本文介绍OpenAI和Google特征可视化新技术:用激活地图集探索神经网络
Exploring Neural Networks with Activation Atlases
原文链接:
Demo:https://distill.pub/2019/activation-atlas/app.html
代码:https://github.com/tensorflow/lucid/#activation-atlas-notebooks
通过使用特征反演(feature inversion)来显示来自图像分类网络的数百万个激活,我们创建了一个可探索的激活地图集,其中包含网络已经学习的特征,可以揭示网络通常如何表示某些概念。
引言
神经网络可以学习比人类直接设计的任何系统更准确地分类图像。这提出了一个自然的问题:这些网络学到了什么使它们能够很好地对图像进行分类?
特征可视化是研究的一条线:它试图通过让我们透过网络之眼来回答这个问题。 它开始于研究个体神经元的可视化并试图确定它们的反应。因为神经元不能孤立地工作,所以这导致需要对神经元的简单组合进行特征可视化。但是仍然存在一个问题 - 我们应该研究哪些神经元组合? 一个自然的答案(由模型反演工作预示)是做可视化激活,即对一个特定输入的神经元激发进行组合。
这些方法令人兴奋,因为它们可以使网络的隐藏层易于理解。这些层是神经网络如何胜过传统的机器学习方法的核心,而在历史上,我们对其中发生的事情几乎一无所知。特征可视化通过将隐藏层连接回输入来实现此目的,使其具有意义。
不幸的是,可视化激活有一个主要的弱点 - 仅限于看到网络如何看到单个输入。 因此,它没有给网络一个大的图画。 当我们想要的是整个森林的地图时,一次检查一棵树是不够的。
有些技术可以提供更全面的视图,但它们往往还有其他缺点。例如,Karpathy的CNN代码可视化接收每个图像并组织从一个神经网络的激活值来提供数据集的全局视图。模型看到的图像确实有助于我们推断出有关哪些特征是网络正在响应的,但特征可视化使这些连接更加明确。Nguyen等使用t-SNE进行更多样化的神经元可视化。通过在t-SNE图中聚类图像,为优化过程生成不同的起点。这揭示了神经元检测到的更大的图画,但仍然关注单个神经元。
在本文中,我们将介绍激活地图集这种技术。从广义上讲,我们使用的技术类似于CNN代码中的技术,但不是显示输入数据,而是显示平均激活的特征可视化。通过结合这两种技术,可以在一个视图中获得每个技术的优势 – 得到一个透过网络之眼看到的全局地图。
从理论上讲,基础神经元的特征可视化将为我们提供正在寻求的网络的全局视图。 然而,在实践中,网络很少孤立地使用神经元,并且可能难以用这种方式理解它们。作为类比,虽然字母表中的26个字母为英语提供了基础,但看到字母如何组合以成为单词,可以比单独的字母更能洞察可以表达的概念。同样,激活地图集通过显示神经元的常见组合为我们提供了更大的图画。
- 可视化单个神经元使隐藏层有些有意义,但错过了神经元之间的相互作用 - 它只向我们展示了高维激活空间的一维的正交的探头。
- 成对交互(Pairwise interactions)揭示了交互效应,但它们仅显示具有数百个维度的空间的二维切片,并且许多组合是不现实的。
- 空间激活(Spatial activations)通过对可能激活的子流形进行采样显示许多神经元的重要组合,但它们仅限于给定示例图像中出现的那些。
- 通过对更多可能的激活进行采样,激活地图集提供了更大的图像概览。
这些地图集不仅揭示了模型中的视觉抽象,而且在文章的后面我们将展示它们可以揭示可被利用的模型中的高层次的误解。 例如,通过查看激活图集,我们将能够看到为什么棒球图片可以将图像的分类从“灰鲸”切换为“大白鲨”。
当然,激活地图集确实有局限性。
特别是,它们依赖于选择的数据分布(我们使用从ImageNet数据集训练数据中随机选择的一百万个图像)。
因此,它们仅显示样本数据分布中存在的激活。 然而,重要的是虽然要意识到这些限制,激活地图集仍然提供了神经网络可以代表什么的新概述。
看单个图像
