上篇文章我们介绍了HashMap集合,这是一个键值对集合,可以高效的按照键查找数值。但是它有一个缺陷:数据如果是无序的可以是很高效的,但是如果数据需要排列有顺序就不适合了。本篇将要介绍的一个集合是树集键值对(TreeMap),它能够对数据按照键值有序的存储。
在介绍TreeMap之前,我们来了解一种数据结构:排序二叉树。相信学过数据结构的同学知道,这种结构的数据存储形式在查找的时候效率非常高。
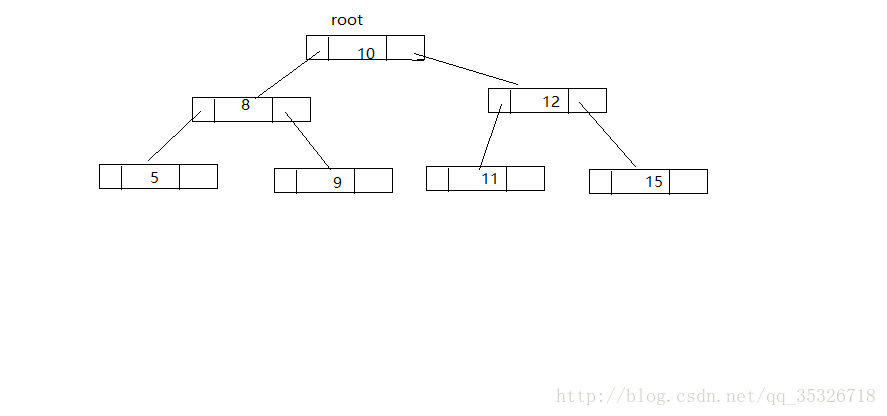
如图所示,这种数据结构是以二叉树为基础的,所有的左孩子的value值都是小于根结点的value值的,所有右孩子的value值都是大于根结点的。这样做的好处在于:如果需要按照键值查找数据元素,只要比较当前结点的value值即可(小于当前结点value值的,往左走,否则往右走),这种方式,每次可以减少一半的操作,所以效率比较高。在实现我们的TreeMap中,使用的是红黑树(一种优化了的二叉排序树)。
一、TreeMap的超接口
TreeMap主要继承了类AbstractMap(一个对Map接口的实现类)和 NavigableMap(主要提供了对TreeMap的一些高级操作例如:返回第一个键或者返回小于某个键的视图等)。主要的一些操作有:put添加元素到集合中,remove根据键值或者value删除指定元素,get根据指定键值获取某个元素,containsValue查看是否包含某个指定的值,containsKey 查看是否包含某个指定的key数值等。
二、构造函数
TreeMap 的构造函数主要有以下几种:
private final Comparator comparator;
public TreeMap() {comparator = null;}
public TreeMap(Comparator comparator) {
this.comparator = comparator;
}
因为在我们的内部存储结构中,是需要对两个节点的元素的键值进行比较的,所以就必须要实现Comparable接口来具有比较功能。第一个构造函数默认无参,内部将我们的比较器赋值为null,表明:在内部集合中不需要接受来自外部传入的比较器,默认使用Key的比较器(例如:Key是Integer类型就会默认使用它的比较器)。第二种构造函数就是从外部传入指定的比较器,指定TreeMap内部在对键进行比较的时候使用我们从外部传入的比较器。
三、内部存储的基本原理
从源码中摘取部分代码,能说明内部结构即可。
private final Comparator comparator;
private transient Entry root;
private transient int modCount = 0;
//静态成员内部类
static final class Entry implements Map.Entry {
K key;
V value;
Entry left;
Entry right;
Entry parent;
boolean color = BLACK;
.........
