一、概述
最近有点时间,打算把前一阵子学习的目标检测相关的内容梳理一下。这个系列涉及到一些原理的回顾,简单的代码和实验结果,以及一些实际项目中有待解决的疑问。考虑到YOLO是像我这样的新手的最爱,所以本文——作为目标检测系列笔记的第一篇——就先从YOLO1的内容开始梳理。
众所周知,此前最成功的目标检测器都是分类模型的变体。无论是CNN或者级联弱分类器(如决策树)滑动窗也好,region proposal也好,它们的本质都是在每个不同尺度的可能区域上运行一个分类器。而YOLO最大的特点在于,其将目标检测任务从分类任务转变成回归任务,从而省去了region proposal'的过程,成为端到端的一阶检测器。
我们可以先试图从宏观上比较下两种检测模型:
①分类器变体的检测器,由于region proposal的存在,速度上存在天然的劣势。因此如果开发环境是嵌入式系统或者笔记本cpu,一般不会考虑使用。这里另外分享一个经验,也是我之前一直纠结的问题:YOLO3究竟能不能在笔记本cpu甚至是嵌入式系统上达到实时?根据上次张钊宁老师在极市直播中给出的说法是,没有问题。当然这个需要我们进行一番改造,直接拿着yolo主干网络肯定是不行的,至于tiny yolo,我自己只有一次不太成功的尝试经验。业界比较主流的说法是拿MobileNetV2等模型作为主干网络,参考上面的直播,张老师也分享了一些自己的改造tricks。另外前几天好像出来一篇论文就是MobileNet YOLO3,可能也是面向这一类应用场景。回头可以详细了解一下。
②Local context V.S. Global context. 由于分类器变体的检测器通常是在全图的子区域上进行分类,每次分类看到的图片context只是一个很小的区域,而YOLO送入每张图片进行检测时看到的总是整个图像,因此前者对应的是局部context,而YOLO对应的是全局的context。因此YOLO相比前一类检测器,将背景误判为目标的概率要小很多,即precision更高。
③候选区域的全面性。YOLO算法由于其对选区的固有限制,难免会漏掉一些较小的区域。因此YOLO对遮挡或者小目标的检测效果不如二阶检测器,即recall较低。
说了这么多,其实还是停留在直觉层面。更深入的理解还需要实验来佐证。在开始详细梳理YOLO算法之前,我想先做一个关于回归型检测器的简单实验——简单到什么程度呢,就是把一张图片送入模型,只输出4个坐标(即只有一种类别),以此来对目标进行localization。故这个模型与其说是检测器,不如说是定位器localizator。具体实验及分析见下一部分。
二、前戏——图像回归与检测任务
2.1. 理论介绍
这一部分以手部检测任务为例,最终目的是获得手部外接矩形框的四个坐标信息(左上+右下或者中点+宽高)。因此最直接的想法是,将输入图像通过CNN提取特征之后,直接将最后的特征图通过全连接层回归到一个特定维数的向量,如最简单的,每个图像回归到一个四维向量,分别代表 [x,y,w,h] 四个坐标信息。然后这四个预测的坐标信息和label中的四个坐标信息求简单的 l2loss,促使网络不断学习目标的位置。
在开始实验之前,我们可以先预料一下这个模型有哪些缺陷。首先,由于固定维度的FC层的使用,模型的输出一定是非常不灵活的。比如我们把上一段话中的任务扩展到多个类别和多个目标的场景:
假如每个目标可能属于三种类别,加上置信度,则该目标对应标签为3+1+4=8个维度。若图像中最多有三个目标,则FC层输出维度为3 * 8 = 24维。在此基础上训练网络模型。标签设置时,小于三个目标的样本图像,可以将后16个维度设为-1,即无意义。 但是当图像中出现多于三个目标时,该模型将无法检测额外的目标。因此,如果我们事先不知道目标的最大可能个数,我们就无法确定FC的输出维度。当然我们可以试着用一个很长的FC来覆盖一个很大目标数目的情况,理论上这样是可行的。除了增大一些计算量,这样做理论上有什么缺陷?其实我暂时也想不出来...感兴趣的同学可以尝试下。不过相信下面的实验结果已经足够说明localization的问题了。
另一个问题是,这个localizator能否较好得收敛从而在这个简单场景下带来较高的准确率?
