正则化的目的是可以调整比较小的attention,使得整个的performance达到最好。

Mismatch between Train and Test
你可能觉得生成一个句子听起来没什么,但是里面其实有很多枝枝节节的技巧是你没有发掘出来的。你有没有发现在training和testing的时候是有一个mismatch的?
在training的时候:假设我们有个句子叫做,那我们希望说machine在第一时间点越接近A越好,加一个粉色的condition,第一时间点RNN要输出A,同理,如下图所示:
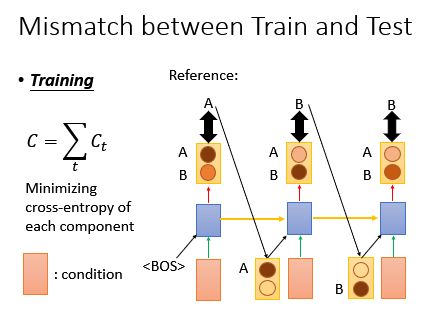
上面需要做的就是 minimize这三个()交叉熵的和
那么想想看在generation的时候会怎么做?
假设世界上只有两个word ,这样子能简化我们的图示。我们来看产生的第一个词,颜色越深代表几率越大,所以产生B的几率更大,machine输出B;
我们再生成的时候,不知道reference,Testing的时候:模型的输出是下一步的输入;Training的时候 输入就是reference.
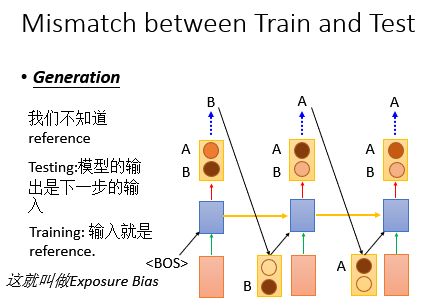
这听起来貌似没有什么,但是下面会告诉大家这件事情的影响。
如下图所示:上面这个case是training的时候,你直接把正确答案接下来; 下面这个case是testing的时候,你把machine的output接到下一个时间点;到底有何不同呢?

我们先来看上面这个case,我们用一个树状图来表示这个RNN,最下面的root是我们初始的state,输出哪个就走哪个路径,在training的时候根据reference我们正确的走法:
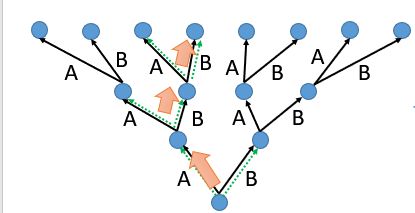
在上面提到过,在使用RNN生成句子的时候,通过初始的输入得到生成的第一个词,然后把这个词当作下一次的输入得到第二个词,依次类推,那么问题就来了,当这个序列中有一个词错误的时候,那么其实后面的整个句子序列就错了,就是所谓的一步错,步步错。
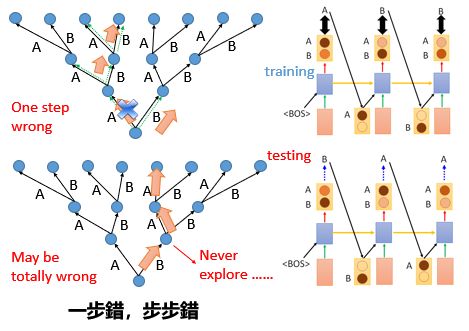
那么我们如何来解决这个一步错,步步错的问题呢?