}
从代码中,我们可以很容易的看出来,内部包含一个 comparator 比较器(或值被置为Key的比较器,或是被置为外部传入的比较器),根结点 root (指向红黑树的跟结点),记录修改次数 modCount (用于对集合结构性的检查和前面文章说的一样),还有一个静态内部类(其实可以理解为一个树结点),其中有存储键和值的key和value,还有指向左孩子和右孩子的“指针”,还有指向父结点的“指针”,最后还包括一个标志 color(这个暂时不用知道)。也就是说,一个root指向树的跟结点,而这个跟根结点又链接为一棵树,最后通过这个root可以遍历整个树。
四、put添加元素到集合中
在了解了TreeMap的内部结构之后,我们可以看看他是怎么将一个元素结点挂到整棵树上的。由于put方法的源码比较多,请大家慢慢看。
public V put(K key, V value) {
Entry t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry parent;
// split comparator and comparable paths
Comparator cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable k = (Comparable) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
首先判断根结点是否是空的,如果是空的直接创建一个结点并将parent赋null,将其作为该树的跟结点,返回null跳过余下代码。如果跟结点不是空的,就去判断 comparator 是否为null(也就是判断comparator的值是默认key的比较器还是外部传入的比较器),如果comparator的值是外部传入的,通过循环比较key的值计算将要添加的结点的位置(过程中如果发现有某个结点的key值和将要添加的key的值相等,说明这是修改操作,修改其value值返回旧value值)。
如果在创建对象的时候并没有从外部传入比较器,首先判断key的值是否为null(如果是就抛出空指针异常),那有人说:为什么要对key是否为空做判断呢?上面不是也没有做判断么? 答案是:如果 comparator 是外部传入的,那么没问题,但是如果是key的默认比较器,那如果key为null 还要调用比价器 必然抛空指针异常。接下来做的事情和上面一样的。
程序执行到最后了,我们要知道一点的是:parent指向的是最后一个结点也就是我们将要添加的结点的父结点。最后根据key和value和parent创建一个几点(父结点是parent),然后根据上面的判断确定此结点是parent的左孩子还是右孩子。
这个方法中有一个 fixAfterInsertion(e); 是用于红黑树的构造的,调用这个函数可以将我们刚刚创建完成之后的树通过挪动重新构建成红黑树。
最后总结一下整个put方法的执行过程:
- 判断此树是否是空的,空树的操作就很简单了