2.2 实验
实验部分比较简单,考虑到任务非常单一,我使用了Gluon自带的resnet18模型作为骨干网络(有兴趣的同学可以尝试替换为稍微复杂点的模型)。从数据迭代器的准备到模型定义和训练的代码我都放在一个完整的notebook中,大家可以参考。
这里放一些实验结果(为了保护同事隐私,面部已打上马赛克):
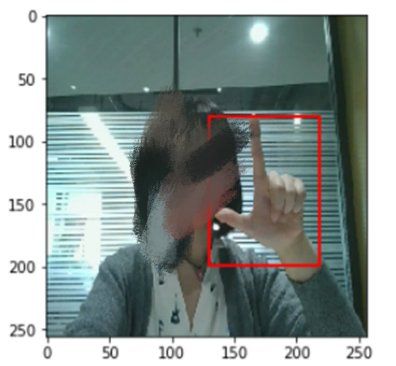




为了检查loss函数的约束能力,当时计算了上面预测样例与各自对应groundtruth box的l2loss值。上面五个样例的loss值依次为:
0.00031679,0.00040884, 0.00387251, 0.01736045, 0.00165691
对测试集大量样本进行上述观察发现:当loss小至0.001以下时,检测结果是可以接受的; 当loss大于0.01时,检测结果明显比较糟糕; loss在0.001 - 0.01之间的,一般看起来不是很完美但是也说的过去的.. 不过第三种结果出现的次数最多。
总结:loss的约束能力正常,即loss大的结果差,loss小的结果好。但是问题在于,loss很难进一步下降了。
2.3 分析
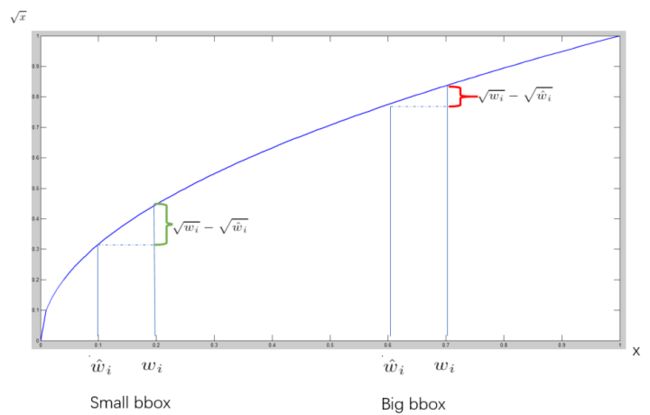
上面的localization 实验中存在的第一个明显的问题,就是未考虑大目标和小目标在计算loss时的差异。
考虑两种大小的box,假设其label和pred:①[0.4,0.5,0.6,0.6], [0.4,0.5,0.5,0.5] ②[0.4,0.5,0.1,0.1], [0.4,0.5,0.15,0.15]若直接使用l2loss:则①; ②。 即尺寸较小的box,loss明显小于loss较大的box。然而实际情况是,小box的相对偏移量更大: ①; ② 直接使用l1loss也同理。可见不考虑目标box的大小,直接回归相对坐标是不合理的。
针对这个问题,也有一些可行的解决方案。一种比较容易想到的方法,是对loss进行规范化:
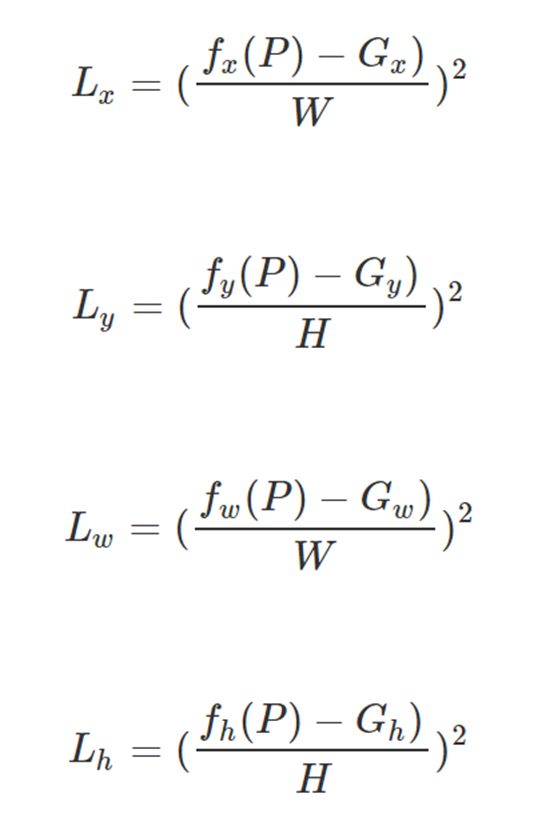
一种更加通用的方法是,修改regression target: 参考RCNN中的设置:(P是指proposed region。tw和th加了log,是为了避免w,h预测误差较大时,对loss起主导作用。如果中心坐标回归不准,宽高回归的再准也没用)。不过这个不适用于上面的实验,因为没有任何候选区的概念...