在深入研究激活地图集之前,我们简要回顾一下如何使用特征可视化使激活向量变得有意义(“透过网络的眼睛看”)。 这种技术在Building Blocks中引入,并将成为激活地图集的基础。(The Building Blocks of Interpretability. Olah, C., Satyanarayan, A., Johnson, I., Carter, S., Schubert, L., Ye, K. and Mordvintsev, A., 2018. Distill. DOI: 10.23915/distill.00010)
在整篇文章中,我们将关注一个特定的神经网络:InceptionV1(也称为“GoogLeNet”)。 它在2014年ImageNet大规模视觉识别挑战中赢得图像分类任务。
InceptionV1由若干层组成,将其称为“mixed3a”,“mixed3b”,“mixed4a”等,有时简称为“3a”。 每个层依次建立在前面的层上。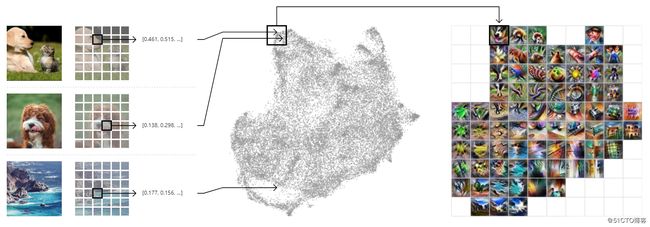
为了可视化InceptionV1如何看到图像,第一步是将图像输入网络并将其运行到感兴趣的层。 然后收集激活 - 每个神经元激发多少的数值。 如果神经元被显示的东西激发,它的激活值将是正的。
不幸的是,这些激活值的向量只是无单位数的向量,并不是人可以解释的。这就是特征可视化的用武之地。简单地说,我们可以将特征可视化看做创建网络认为会产生特定激活向量的一个理想化图像。虽然通常使用网络将图像转换为激活矢量,但在特征可视化中,却朝着相反的方向前进。从特定图层的激活矢量开始,通过迭代优化过程创建一个图像。
因为InceptionV1是卷积网络,所以每个图像的每层不仅有一个激活矢量。 这意味着在前一层的每个图块上运行相同的神经元。 因此,当通过网络传递整个图像时,每个神经元将被评估数百次,对于图像的每个重叠图块一次。 我们可以考虑每个神经元分别为每个图块发射出多少的向量。
结果是一个特征可视化网格,每个图块一个。 这向我们展示了网络如何看到输入图像的不同部分。 
聚合多个图像
激活网格显示网络如何看到单个图像,但如果我们想要查看更多内容呢? 如果我们想了解它对数百万张图像的反应怎么办?
当然,可以逐个查看这些图像的各个激活网格。但是看着数以百万计的例子并没有扩展,人类的大脑也不善于比较很多没有结构的例子。就像需要像直方图这样的工具来理解数百万个数字一样,如果想要在数百万个数字中看到有意义的模式,需要一种聚合和组织激活的方法。
让我们从收集一百万张图片的激活开始吧。我们将为每个图像随机选择一个空间激活。这给了我们一百万个激活向量。每个向量都是高维的,可能是512维! 有了这么复杂的数据集,如果想要一个大图片视图,需要组织和聚合它们。
值得庆幸的是,我们拥有现代降维技术。这些算法,如t-SNE和UMAP,可以将高维数据(如激活矢量集合)投影到有用的2D布局中,从而保留原始空间的一些局部结构。 这需要组织激活向量,但还需要聚合成更易管理的元素 - 一百万个点难以解释。我们将通过在维度减少的情况下创建的2D布局上绘制网格来实现此目的。对于网格(grid)中的每个cell,我们均位于该cell边界内的所有激活,并使用特征可视化来创建一个图标表示(iconic representation)。
- 通过网络馈送一组随机的一百万个图像,每个图像收集一个随机空间激活。
- 通过UMAP提供激活以将其减少到二维。 然后绘制它们,相似的激活放置在彼此附近。
- 然后,绘制一个网格并对位于cell内的激活进行平均,并对平均激活进行特征反演。 我们还可以根据平均内部激活次数的密度来选择网格单元(grid cell)的大小。
我们使用特征可视化中描述的正则化(特别是变换鲁棒性)执行特征可视化。 但是,我们使用略微不标准的目标。 通常,为了使激活空间中的一个方向可视化,![]() ,可以在一个位置最大化与激活矢量
,可以在一个位置最大化与激活矢量![]() 的点积