- 判断比较器的来源做不同的操作(比较value值确定位置)
- 构建新结点挂上树
- 调用方法重构红黑树
其中,我们要区分一点的是,为什么有时候返回的null,有时候返回的是旧结点的value,主要区别还是在于,put方法作为添加元素和修改元素的两种功能,添加元素的时候统一返回的是null,修改元素的时候统一返回的是别修改之前的元素的value。
五、根据键的值删除结点元素
添加元素直到是怎么回事了之后,我们来看看删除元素是怎么被实现的,首先看remove方法:
public V remove(Object key) {
Entry p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
从代码中可以看出来,删除的操作主要还是两个操作的结合,一个是获取指定元素,一个是删除指定元素。我们先看如何获取指定元素。
final Entry getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable k = (Comparable) key;
Entry p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
这段代码不难理解,依然是分两种情况比较器的来源(由于两种情况下的处理方式类似,此处指具体说其中一种),p指向根结点root,循环遍历,比较key和当前循环到的key是否相等,不相等就根据大小向左或者向右,如果相等执行return p; 返回此结点。如果整棵树遍历完成之后,没有找到指定键值的结点就会返回null表示未找到该结点。这就是查找方法,下面我们看看删除指定结点的方法。
在看代码之前我们先了解一下整体的思路,将要删除的结点可能有以下三种情况:
- 该结点为叶子结点,即无左孩子和右孩子
- 该结点只有一个孩子结点
-
该结点有两个孩子结点
第一种情况,直接将该结点删除,并将父结点的对应引用赋值为null
第二种情况,跳过该结点将其父结点指向这个孩子结点
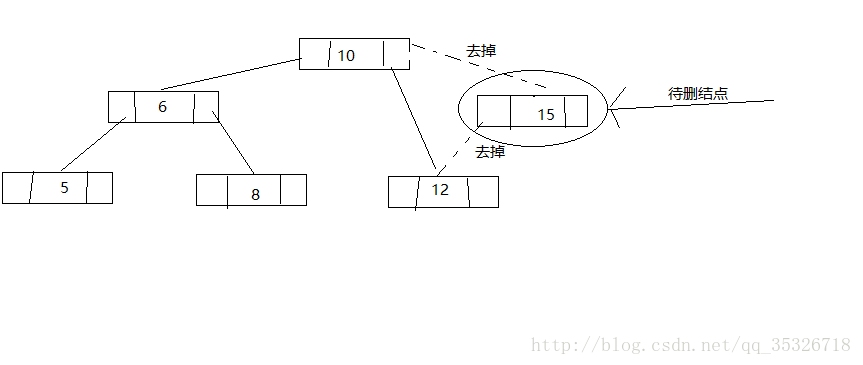 这里写图片描述
这里写图片描述
第三种情况,找到待删结点的后继结点将后继结点替换到待删结点并删除后继结点(将问题转换为删除后继结点,通过前面两种可以解决)
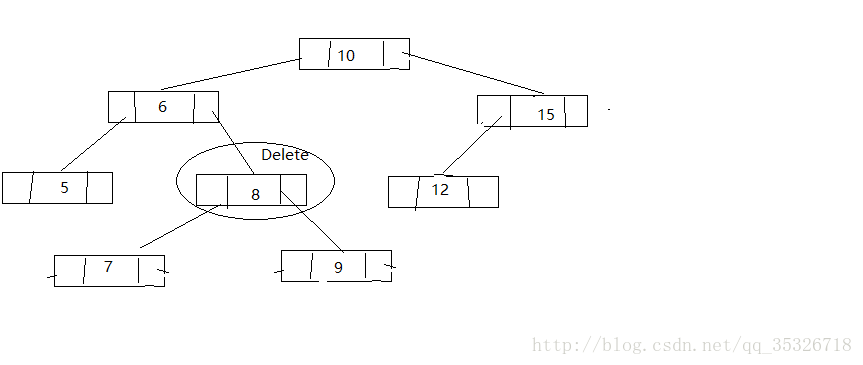 这里写图片描述
这里写图片描述
找到后继结点
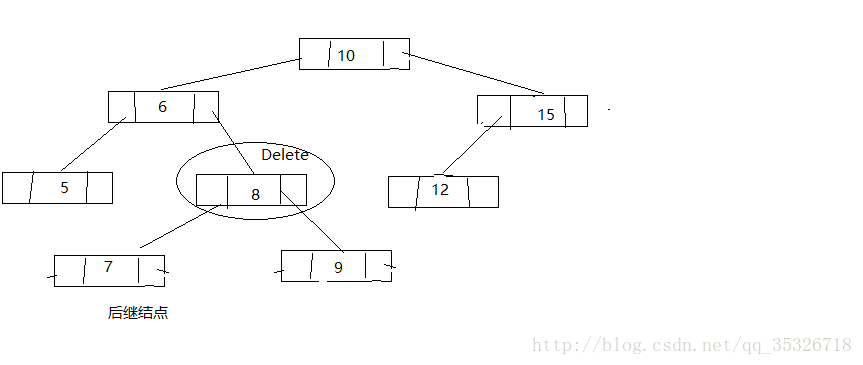 这里写图片描述
这里写图片描述
替换待删结点
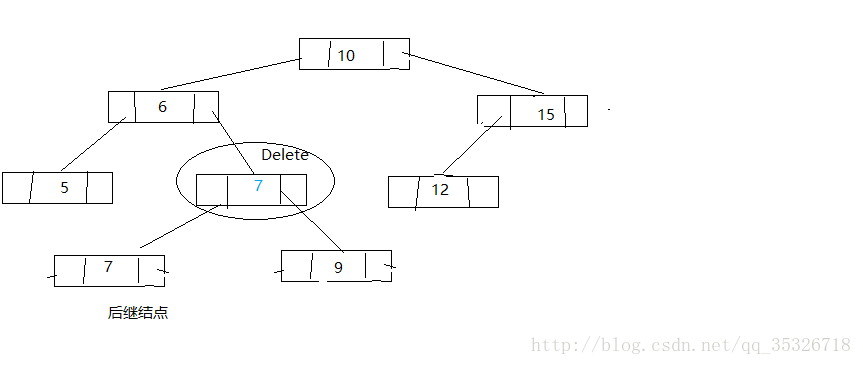 这里写图片描述
这里写图片描述
删除后继结点
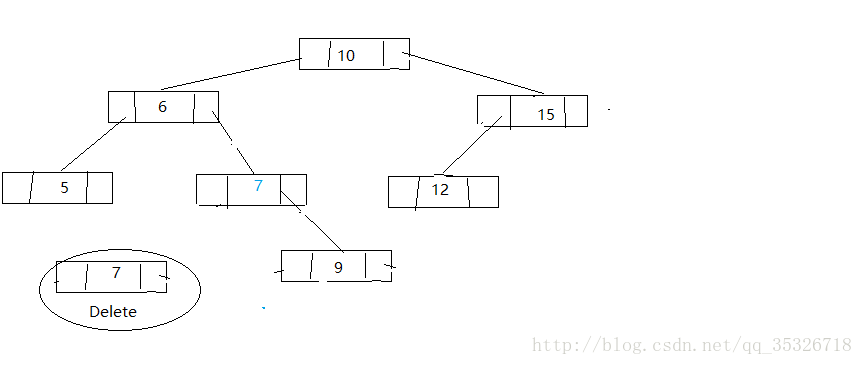 这里写图片描述
这里写图片描述
下面我们看代码:
/*代码虽多,我们一点一点看*/
private void deleteEntry(Entry p) {