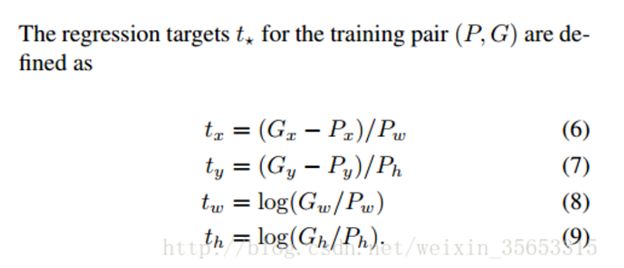
2.3 总结
本实验旨在了解Localization模型的性能。设定的任务场景非常简单,即检测图像中的单个手部,实验采用简单的resnet18模型作为骨干网络,将特征图回归到4维的向量,从而预测手部的位置。实验结果表明,该模型大体可以定位出手部的位置,但是由于loss函数和回归target的的简单设定,模型无法被迫使去根据不同大小目标之间的差异进行不同的惩罚,导致模型收敛的不好。此外,单个FC层作为模型的输出也降低了灵活性。
鉴于这些已经观察到的不足,我没有深入去改进localization实验结果。如果有感兴趣的同学,可以在上面提供的代码基础上进行简单的改进,然后分享下不同改进因素对模型的影响~这里我就直接跳到YOLO算法的介绍了!
三、YOLOv1
3.1 相关资源分享
关于YOLO1的分析,网上优质的资源很多,比如这篇知乎专栏文章,还有deepsystems.io的PPT。这里我就不详细介绍了,只是做一个简单的梳理。
3.2 概念梳理
对YOLO的理解其实主要是要把概念理清楚。具体来说不外乎下面几个概念:
- 输出维度;
- 区分grid cell, box以及feature space与image space(对于准备groudtruth,即回归目标很重要)
- "responsble", "exists"与"specialization"
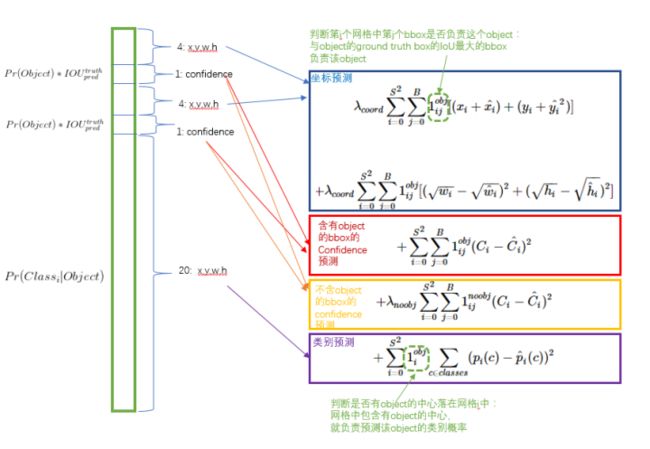
- 两个loss权重, ,三个loss成分(坐标、置信度、cell类别)
3.2.1 输出维度的含义
在第二部分中我们了解了最简单的回归检测模型——定位器。其一个特点是使用一个FC层输出所有可能box的信息。而YOLO则是将原图分为7 x 7个grid cells,并将每个grid cell回归至 维的向量。其中 2 代表每个grid cell上预测两个box;(4+1)代表四个bouding box信息加一个置信度信息:
这个置信度信息同时编码了当前cell有目标的概率以及两个输出box和该目标的IOU。最后20个维度代表20个类别的one-hot向量。 最后20维代表的不是20个类别的one-hot probability,而是conditional probability ,即假如这个cell中存在object,那么该object是每个类别的概率。论文中Fig. 2的下图也正是这个概率,比如橙色的格子是代表,如果该cell有目标,则该cell的目标是car。
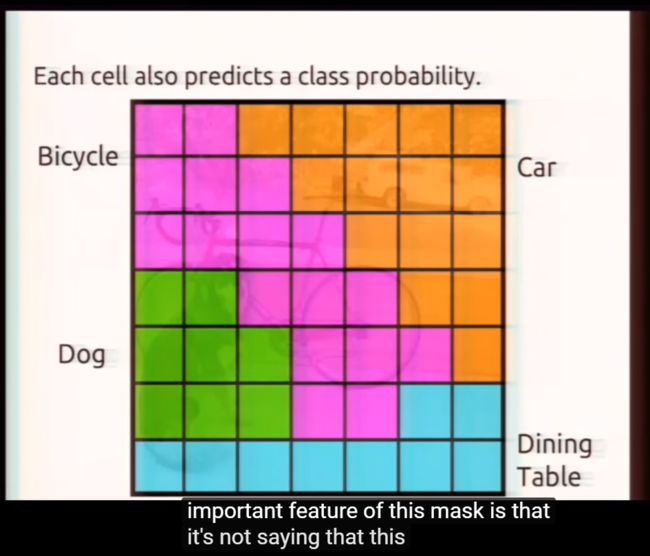
上述的一些细节见下图:

- 问题:两个FC的作用是什么?这里最后一个卷积层输出feature map可否直接通过一个1x1x30的Conv降维到7x7x30从而避免使用这两个FC?

