前言
Ok,我们经过了前面两篇链表的理论与实践之后,我们需要检验一下实现的LinkedList有那些性能上需要改进的,本篇是前两篇随笔内容的延申,如果你还没有阅读之前的内容,请查看如下内容
- 《第2篇 C++ 数据结构-链表概述》
- 《第2篇 C++ 数据结构-单链表(多图杀猫)》
由于我们的LinkedList是由C++写的,那么C++程序的性能测试方法,可以查看这篇随笔《C++ 基本的性能测试方法》
push_back方法测试
LinkedList list;
std::cout << "push_back方法测试" << std::endl;
for (int i = 0; i < 15; i++)
{
list.push_back(i);
}
std::cout << list << std::endl;
std::cout << "此时list的尺寸是" << list.size() << std::endl;
std::cout << "" << std::endl;
输出结果,Ok证明方法是work的!

push_head方法测试
以下测试代码是承接上面的示例代码的
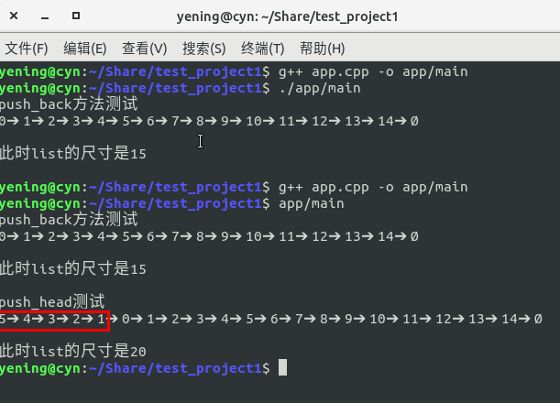
std::cout << "push_head测试" << std::endl;
for (auto j = 1; j <= 5; j++)
{
list.push_head(j);
}
std::cout << list << std::endl;
std::cout << "此时list的尺寸是" << list.size() << std::endl;
输出结果,Ok证明方法是work的!
search方法测试
//查找元素测试
std::cout << "search方法测试" << list.search(11) << std::endl;
std::cout << "search方法测试" << list.search(5) << std::endl;
std::cout << "search方法测试" << list.search(20) << std::endl;
输出结果,也是work的!这里值的注意的是如果找不到元素,那么search方法会返回一个nullptr指针,C++的nullptr带有隐式转换为bool数据类型的特性,所以最后一个输出是0而不是16进制形式的内存地址。

insert方法测试
std::cout << "insert方法测试,在索引2的位置插入100" << std::endl;
list.insert(2, 100);
std::cout << "insert方法测试,在索引10的位置插入172" << std::endl;
list.insert(10, 172);
std::cout << "insert方法测试,在索引15的位置插入602" << std::endl;
list.insert(15, 602);
std::cout << list << std::endl;
last方法和reverse方法测试
std::cout << "list中的last():" << list.last() << std::endl;
std::cout << "reverse方法测试" << std::endl;
list.reverse();
std::cout << list << std::endl;
输出结果:从程序输出逻辑上没啥毛病

Ok,我们仅列出上面接口的测试,其中一个值的我们注意的是,单项链表的增/删/改/查这四项基本操作都是围绕一个痛点就是那时间复杂度为O(n)的 遍历操作,因此我们本篇剩下的篇幅会唯一这个问题改善,我们要尽可能地避免不必要的遍历操作。
迭代接口测试
void test_iterator()
{
LinkedList list;
for (auto i = 0; i < 20; i++)
{
list.push_back(i + 1);
}
for (LinkedList::Iterator it = list.begin(); it != list.end(); it++)
{
std::cout << *it << " ";
}
std::cout << std::endl;
}
输出结果
重提遍历操作
线性表的数据结构,有个特性就是每个元素逻辑上都是依次排列的,那么加快遍历操作就显得尤为重要,遍历的目地是为了获取或插入特特定的元素项。
- 二分查找算法(对半查找法):这种方法适用于按值降序或升序排列的线性表。我们这里暂时不太适用
- 指针缓存法:C++的容器顺序表高效的原因之一就是大量使用了这种方法
性能问题导入
我们从一个示例开始吧,首先我们拿push_back开刀,我们知道它理论上的时间复杂度是O(n),我们将上面的push_back示例代码修改一下,我们将调用代码的遍历数量级放大40000,如下代码所示:
LinkedList list;
std::cout << "push_back方法测试" << std::endl;
for (int i = 0; i < 40000; i++)
{
{
Timer timer;
list.push_back(i);
}
}
std::cout << "此时list的尺寸是" << list.size() << std::endl;
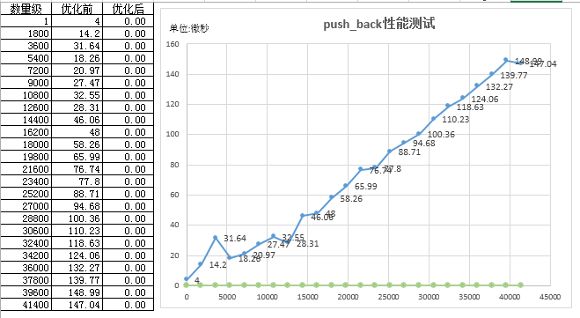
我写本文的时,将执行了40000次的耗时数据导入到一个文本,我们对数据执行格式化后转换为csv格式的文本,再使用python的pandas读取该csv数据源,我们这里以每1800次为区间统计每个连续区间内的平均耗时后得出如下图标。

