1.强化学习资源
函数库
1、RL-Glue:提供了一个能将强化学习代理、环境和实验程序连接起来的标准界面,且可进行跨语言编程。
地址:http://glue.rl-community.org/wiki/Main_Page
2、Gym:由OpenAI开发,是一个用于开发强化学习算法和性能对比的工具包,它可以训练代理学习很多任务,包括步行和玩乒乓球游戏等。
地址:https://gym.openai.com/
3、RL4J:是集成在deeplearning4j库下的一个强化学习框架,已获得Apache 2.0开源许可。
地址:https://github.com/deeplearning4j/rl4j
4、TensorForce:一个用于强化学习的TensorFlow库。
地址:https://github.com/reinforceio/tensorforce
论文集
1、用通用强化学习算法自我对弈来掌握国际象棋和将棋
题目:Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
地址:https://arxiv.org/abs/1712.01815
这篇文章有13位作者,提出了AlphaZero方法。在这篇论文中,作者将先前的AlphaGo Zero方法推广到一个单一的AlphaZero算法,它可以在多个具有挑战性的领域实现超越人类的性能,同样利用的是“白板”强化学习(“白板”指的是所有知识均由感官和经验得来,即从零开始的学习)。从随机下棋开始,除了游戏规则外,没有输入任何领域知识,AlphaZero在24小时内实现了在国际象棋、将棋和围棋上超越人类水平的表现,并且在这三种棋上都以令人信服的成绩击败了当前的世界冠军程序。
2、深化强化学习综述
题目:Deep Reinforcement Learning: An Overview
地址:https://arxiv.org/abs/1701.07274
这篇论文概述了深度强化学习中一些最新精彩工作,主要说明了六个核心要素、六个重要机制和十二个有关应用。文章中先介绍了机器学习、深度学习和强化学习的背景,接着讨论了强化学习的核心要素,包括DQN网络、策略、奖励、模型、规划和搜索。
3、用深度强化学习玩Atari游戏
题目:Playing Atari with Deep Reinforcement Learning
地址:https://arxiv.org/abs/1312.5602
这是DeepMind公司2014年的NIPS论文。这篇论文提出了一种深度学习方法,利用强化学习的方法,直接从高维的感知输入中学习控制策略。该模型是一个卷积神经网络,利用Q-learning的变体来进行训练,输入是原始像素,输出是预测未来奖励的价值函数。此方法被应用到Atari 2600游戏中,不需要调整结构和学习算法,在测试的七个游戏中6个超过了以往方法并且有3个超过人类水平。
4、用深度强化学习实现人类水平的控制
题目:Human-Level Control Through Deep Reinforcement Learning
地址:https://web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf
这是DeepMind公司2015年的Nature论文。强化学习理论根植于关于动物行为的心理学和神经科学,它可以很好地解释代理如何优化他们对环境的控制。为了在真实复杂的物理世界中成功地使用强化学习算法,代理必须面对这个困难任务:利用高维的传感器输入数据,推导出环境的有效表征,并把先前经验泛化到新的未知环境中。
讲座教程
1、强化学习(Georgia Tech, CS 8803)
地址:https://www.udacity.com/course/reinforcement-learning—ud600
官网介绍:如果你对机器学习感兴趣并且希望从理论角度来学习,你应该选择这门课程。本课程通过介绍经典论文和最新工作,带大家从计算机科学角度去探索自动决策的魅力。本课程会针对单代理和多代理规划以及从经验中学习近乎最佳决策这两个问题,来研究相应的高效算法。课程结束后,你将具备复现强化学习中已发表论文的能力。
