本篇文章主要来介绍什么是数据结构。
首先让我们来看一张图片:
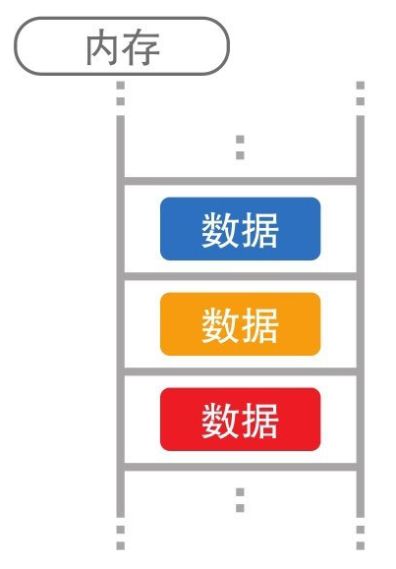
数据存储于计算机的内存中。内存如上图所示,形似排成 1 列的箱子,1 个箱子里存储 1 个数据。
数据存储于内存时,决定了数据顺序和位置关系的便是数据结构。
其实在我们生活中用到很多数据结构的知识,那么举一个我们生活中的栗子:
首先举一个从上往下顺序添加举个简单的例子。假设我们有1个电话簿——虽说现在很多人都把电话号码存在手机里,但是这里我们考虑使用纸质电话簿的情况——每当我们得到了新的电话号码,就按从上往下的顺序把它们记在电话簿上。
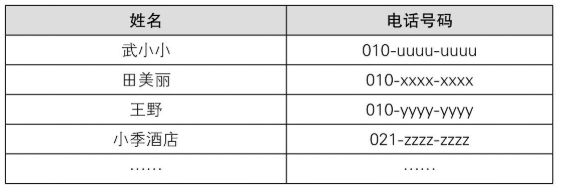
假设此时我们想给张飞打电话,但是因为数据都是按获取顺序排列的,所以我们并不知道张飞的号码具体在哪里,只能从头一个个往下找(虽说也可以从后往前找或者随机查找,但是效率并不会比从上往下找高)。如果电话簿上号码不多的话很快就能找到,但如果存了500个号码,找起来就不那么容易了。
再比如我们可以按姓名的拼音顺序对电话簿进行排列,接下来,试试以联系人姓名的拼音顺序排列吧。因为数据都是以字典顺序排列的,所以它们是有结构的。

使用这种方式给联系人排序的话,想要找到目标人物就轻松多了。通过姓名的拼音首字母就能推测出该数据的大致位置。
那么,如何往这个按拼音顺序排列的电话簿里添加数据呢?假设我们认识了新朋友柯南并拿到了他的电话号码,打算把号码记到电话簿中。由于数据按姓名的拼音顺序排列,所以柯南必须写在韩宏宇和李希之间,但是上面的这张表里已经没有空位可供填写,所以需要把李希及其以下的数据往下移1行。
此时我们需要从下往上执行将本行的内容写进下一行,然后清除本行内容的操作。如果一共有500个数据,一次操作需要10秒,那么1个小时也完成不了这项工作。
总的来说,数据按获取顺序排列的话,虽然添加数据非常简单,只需要把数据加在最后就可以了,但是在查询时较为麻烦;以拼音顺序来排列的话,虽然在查询上较为简单,但是添加数据时又会比较麻烦。
虽说这两种方法各有各的优缺点,但具体选择哪种还是要取决于这个电话簿的用法。如果电话簿做好之后就不再添加新号码,那么选择后者更为合适;如果需要经常添加新号码,但不怎么需要再查询,就应该选择前者。
我们还可以考虑一种新的排列方法,将二者的优点结合起来。那就是分别使用不同的表存储不同的拼音首字母,比如表L、表M、表N等,然后将同一张表中的数据按获取顺序进行排列。


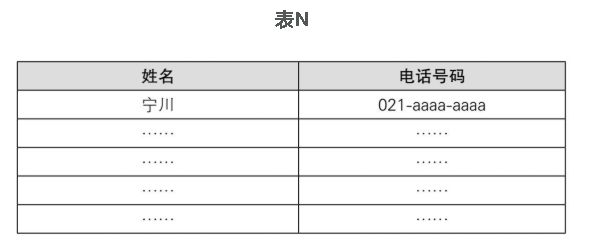
这样一来,在添加新数据时,直接将数据加入到相应表中的末尾就可以了,而查询数据时,也只需要到其对应的表中去查找即可。
因为各个表中存储的数据依旧是没有规律的,所以查询时仍需从表头开始找起,但比查询整个电话簿来说还是要轻松多了。
数据结构方面的思路也和制作电话簿时的一样。将数据存储于内存时,根据使用目的选择合适的数据结构,可以提高内存的利用率。
到这里,我相信你对数据结构有了一定的了解,下一篇我们将对数据结构中最常用的-链表进行讲解。
参考
《我的第一本算法书》