的点积![]() 。我们发现通过将点积乘以余弦相似度来使用更强调角度的目标是有帮助的,从而得到以下形式的目标:
。我们发现通过将点积乘以余弦相似度来使用更强调角度的目标是有帮助的,从而得到以下形式的目标:![]()
我们还发现,白化激活空间以使其无法拉伸可以帮助改善特征可视化。我们还没有完全理解这种现象。
对于每个激活矢量,我们还计算一个归因矢量(attribution vector)。 归因向量对每个类有一个条目(entry),并且近似于激活向量影响每个类的logit的量。 归因向量通常取决于周围上下文。我们遵循Building Blocks来计算某个位置的激活矢量![]() 到一个类别
到一个类别![]() 的归因为
的归因为![]() 。也就是说,估计一个神经元对一个logit的影响是增加该神经元影响这个logit的rate(That is, we estimate that the effect of a neuron on a logit is the rate at which increasing the neuron affects the logit)。 这类似于Grad-CAM,但没有梯度的空间平均。相反,我们通过在计算梯度时对最大池化使用梯度的连续松弛来减少梯度中的噪声。激活地图集中的cell显示的归因是该cell中激活的归因向量的平均值。
。也就是说,估计一个神经元对一个logit的影响是增加该神经元影响这个logit的rate(That is, we estimate that the effect of a neuron on a logit is the rate at which increasing the neuron affects the logit)。 这类似于Grad-CAM,但没有梯度的空间平均。相反,我们通过在计算梯度时对最大池化使用梯度的连续松弛来减少梯度中的噪声。激活地图集中的cell显示的归因是该cell中激活的归因向量的平均值。
这种平均归因可以被认为是显示cell倾向于支持哪些类,在上下文中边缘化。 在早期阶段,平均归因非常小,得分最高的类别相当随意,因为像纹理这样的低级视觉特征在没有上下文的情况下往往不会非常具有辨别力。
那么,这有多好? 好吧,让我们尝试将它应用于InceptionV1的mixed4c层。
这张地图集乍一看可能有点震撼 - 有很多事情要发生! 这种多样性反映了模型发展的各种抽象和概念。让我们来看一下更深入地研究这个地图集。
如果看一下地图集的左上角,我们会看到什么看起来像动物头。不同类型的动物之间存在一些差异,但它似乎更多地是一般的哺乳动物 - 眼睛,毛皮,鼻子 - 的元素集合,而不是不同类别的动物的集合。 我们还添加了标签,显示每个平均激活最有助于哪个类。 请注意,在网络早期的某些区域中,这些归属标签可能会有些混乱。在早期层中,归因向量的幅度很小,因为它们对输出没有一致的影响。

随着我们向下移动,我们开始看到不同类型的毛皮和四足动物的背部。
在此之下,我们发现不同的动物腿和脚搁在不同类型的地面上。
在脚下,我们开始失去任何可识别的动物部分,并看到孤立的地面和地板。我们看到归因于“沙洲”等环境以及地面上发现的东西,如“门垫”或“蚂蚁”。
这些沙质的岩石背景慢慢融入海滩和水体。 在这里,我们可以看到水面上下的湖泊和海洋。 虽然网络确实有某些类别,如“海滨”,但我们看到许多海洋动物的归因,没有动物本身的任何视觉参考。虽然并不出人意料,但令人欣慰的是,用于识别“海滨”级海洋的激活与“海星”或“海狮”分类时使用的激活相同。湖泊和海洋之间在这一点上也没有真正的区别 - “湖边”和“河马”归因与“海星”和“黄貂鱼”混合在一起。
现在跳到地图集的另一边,在那里可以看到许多文本检测器的变化。这些在识别“菜单”,“网站”或“书籍外皮”等类时非常有用。 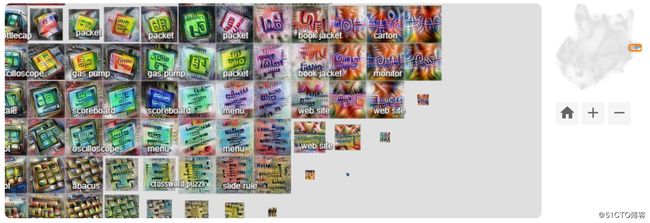