2、强化学习(Stanford, CS234)
地址:http://web.stanford.edu/class/cs234/index.html
官网介绍:要实现真正的人工智能,系统要能自主学习并做出正确的决定。强化学习是一种这样的强大范式,它可应用到很多任务中,包括机器人学、游戏博弈、消费者建模和医疗服务。本课程详细地介绍了强化学习的有关知识,你通过学习能了解当前面临问题和主要方法,也包括如何进行泛化和搜索。
3、深度强化学习(Berkeley, CS 294, Fall 2017)
地址:http://rll.berkeley.edu/deeprlcourse/
官网介绍:本课程需要一定的基础知识,包括强化学习、数值优化和机器学习。我们鼓励对以下概念不熟悉的学习提前阅读下方提供的参考资料。课堂上开始前会简单回顾下这些内容。
4、用Python玩转深度强化学习(Udemy高级教程)
地址:https://www.udemy.com/deep-reinforcement-learning-in-python/
官网介绍:本课程主要介绍有关深度学习和神经网络在强化学习中的应用。本课程需要一定的基础知识(包括强化学习基础、马尔可夫决策、动态编程、蒙特卡洛搜索和时序差分学习),以及深度学习基础编程。
最后,原文地址在此:https://blog.algorithmia.com/introduction-to-reinforcement-learning/
2.实践挑战
强化学习的应用前景十分光明,但是实践道路会很曲折。
第一是数据问题。强化学习通常需要大量训练数据才能达到其他算法能高效率达到的性能水平。DeepMind最近提出一个新算法,叫做RainbowDQN,它需要1800万帧Atari游戏界面,或大约83小时游戏视频来训练模型,而人类学会游戏的时间远远少于算法。这个问题也出现在步态学习的任务中。
强化学习在实践中的另一个挑战是领域特殊性(domain-specificity)。强化学习是一种通用算法,理论上应该适用于各种不同类型的问题。但是,这其中的大多数问题都有一个具有领域特殊性的解决方案,往往效果优于强化学习方法,如MuJuCo机器人的在线轨迹优化。因此,我们要在权衡范围和强度之间的关系。
最后,在强化学习中,目前最迫切的问题是设计奖励函数。在设计奖励时,算法设计者通常会带有一些主观理解。即使不存在这方面问题,强化学习在训练时也可能陷入局部最优值。
上面提到了不少强化学习实践中的挑战问题,希望后续研究能不断解决这些问题。
3.强化学习几要素
本文用电子游戏来理解强化学习(Reinforcement Learning, RL),这是一种最简单的心智模型。恰好,电子游戏也是强化学习算法中应用最广泛的一个领域。在经典电子游戏中,有以下几类对象:
代理(agent,即智能体),可自由移动,对应玩家;
动作,由代理做出,包括向上移动和出售物品等;
奖励,由代理获得,包括金币和杀死其他玩家等;
环境,指代理所处的地图或房间等;
状态,指代理的当前状态,如位于地图中某个特定方块或房间中某个角落;
目标,指代理目标为获得尽可能多的奖励;
上面这些对象是强化学习的具体组成部分,当然也可仿照得到机器学习的各部分。在强化学习中,设置好环境后,我们能通过逐个状态来指导代理,当代理做出正确动作时会得到奖励。
4.决策过程
强化学习中的决策(Decision Making),即如何让代理在强化学习环境中做出正确动作,这里给了两个方式。
策略学习
策略学习(Policy Learning),可理解为一组很详细的指示,它能告诉代理在每一步该做的动作。这个策略可比喻为:当你靠近敌人时,若敌人比你强,就往后退。我们也可以把这个策略看作是函数,它只有一个输入,即代理当前状态。但是要事先知道你的策略并不是件容易事,我们要深入理解这个把状态映射到目标的复杂函数。