3.2.2 区分grid cells与boxes pridictors,feature space与image space
YOLO论文中很多地方都出现了这样的字眼: "exists", "fall into",这些都是在强调,目标物体的中心落在某个cell中。即只有目标物体的中心所在的那个cell才认为是包含物体的,比如YOLO论文中那只狗,狗头等部位也占据了一些grid cell,但是这些cell并不认为包含了目标,这些cell上的box在设置regression targets时与那些空白的背景cell中的box并无二致。
- "If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object";
- "If no object exists in that cell, the confidence scores should be zero."
另一个需要仔细推敲的字眼是"responsible for"。YOLO虽然在每个grid上设置两个box,但是在训练时只让其中一个专门负责预测目标,即先比较输出的两个预测bounding box和groundtruth的IOU,IOU较大的那个box作为负责的box。论文中给出的解释是说,这样促使了两个bounding box之间的"specialization",从而每个box在预测特定尺寸、宽高比或者类别时效果更好,进而提高了整体的recall。

我其实完全没有理解这个说法,希望能得到更具体的解释。
3.2.3 feature space 与image space
这两个概念在yolo1中体现的没那么明显,在yolo2中涉及到anchor和一些相关的parameterization时会有非常重要的意义,到下一篇博客时我再结合代码详细梳理一下。当前我们只需要知道一个地方,就是Fig. 9.中,x/y和w/h的设置,不是用绝对的坐标值和宽高:x,y为目标中心点在该grid cell中的相对位置;w,h为groundtruth box相对于整个图像的比例。
3.2.4 两个loss权重和三个成分
上面分享的链接中已经对这部分做了详细的描述。这里我简单梳理下:
- 首先是三个loss成分:coordinate error,confidence error和class probability error。
① 每个grid cell只预测一个类别,因此class probability error和box无关,只对有目标的cell计算就行;
原文说的是:Note that the loss function only penalizes classification error if an object is present in that grid cell (hence the conditional class probability discussed earlier).