modCount++;
size--;
// If strictly internal, copy successor's element to p and then make p
// point to successor.
if (p.left != null && p.right != null) {
Entry s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children
// Start fixup at replacement node, if it exists.
Entry replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// Link replacement to parent
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;
// Fix replacement
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;
} else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
首先,判断待删结点是否具有两个孩子,如果有调用函数 successor返回后继结点,并且替换待删结点。对于这条语句:Entry>K,V< replacement = (p.left != null ? p.left : p.right); ,我们上述的三种情况下replacement的取值值得研究,如果是第一种情况(叶子结点),那么replacement取值为null,进入下面的判断,第一个if过,第二个判断待删结点是否是根结点(只有根结点的父结点为null),如果是说明整个树只有一个结点,那么直接删除即可,如果不是根结点就说明是叶子结点,此时将父结点赋值为null然后删除即可。
对于第二种情况下(只有一个孩子结点时候),最上面的if语句是不做的,如果那一个结点是左孩子 replacement为该结点,然后将此结点跳过父结点挂在待删结点的下面,如果那一个孩子是右孩子,replacement为该结点,同样操作。
第三种情况(待删结点具有两个孩子结点),那肯定执行最最上面的if语句中代码,找到后继结点替换待删结点(后继结点一定没有左孩子),成功的将问题转换为删除后继结点,又因为后继结点一定没有左孩子,整个问题已经被转换成上述两种情况了,(假如后继结点没有右孩子就是第一种,假如有就是第二种)所以replacement = p.right,下面分情况处理。删除方法结束。
小结一下,删除结点难点在于删除指定键值的结点,主要分为三种情况,叶子结点,一个孩子结点,两个孩子结点。而对于不同的情况,jdk编写者将最难的两个孩子结点转换为前两种较为简单的方式,可见大神之作。钦佩。
最后还是要说,本篇文章为博主反复研究jdk源码总结而来,如果有错误,望指出。