用深度学习来探索强化学习场景下的策略问题,这方面有一些有趣研究。Andrej Karpathy构建了一个神经网络来教代理打乒乓球(http://karpathy.github.io/2016/05/31/rl/)。这听起来并不惊奇,因为神经网络能很好地逼近任意复杂的函数。
乒乓球
Q-Learning算法
另一个指导代理的方式是给定框架后让代理根据当前环境独自做出动作,而不是明确地告诉它在每个状态下该执行的动作。与策略学习不同,Q-Learning算法有两个输入,分别是状态和动作,并为每个状态动作对返回对应值。当你面临选择时,这个算法会计算出该代理采取不同动作(上下左右)时对应的期望值。
Q-Learning的创新点在于,它不仅估计了当前状态下采取行动的短时价值,还能得到采取指定行动后可能带来的潜在未来价值。这与企业融资中的贴现现金流分析相似,它在确定一个行动的当前价值时也会考虑到所有潜在未来价值。由于未来奖励会少于当前奖励,因此Q-Learning算法还会使用折扣因子来模拟这个过程。
策略学习和Q-Learning算法是强化学习中指导代理的两种主要方法,但是有些研究者尝试使用深度学习技术结合这两者,或提出了其他创新解决方案。DeepMind提出了一种神经网络(https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf),叫做深度Q网络(Deep Q Networks, DQN),来逼近Q-Learning函数,并取得了很不错的效果。后来,他们把Q-Learning方法和策略学习结合在一起,提出了一种叫A3C的方法(https://arxiv.org/abs/1602.01783)。
把神经网络和其他方法相结合,这样听起来可能很复杂。请记住,这些训练算法都只有一个简单目标,就是在整个环境中有效指导代理来获得最大回报。
5.强化学习算法分类
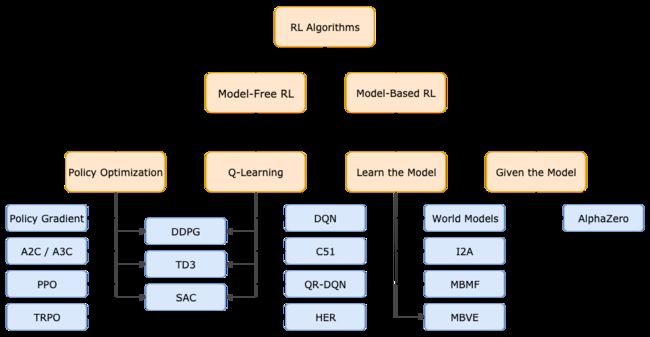
由于强化学习是一个更新速度非常快的领域,所以准确地全面地分类是相当困难的,Spinning up 项目组给出的这个分类虽然并不全面,但是对初学者来说是非常有用了。
可以看出强化学习可以分为Model-Free(无模型的) 和 Model-based(有模型的) 两大类。Model-Free 又分成基于Policy Optimization(策略优化)和Q-learning。Model-based 又分为模型学习(Learn the Model)和给定模型(Given the Model)两大类。
部分算法的全名和论文链接见文末附录
2. Model-Free vs Model-Based
在之前的文章也阐述过两者的区别,当时主要是以引入Model-based的算法的角度简略地比较了两者的优劣。Spinning up 项目组也对两者的区别和优劣做了系统的比较。
两个算法的区别主要是Agent是否知道或要计算出环境的模型。
拥有模型的好处是:Agent可以根据模型看到会发生什么,并提前规划(Planning)行动路径。
拥有模型的坏处是,真实模型和学习到带模型是有误差的,这种误差会导致Agent虽然在模型中表现很好,但是在真实环境中可能打不到预期结果。
Model-Free的算法往往更易于实现和调整,截止到目前(2018年9月),Model-Free的算法更受欢迎。
3. 要学习什么(学习对象)
RL学习的内容无非是如下几个方面
策略,不管是随机的还是确定性的
行动价值函数(Q (s,a))
值函数(V(s))
环境模型
3.1. Model-Free 学习对象
Spinning Up 项目组就是根据学习的对象分成Policy Optimization(对象是策略),和Q-Learning(对象是Q(s,a))的。
(1) Policy Optimization
基于策略的强化学习就是参数化策略本身,获得策略函数πθ(a|s), 我们训练策略函数的目标是什么呢?是获得最大奖励。优化策略函数就是优化目标函数可以定义为J(πθ).