性能优化--指针缓存法
情况正如我们所料的非常糟糕,现在我们可以对push_back方法和LinkedList类接口进行一定程度上的重构,我们希望push_back能够像vector和ArrayList那样高效,每次时间复杂度为O(1).我们在类接口中不妨声增加一个私有的数据成员用于在调用者函数生命周期内,缓存我们链表中的末端节点的内存地址,我们将该数据成员声明为d_last,这样我们每次调用push_back方法时,去直接访问该数据成员直接得到链表最后一个节点的地址,而不是每次都执行遍历至最后一个节点。重构代码如下:
LinkedList类接口的修改很简单,我就不贴出代码了
push_back方法的优化版本
//末端插入操作
template
void LinkedList::push_back(T val)
{
Node *tmp = new Node(val);
tmp->d_next = nullptr;
//判断链表是否为空
if (d_head == nullptr)
{
tmp->d_data = val;
d_head = tmp;
d_last = tmp;
}
else
{
d_last->d_next = tmp;
d_last = tmp;
}
++d_size;
}
惯例我们还要测试我们优化后的push_back能否如我们所愿正常工作?Ok,我们先测试个10个元素的push_back~!!测试是没问题的,
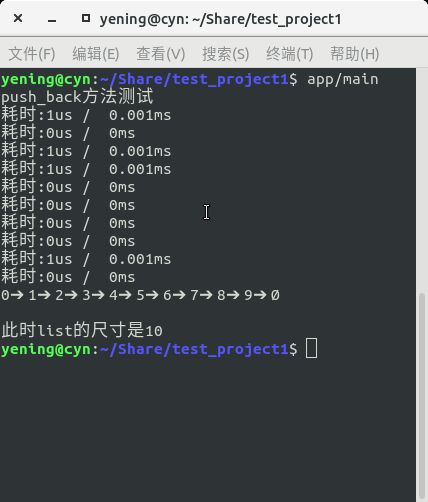
这次,我们再调用之前40000个元素的示例代码,记得将那些打印变量list的测试代码删掉。我们需要的是Timer计时器的测试数据。
编译程序后,如下代码
g++ app.cpp -o app/main
由于测试的次数数量级比较庞大。我们最好将Timer类的测试数据重定向到一个文本文件中。例如
app/main > ./test.txt
我们重重定向到文本的时间数据看看我们Timer计时器类输出的耗时,哇塞,很棒!!40000次的push_back调用每次好事接近0微妙,Ok,这就是应验了数据结构和算法学科里面的一条铁律---“空间消耗换取最低的时间消耗”,我们这里仅仅是增加了8字节的内存消耗就获得了非常高效的性能收益。
push_back优化前/后性能测试对比
这是我们测试最后想要的结果O(1)就是一个常量的水平直线。
我们前文已经提到一个假设问题,我希望为LinkedList提供类似ArrayList高效的 索引访问操作符[],但是索引访问和随机位置的插入/删除操作都是O(n)的时间复杂度,他们的本质上都需要通过遍历操作以及一个计数器作为判断条件是否跳出遍历操作。曾经也想过在LinkedList缓存中间节点,但这种想法也非常具有局限性的,因为这种方法只能适用于后半段链表(从中间节点开始到末端节点)的操入操作。但对于前半段链表的任何插入/删除,缓存的中间节点,由于已经移位会失效,重新遍历链表缓存中间节点的地址,更是得不尝失。因此中间节点缓存的方法对于单链表是没有现实意义的。

所有随机插入/删除操作,归根到底都需搜索链表,因此您需要从头开始逐一迭代,因此它的时间复杂度始终是O(n)。 如果将链表用于搜索,它并不是最佳选择,用于搜索应用更合适的数据结构是二叉树。
在无序列表中,一种用于减少平均搜索时间的简单试探法是移至最前的试探法,该试探法将元素一旦找到就简单地移动到列表的开头。 此方案方便创建简单的缓存,可确保最近使用过的项目也能最快找到。
另一种常见的方法是使用更有效的外部数据结构“索引”链接列表。 例如,可以构建一个红黑树(Red-Black Tree)或哈希表(Hash Table),其元素是对链接列表节点的引用。 可以在单个列表上构建多个此类索引。 缺点是,每次添加或删除节点时(或至少在再次使用该索引之前),可能都需要更新这些索引。
小结
我们单链表的最佳的实现其实就是得到如下结果。

下一篇,会继续讨论已排序的链表