对于机器学习模型性能的评价,我们最常见的指标就是准确率(Accuracy,ACC),当然,这是针对分类的。那么,除此之外,还有很多其他的指标。
前面我们列出的损失函数,其实在某种意义上也是对模型的一种评价指标。
1,二分类模型的评价指标
基础知识
对于二分类而言,样本有正负样本之分(Positive,Negative),而预测则有对错之分(True,False),所以可用过如下表来表示
| 真实值:P | 真实值:N | |
|---|---|---|
| 预测值:P | TP | FP |
| 预测值:N | FN | TN |
则
TP:真正例,真阳性。样本是正例,预测为正,分类正确
FP:假正例,假阳性。样本是负例,预测为正,分类错误。误诊
TN:真负例,真阴性。样本是负例,预测为负,分类正确
FN:假负例,假阴性。样本为正例,预测为负,分类错误。漏诊
准确率(Accuracy,ACC)
即分对样本数比总体样本数
计算简单,常见
缺点
1,当样本不平衡时会不准。例如正负样本9:1,模型把所有样本均判为正,计算出ACC=0.9 但这个模型是没有意义的。
此时,可以计算平均准确率,即每个类别内准确率的平均值。
2,太过简单,不能体现正负样本具体的分类对错情况
精确率(Precision,P)与召回率(Recall,R)
即模型预测为正的样本里,真正为正的比例
召回率也叫做敏感度(Sensitivity)
即在所有正样本中,模型准确找出的比例
P高代表模型预测为正,基本上就是正。表示其很准。但很准的原因可能是模型太严格,例如100个正例,模型只判断了其中1个为正,确实这个样本分对了,但是依旧错分了其他99个,造成假阴性变高。
R高代表模型更能够把正样本从样本中找出来,漏诊率低,很敏感,稍微不对就会判正。但例如模型把所有样本都判为正,此时召回率确实高,但没有意义。会带来很高的假阳性。
即高P很容易降低R,高R很容易降低P。两者需要权衡
F1 指数
因为P和R很容易此高彼低,所以F1的分子是P*R,这就使得,盲目提高P和R其中之一,并不会提高F1指数,只有当两者都高的时候,F1才会高。第二个等号后面的式子也表明,F1指标旨在降低FP和FN(即假阳性和假阴性)两者。
ROC 曲线(Receiver Operating Characteristic)
接收者操作特征曲线,是一种显示分类模型在所有分类阈值下效果的图表
此处先介绍两个指标
1,真正例率(TPR)--即召回率
2,假正例率(FPR)
与召回率相对应的,有一个叫做特异性(Specificity)的指标
表示在所有负样本中,模型准确找出的负样本比例。
由此可见,
我们当然希望TPR=1,FPR=0。
此时,正负样本均被正确分类
而ROC曲线的横纵坐标,分别是FPR(1-Specificity),TPR
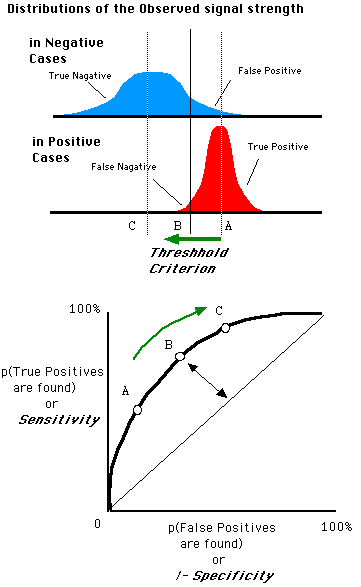
在做ROC曲线时,
首先,利用当前模型我们可以得到测试样本x对应的预测值f(x),这f(x)可以是连续值而非输出的标签值(可以认为是尚未送入函数的f(x))。
然后,把测试样本按照f(x)做升序排序
最后,对于排序后的样本及其f(x),依次顺序从大到小卡阈值把样本分为两组,小于阈值的一组判为负样本,大于阈值的一组为正样本。
一开始,把阈值设为最大,此时所有样本为负样本,TPR=FPR=0
然后逐渐减小阈值,TPR和FPR都升高,对于一个较好的模型,此时应该TPR>FPR>0
然后逐渐把阈值减到最小,此时所有样本为正样本,TPR=FPR=1
ROC曲线(0,1)点代表着完美的分类与阈值。所以曲线越接近这一点越好。
AUC (Area Under ROC Curve ROC曲线下面积)
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器
0.5 < AUC < 1,优于随机猜测。分类模型妥善设定阈值可以取得好的效果
AUC = 0.5,跟随机猜测一样
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
小结一下

由上图可见,
TPR=敏感度(Sensitivity)=召回率(Recall)=分母为正样本
FPR=1-特异性(Specificity)=分母是负样本
精确率(Precision)=分母是预测为正的样本
2,多分类模型的评价指标
混淆矩阵(Confusion Matrix)
| 真实类别1 | 真实类别2 | 真实类别3 | |
|---|---|---|---|
| 预测1 | 500 | 20 | 100 |
| 预测2 | 10 | 480 | 200 |
| 预测3 | 10 | 50 | 370 |
上表即混淆矩阵,详细描述了不同类别下样本预测情况。
由上表可以看出,样本分3个类别,每个类别样本分别520,550,670个。
那么此时,有一些指标可以评价多分类模型
ACC与平均ACC
ACC还是可以计算的,如上
平均ACC即各类别的准确率的平均
宏观与微观指标(Macro & Micro)
多分类混淆矩阵可以拆分成n个二分类混淆矩阵,如上可以拆分为如下3个
| 1 | 真实类别1 | 其他 |
|---|---|---|
| 预测为1 | 500 | 120 |
| 预测为其他 | 20 | 1100 |
| 2 | 真实类别2 | 其他 |
|---|---|---|
| 预测为2 | 480 | 210 |
| 预测为其他 | 70 | 980 |
| 3 | 真实类别3 | 其他 |
|---|---|---|
| 预测为3 | 370 | 60 |
| 预测为其他 | 300 | 1010 |
则可以按照二分类的方式获取3组指标,如ACC,Precision,Recall,F1等
甚至在获得预测样本每一类的概率值的情况下,做出3组ROC曲线
宏观指标Macro指算出上述3组指标之后,直接做平均
微观指标Micro指,把上述3表合成1张表,对应位置相加
| 4 | 真实类别 | 其他 |
|---|---|---|
| 预测为真实类别 | 1350 | 390 |
| 预测为其他 | 390 | 3090 |
通过这张表计算的指标如ACC,Precision,Recall,F1等,称为微观指标Micro
回归模型评价指标
回归模型评价指标通常会用到回归模型损失函数如MSE,MAE等
参考
ROC曲线
模型评估与实践
Macro与Micro