Policy Optimization 通常是on-policy的,也就是每次更新策略采用最新策略产生的数据。
Policy Optimization的经典例子包含A2C / A3C,和PPO。
(2) Q-Learning
Q-Learning 就是通过学习参数化Q函数Qθ(s,a)从而得* 到最优Q*(s,a)的。
典型地方法是优化基于Bellman方程的目标函数。
Q-Learning 通常是Off-Policy的,这就意味着训练的数据可以是训练期间任意时刻的数据。
Q-Learning 的经典例子包含DQN和C51。
3.2. Policy Optimization和Q-Learning 的权衡与融合
Policy Optimization直接了当地优化你想要的对象(策略),因此Policy Optimization稳定性和可信度都较好,而Q-learning是采用训练Qθ的方式间接优化策略,会遇到不稳定的情况。但是Q-learning的优点是利用数据的效率较高(Off-policy的原因?)
Policy Optimization和Q-Learning并非水火不相容,有些算法就融合和平衡了两者的优缺点:
DDPG, 同时学出一个确定性策略和Q函数,并用他们互相优化。
SAC是一种变体,它使用随机策略、熵正则化和一些其它技巧来稳定学习,同时在 benchmarks 上获得比 DDPG 更高的分数。
4. Model-Based RL学习对象
Model-Based RL不像Model-Free RL那样容易分类,很多方法都有交叉。Spinning up 项目组给出了几个例子,但他们也声称这些例子是无法全部覆盖Model-Based强化学习的,这些例子中模型要么是已知给定的,要么是通过学习得到的。
4.1 纯动态规划(Pure Planning)
Pure Planning 是一个基础的算法,其策略并不显示的表达出来,而是使用规划技术来选择行动。比如模型预测控制(model-predictive control, MPC)。
在MPC中:
第一步:Agent首先观察环境,并通过模型预测出所有可以行动的路径(路径包含多连续个行动)。
第二步:Agent执行规划的第一个行动,然后立即舍去规划剩余部分。
第三步:重复第一、二步。
例如,MBMF在一些深度强化学习的标准基准任务上,基于学习到的环境模型进行模型预测控制
4.2 Expert Iteration(专家迭代)
这个算法是Pure Planing 的升级版,它将策略显示地表达出来,并通过学习得到这个最优策略π*θ(a|s)
Agent用规划算法(类似于MT树搜索)在模型中通过采样生成候选行动。通过采样生成的行动比单纯通过策略本身生成的行动要好,所以它是"专家"。通过"专家"指导,迭代更新并优化策略。
ExIt算法用这种算法训练深层神经网络来玩 Hex
AlphaZero这种方法的另一个例子
4.3 免模型方法的数据增强
这个方法是将模型采样中生成的数据用来训练Model-Free的策略或者Q函数。训练的数据可以单纯是模型采样生成的,也可以是真实经历的数据与模型采样数据的结合。
MBVE用假数据增加真实经验
World Models全部用假数据来训练智能体,所以被称为:“在梦里训练”
4.4 将规划嵌入策略
该算法是将规划(Planning)嵌入策略中作为策略的一个子程序,这样在用任意Model-Free训练的过程中,如何和何时规划也被学习到了。这个算法的优点就是当模型与现实环境存在较大的偏差,策略也可以选择忽略规划。
更多例子,参见I2A
附录:部分算法全名及论文链接
A2C / A3C(Asynchronous Advantage Actor-Critic): Mnih et al, 2016
PPO(Proximal Policy Optimization): Schulman et al, 2017
TRPO(Trust Region Policy Optimization): Schulman et al, 2015
DDPG(Deep Deterministic Policy Gradient): Lillicrap et al, 2015
TD3(Twin Delayed DDPG): Fujimoto et al, 2018
SAC(Soft Actor-Critic): Haarnoja et al, 2018
DQN(Deep Q-Networks): Mnih et al, 2013
C51(Categorical 51-Atom DQN): Bellemare et al, 2017
QR-DQN(Quantile Regression DQN): Dabney et al, 2017
HER(Hindsight Experience Replay): Andrychowicz et al, 2017
World Models: Ha and Schmidhuber, 2018
I2A(Imagination-Augmented Agents): Weber et al, 2017
MBMF(Model-Based RL with Model-Free Fine-Tuning): Nagabandi et al, 2017
MBVE(Model-Based Value Expansion): Feinberg et al, 2018
AlphaZero: Silver et al, 2017