Scheduled Sampling
Scheduled Sampling通过修改我们的训练过程来解决上面的问题,一开始我们只用真实的句子序列进行训练,而随着训练过程的进行,我们开始慢慢加入模型的输出作为训练的输入这一过程。
解释:我们纠结的点就是到底下一个时间点的input到底是从模型的output来呢,还是从reference来呢?这个Scheduled Sampling方法就说给他一个几率,几率决定以哪个作为input,以下是形象的图示: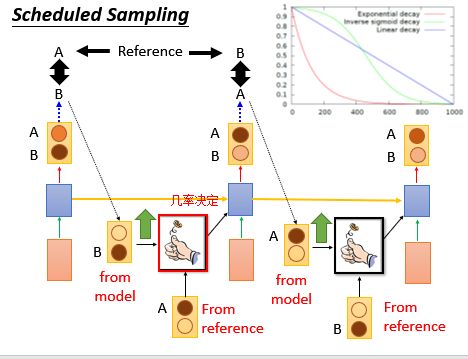

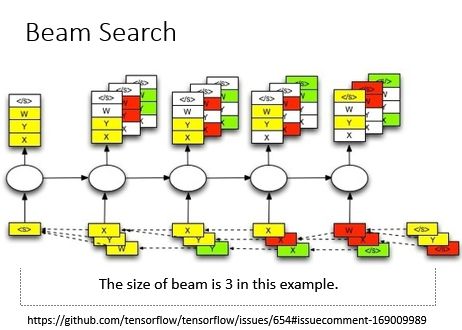
Beam Search
Beam Search方法不再是只得到一个输出放到下一步去训练了,我们可以设定一个值,拿多个值放到下一步去训练,这条路径的概率等于每一步输出的概率的乘积,大家看下面的图就很容易理解Beam Search的过程啦。
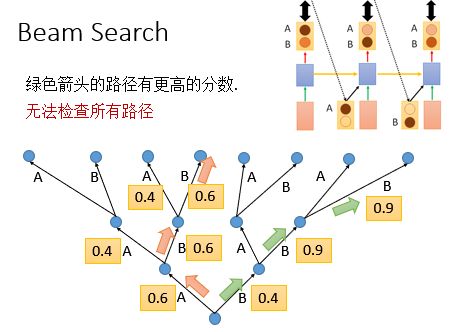
Beam Search方法是指在某个时间只pick几个分数最高的路径;选择一个beam size,即选择size个路径最佳。
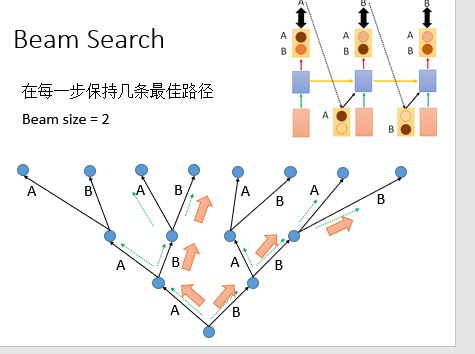
下一张图是如果使用beam search的时候,应该是怎么样的;
假设世界上只有三个词
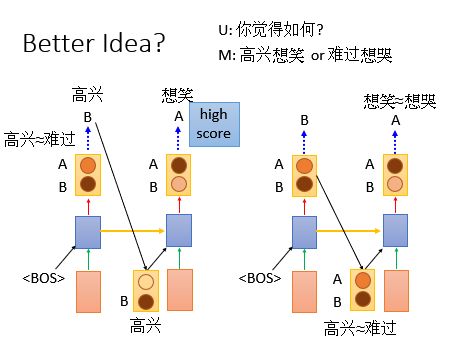
我们的猜测如下:右边的结果不好:
如下图所示:对于左边,高兴和难过的几率几乎是一样的,所以我们现在选择高兴丢进去,后面接想笑的几率会很大;
对于右边,高兴和难过的几率几乎是一样的,想笑和想哭的几率几乎是一样的,那么就可能出现高兴想哭和难过想笑这样的输出。
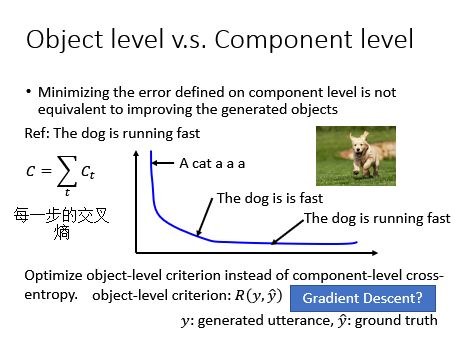
对象级别和组件级别
我们现在要生成的是整个句子,而不是单一的词语,所以我们在考量生成的结果好不好的时候,我们应该看一整个句子,而不是看单一的词汇。举例来说,这张图是说:The dog is running fast; 我们一般训练的时候使用的都是交叉熵加和作为loss,如下:纵轴就是交叉熵,横轴就是training的时间;第二个和第三个的句子loss十分小,因此要一直train,一直train;
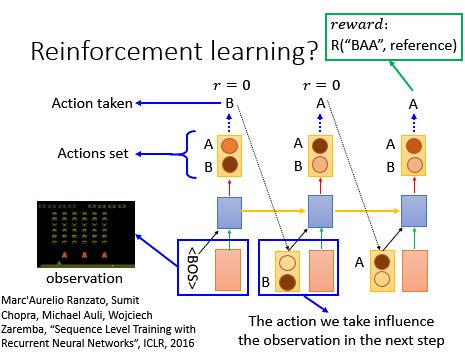
Reinforcement learning
下面是一些paper里面的效果:
如下图纵轴是相对传统方法的差异:
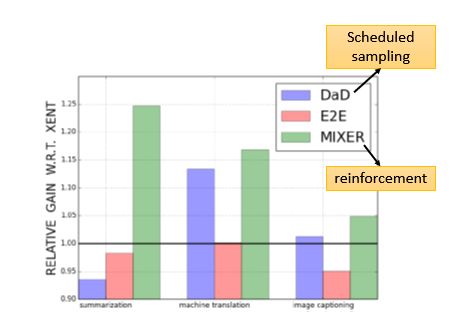
另外一张图:比较

Pointer Network
什么是Pointer Network?