② coordinate error: 在包含目标的cell中,只惩罚IOU最大的那个box predictor。也就是说如果图中有三个目标,那么只有三个box predictor参与这部分计算。其他个box predictor都不对其回归的坐标位置进行adjust。
③ confidence error: 计算所有98个box的confidence error。
- 两个权重:
首先我们看看为啥要设置这两个权重。如果我们也像第二部分的Localizator那样直接对预测tensor和label tensor求sum-squared error,有两个明显的问题:一,最简单的,对于每个cell输出30维度,class probability相关的就有20维,box相关的只有8维。如果将每个维度一视同仁求l2 loss,类别损失在整体损失函数中显然占据上风,进而在反向传播中占据主导地位;二是98个box都参与confidence error的计算,但是只有三个是正样本,其他95个都是负样本。如果在计算这部分loss时对所有样本一视同仁,和上面类似,负样本的confidence loss会占据绝对的主导地位,从而导致正样本在反向传播时几乎没有梯度。
所以两个权重的作用就很清晰了:是为了平衡坐标损失和置信度损失之间的不均衡;而则是为了平衡正负box样本在求置信度损失时的不均衡。
上述概念基本上涵盖了yolo损失函数的主要部分。见下图:
还有个值得注意的细节,就是对于不同尺寸box样本的坐标偏移量给于不同的惩罚,也就是第二部分Localization实验中我们遇到的一个问题:相同的绝对偏移量,小样本的相对偏移要比大样本严重得多。YOLO v1中给出的解决办法是使用平方根,这确实是一个蛮简单精巧的设置,下图直观地展示了平方根的效果:(不过好像事实上这个设置太过简单,不能根本上解决问题)
3.3 YOLO evaluation
测试的过程上面的PPT写的非常清晰,需要注意的是,首先要将每个box的Confidence和class probability相乘,得到每个box的confidence score,其维度为


接下来对每个category类别逐一进行NMS,在最终的box中找到非零score的box,绘制到图中,其最大score对应下标即为类别。
3.4 YOLO training
YOLO训练过程最大的挑战在于,如何将groundtruth box(即原始label)转换至和我们所要的网络输出一致的,7730的形式,或者说如何把原始label assign到各个grid cell中去。这一部分内容相对比较琐碎,我把它放在下一篇博客中,和anchor的改进结合在一起记录。
不过作者这个presentation中的讲解关于训练的部分讲的蛮清楚,有必要记录下,短短几句话就涵盖了yolo 回归目标(target)以及loss的设置:
作者首先提到,找到目标物中心所在的cells,然后定好class labels,比如下图中狗对应1,其他19个类别对应0。然后作者说要对每个有目标的cell中的box进行adjust: 对于IOU大的box predictor,"increase its confidence and adjust its coordinates";对于该grid cell预测的其他boxes,"decrease their confidence since they don't overlap the object."
我觉得理解这里的adjust非常有意义。比如“对于IOU大的box,增大其置信度”,意味着①loss要对其进行约束②其置信度标签应该是1;而“对于IOU小的其他boxes(不一定一个cell只给出两个box predictors),减小其置信度”同样意味着:①loss要对这些boxes也进行约束②其置信度标签应该是0。

四、问题整理
对于Fig. 16中那个小虚线box所代表的一类box来说,它们的坐标并没有收到loss的约束进而不断地"adjust",那么是否可以认为,对于这张图而言,模型完全依赖三个负责的box给出准确的预测结果,其他95个box的confidence受到抑制,因此它们的坐标完全是干扰,没有任何价值?
两个FC层的作用?可否换成1x1 Conv减小参数?
每个grid cell只使用一个box作为负责的box,论文中说这样“促使了两个bounding box之间的"specialization",从而每个box在预测特定尺寸、宽高比或者类别时效果更好,进而提高了整体的recall”,应该如何理解?
有篇关于YOLO的文章基本读不懂..也记录在这里:
https://christopher5106.github.io/object/detectors/2017/08/10/bounding-box-object-detectors-understanding-yolo.html
五、参考:
定位器代码: https://nbviewer.jupyter.org/github/cy810557/chiyuan/blob/master/Projects/HobotProjects/Hand_Detector/Experiment_Localizator/%E7%9B%AE%E6%A0%87%E5%AE%9A%E4%BD%8D%E5%99%A8.ipynb
知乎文章: https://zhuanlan.zhihu.com/p/24916786
PPT: https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.p
作者CVPR演讲视频:https://www.youtube.com/watch?v=NM6lrxy0bxs&feature=youtu.be
B站讲解视频:https://www.bilibili.com/video/av41036172from=search&seid=3486837237199793282