新版效果统计数据在Cassandra已经运行两年了,目前随着维度的拓展以及业务的增长,Cassandra存储的数据量累计已接近2T,风和日丽后的第一场暴风雨终于来临
问题
12月10日下午2点,服务突然无响应,业务线接口出现大量超时,经过定位分析,发现是Cassandra查询请求大量阻塞,进一步观察日志发现是Cassandra多分区查询引起的, 虽然这个问题是由业务线的一个小bug引起的(一个in查询包含2w个元素),但同时也暴露出了我们底层服务的瓶颈问题
- 什么是多分区查询
我们假设id是users表中的分区主键,存储了id为1、2、3、4的4条数据,极端情况下,4条数据会被分配到4个分区进行存储(但也可能在1个分区里),我们假设数据不在一个分区内,然后通过下面的语句一次查询出这4个用户的方式就是多分区查询。
SELECT * FROM my_keyspace.users where id in (1,2,3,4)
- 什么是固定分区查询
假设order表中有uid, day ,productid三个字段,uid为分区键,day为排序键;我们通过下面SQL在订单表查询出用户1在某几日的消费详情,虽然这里也用到了in操作,但因为指定了uid为1,所以查询请求会只命中一个分区。
SELECT * FROM my_keyspace.orders where uid = 1 and day in ('2019-11-11','2019-11-12','2019-11-13')
分析
假设将A,B,C三条数据存储在一个9节点3副本的集群里,当我们使用SELECT * FROM mykeyspace.mytable WHERE id IN (‘A’,’B’,C’)这样一个查询时,Cassandra的处理机制是这样的:
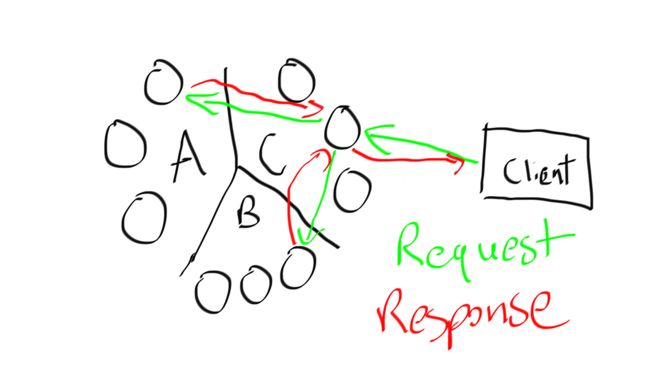
客户端与服务端建立同步请求,服务端会根据平衡策略在9台节点中选择一个节点作为调制协调器,负责解析SQL并将请求转发到其它节点,然后拉取对应数据到协调器节点,协调器存储了查询关系和每个数据节点返回的数据,正常情况下当协调器节点获取所有数据后会返回到客户端,相应的如果协调器发生故障,整个查询将根据配置的重试略重新开始请求。
一版情况下多分查询是不会有任何问题的,Cassandra都能够很快的将结果进行返回,但随着业务的变动和数据增长,一次需要查询的分区主键元素会变多,相应的Cassandra需要检索的分区数量也会变大,这样会消耗更多的堆空间,并引发频繁GC导致集群可用性下降。
优化
主要优化方式是将上面请求改为固定分区异步并发请求,上面的SQL为改成下面这种方式多次请求服务端
SELECT * FROM mykeyspace.mytable WHERE id = 'A';
SELECT * FROM mykeyspace.mytable WHERE id = 'B';
SELECT * FROM mykeyspace.mytable WHERE id = 'C';
看到反人类的操作 着实让我震惊了一把,这么做不应该更慢吗?看似不合理的操作实则内有玄机。
首先,客户端会与服务端建立session会话,每个session会根据服务器情况设置对应数量的连接池,每个连接池会与服务器建立若干连接,每个连接都是异步的(采用netty异步双工技术实现),所以一个连接是可以同时发出多个请求的,在发送下一个请求前不需要等待上一个请求的完成
这种查询还有另一个好处 它不存单一的协调器节点了,查询分摊到了多个cassandra节点上,充分利用了集群的CPU和内存资源

- 什么是会话
session是连接的管理,提供了丰富的通信API,如 session.executeAsync;也可以通过session监控正在处理的请求以及服务器的状态 session.getState
3.x
PoolingOptions poolingOptions = new PoolingOptions();
poolingOptions
.setConnectionsPerHost(HostDistance.LOCAL, 16, 40)
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32768);
Cluster.Builder clusterBuilder = Cluster.builder()
.addContactPoints(
""
)
.withPoolingOptions(poolingOptions)
.withLoadBalancingPolicy(new RoundRobinPolicy())
.withPort(9042);
Session session = cluster.build().connect();
4.x
Session session = CqlSession.builder().build();
#连接方式与平衡策略放在application.conf,并存放在classpath目录下
datastax-java-driver {
basic.contact-points = ["127.0.0.1:9042"]
basic {
load-balancing-policy {
local-datacenter = datacenter1
}
}
- 什么是连接池
连接池是连接的集合,可指定连接池大小范围,当连接闲置时间过长时会被自动关闭,直到配置的最小值
PoolingOptions poolingOptions = new PoolingOptions();
poolingOptions.setConnectionsPerHost(HostDistance.LOCAL, 16, 40)
- 什么是连接
与Cassandra实际通信的是连接,每个连接就是一个netty的异步通信,因为是异步处理的所以每个连接可通过executeAsync方法发送多个request请求(最大支持32K个请求,超出将会阻塞),每个request会生成唯一ID,并返回Future对象(java8异步作业句柄)当所有请求发送完毕后,连接通过ID获取服务端返回的数据
客户端提供了丰富的配置及优化策略 如失败重试策略等。篇幅有限这里就不一一列举了
一个完整的例子
import com.datastax.driver.core.*;
import com.datastax.driver.core.policies.RoundRobinPolicy;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
public class CassandraTest {
public static void main(String[] args) throws IOException {
String ids = "";
InputStream is = CassandraTest.class.getClass().getResourceAsStream("/ids.txt");
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String[] idArray = ids.split(",");
System.out.println(idArray.length);
PoolingOptions poolingOptions = new PoolingOptions();
poolingOptions
.setConnectionsPerHost(HostDistance.LOCAL, 16, 40)
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32768);
Cluster.Builder clusterBuilder = Cluster.builder()
.addContactPoints(
// 有几个写几个 " "
)
.withPoolingOptions(poolingOptions)
.withLoadBalancingPolicy(new RoundRobinPolicy())
.withPort(9042);
Cluster cluster = null;
try {
cluster = clusterBuilder.build();
Session session = cluster.connect(); // 整个客户端共享一个session 看起来比较重
//如果只请求一次 可以使用SimpleStatement
PreparedStatement statement = session.prepare(
"select id,pv,uv,spv,fpv from bigdata.data where id = ? and product='tk' and day in('2019-12-10','2019-12-09','2019-12-08','2019-12-07','2019-12-06','2019-12-05','2019-12-04','2019-12-03')");
List futures = new ArrayList<>();
long start = System.currentTimeMillis();
for (String id : idArray) {
ResultSetFuture resultSetFuture = session.executeAsync(statement.bind(id.trim()));
futures.add(resultSetFuture);
}
List results = new ArrayList<>();
for (ResultSetFuture future : futures) {
ResultSet rows = future.getUninterruptibly();
results.addAll(rows.all());
}
System.out.println(System.currentTimeMillis() - start);
System.out.println(results.subList(1, 5));
System.out.println(results.size());
} catch (Exception e) {
e.printStackTrace();
}
}
}
写在最后
多分区数据查询是比较消耗性能的,类似的还有allow filtering无法查询,如果需要一次查询的分区键元素数量不是很多,固定分区遍历查询与In关键字查询性能区别不是很大,在我们当前业务环境中通过测试发现,当一次查询元素个数超过1000时固定分区查询性能提升2倍,3000-5000时性能提升3-5倍,待查询的元素个数越多性能提升越明显,整体来看有3-10倍的性能提升,但响应时间也会相应变长。