Pointer Network最早是用来解决演算法(电脑算数学的学问)的问题。
举个例子:如下图所示,给出十个点,让你连接几个点能把所有的点都包含在区域内。拿一个NN出来,它的input就是10个坐标,我们期待它的输出是
,就可以把十个点圈起来。那就要准备一大堆的训练数据;
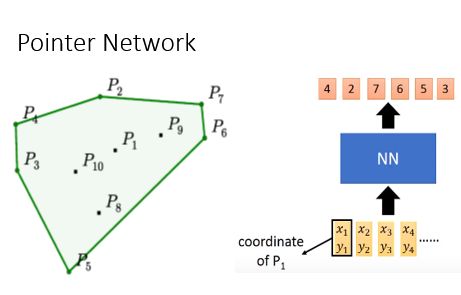
这个 Neural Network 的输入是所有点的坐标,输出是构成凸包的点的合集。
如何求解Pointer Network?
输入一排sequence,输出另一个sequence,理论上好像是可以用Seq2Seq解决的。那么这个 Network 可以用 seq2seq 的模式么?
答案是不行的,因为,我们并不知道输出的数据的多少。更具体地说,就是在 encoder 阶段,我们只知道这个凸包问题的输入,但是在 decoder 阶段,我们不知道我们一共可以输出多少个值。举例来说就是,第一次我们的输入是 50 个点,我们的输出可以是 0-50 (0 表示 END);第二次我们的输入是 100 个点,我们的输出依然是 0-50, 这样的话,我们就没办法输出 51-100 的点了。
为了解决这个问题,我们可以引入 Attention 机制。
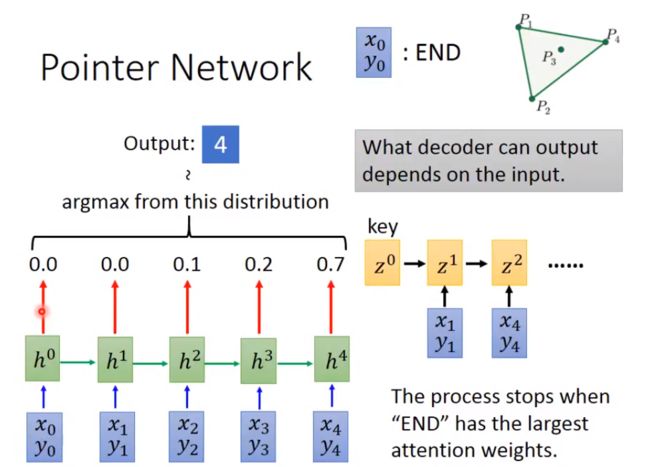
引入 Attention 机制,让network可以动态决定输出有多大。现在用Attention模型把这个sequence读取进来,第1-4个点,在这边我们要加一个特殊的点,代表END的点。
接下来,我们就采用我们之前讲过的attention-based model,初始化一个key,即为,然后用这个key去做attention-based model,用对每一input做attention,每一个input都产生有一个Attention Weight,举例来说,在这边attention的weight是0.5,在这边attention的weight是0.3,在这边attention的weight是0.2,在这边attention的weight是0,在这边attention的weight是0.0。这个attention weight就是我们输出的distribution,我们根据这个weight的分布取argmax,在这里,我取到,然后得到下一个key,即;同理,算权重,取argmax,得到下一个key,即,循环以上。以下是原理图:
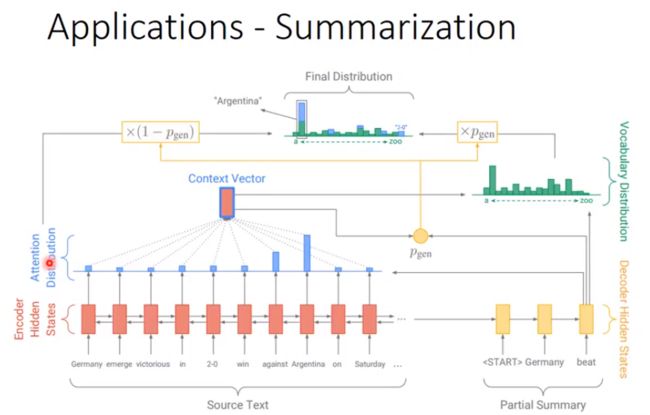
应用——总结(Summarization)
我们先来看:
更多的应用:
