基于深度学习的图像分割的方法的一般套路:
1.下采样 + 上采样,卷积池化转置卷积;
2.多尺度特征拼接,低维度特征结合高维度特征;
3.获得像素级别的segement map,即对每个像素进行分类。
在做反卷积上采样的时候,往往通过拼接融合的方法得到更多的信息,拼接的方法有
语义分割网络在特征融合时也有2种办法:
- FCN式的逐点相加,对应caffe的EltwiseLayer层,对应tensorflow的tf.add()
- U-Net式的channel维度拼接融合,对应caffe的ConcatLayer层,对应tensorflow的tf.concat()
获得mutli-scale-context的几种方法:
(a)图像金字塔。输入图像进行尺度变换得到不同分辨率input,然后将所有尺度的图像放入CNN中得到不同尺度的分割结果,最后将不同分辨率的分割结果融合得到原始分辨率的分割结果,类似的方法为DeepMedic;
(b)编码-解码。FCN和UNet等结构;
(c)本文提出的串联结构。
(d)本文提出的Deeplab v3结构。最后两个结构右边其实还需要8×/16×的upsample,在deeplab v3+中有所体现。下采样GT容易在反向传播中丢失细节,因此上采样feature map效果更好。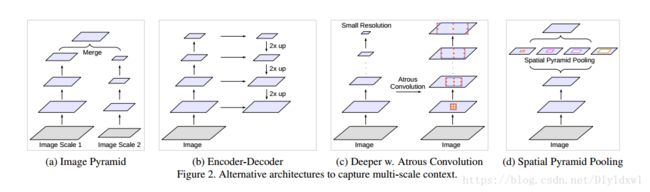
图像分割一般采用深度学习模型+概率图模型
FCN以及deeplab后面加入的条件随机场crf就是一种概率图模型;
CRF是对像素级别的 label 预测,将像素 label 作为随机变量,周边像素与像素间的关系作为边,构成一个条件随机场,且能够获得全局观测时,CRF便可以对这些label进行建模。
也就是在考虑一个像素的label时,同时考虑周边像素的影响,能够抹除一些噪音。
CRF是后处理,是不参与训练的,在测试的时候对feature map做完CRF后,再双线性插值resize到原图尺寸,因为feature map是8s的,所以直接放大到原图是可以接受的。
参考自:https://blog.csdn.net/Dlyldxwl/article/details/81148810