向上移动,我们看到很多人的变化。 很少有类可以专门识别ImageNet中的人,但人会出现在很多图像中。我们看到人使用的东西(“锤子”,“长笛”),人穿的衣服(“领结”,“maillot”)和人参加的活动(“篮球”)的归因。 这些可视化中的肤色均匀,我们怀疑这是用于训练的数据分布的反映。(你可以在线分类浏览ImageNet训练数据:泳裤、尿布、创可贴、口红等)。
最后,回到左边,可以看到圆形的食物和水果主要由颜色组织 - 我们看到归因于“柠檬”,“橙子”和“无花果”。
我们还可以通过创建的这个流形追踪弯曲的路径。 不仅区域重要,而且通过空间的某些运动似乎与人可解释的品质相对应。通过水果,可以追踪一条似乎与框架中水果的大小和数量相关的路径。
同样地,对于人,可以追踪一条似乎与框架中有多少人相对应的路径,无论是单个人还是人群。
通过地面检测器,可以追踪从水到海滩到岩石峭壁的路径。
在植物区域,可以追踪一条似乎与植物模糊程度相对应的路径。 由于相机的典型焦距,这可能用于确定物体的相对尺寸。 特写小昆虫的照片比像猴子这样的大型动物的照片有更多的机会模糊背景叶子。
重要的是要注意,这些路径是在低维投影中构造的。它们在这种降维的投影中是平滑的路径,但我们不一定知道路径如何在原始的高维激活空间中操作。
看多个层
在上一节中,我们主要关注网络的一层,mixed4c,它位于网络的中间。 卷积网络通常很深,由许多层组成,逐步构建更强大的抽象。 为了获得整体视图,我们必须研究模型的抽象如何在多个层上发展。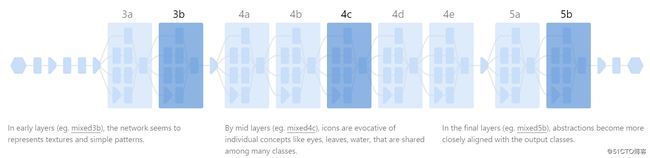
首先,比较来自网络不同区域的三个层,试图了解每个层的不同个性 - 一个非常早的层(mixed3b),一个中间层(mixed4c)和在logits之前的最后一层(mixed5b)。 我们将关注每层有助于“卷心菜”分类的区域。
当你在网络中移动时,后面的层似乎变得更加具体和复杂。 这是可以预期的,因为每个层都在前一层的激活之上构建其激活。 后面的层也倾向于具有比它们之前的更大的感受野(意味着它们被显示为更大的图像子集),因此概念似乎包含更多的整个对象。
还有另一个值得注意的现象:不仅概念被细化(refine),新概念也出现在旧概念的组合中。下面,你可以看到沙子和水是如何在中间层mixed4c中是不同概念,两者都具有对“沙洲”分类的强大归因。将此与后一层混合5b进行对比,其中两个想法似乎融合为一个激活。
最后,如果稍微缩小一点,可以看到激活空间的更广的形状如何在层与层之间变化。通过查看几个连续层中的相似区域,可以看到概念得到细化和区分 - 在mixed4a中,看到非常模糊的通用blob,它被mix4e细化为更具体的“半岛”。




你可以在下面浏览更多InceptionV1层。 你可以将mixed4a的弯曲边缘检测器与mixed5b的碗和杯进行比较。 Mixed4b有一些有趣的文本和模式检测器,而mixed5a似乎使用它们来区分菜单和填字游戏中的填字游戏。 在早期的图层中,比如mixed4b,你会看到彼此相似的纹理,比如面料。 在以后的图层中,你将看到特定类型的服装。
专注于单一分类
查看所有激活的图集可能有点头晕,特别是当你试图了解网络如何排序某个特定类时。 例如,让我们研究网络如何对“救火船”进行分类。
首先看一下地图集最后一层,mixed5b。 但是,我们不会显示所有激活,而是计算每次激活对“fireboat”分类的贡献量,然后将该值映射到激活图标的不透明度。 对“救火船”分类有很大贡献的区域将清晰可见,而贡献很少(甚至贡献不利)的区域将完全透明。
刚刚查看的图层mixed5b位于最终的分类层之前,因此它与最终类紧密对齐似乎是合理的。 让我们先看一下网络中的一个层,比如mixed4d,看看它是如何不同的。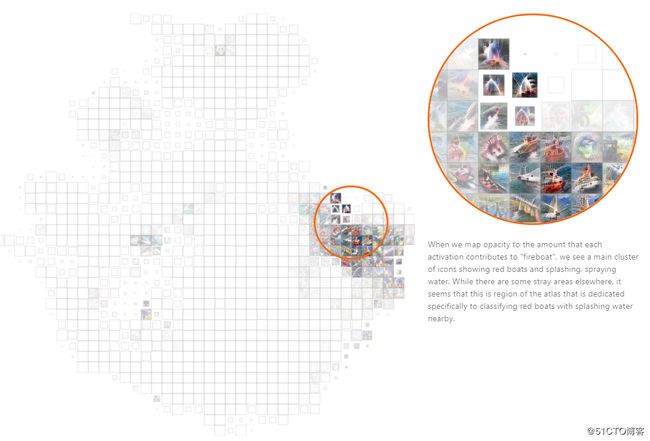
在这里,我们看到了一个截然不同 如果我们看一些更多的输入示例,这似乎是完全合理的。 这几乎就像我们可以看到网络将在后面的层中使用的组件概念的集合来分类“fireboat”。 窗户+起重机+水=“消防船”。

其中一个簇,一个带有窗户的簇,具有强烈的“救火船”归因。但就其自身,它对“有轨电车”具有更强的归因。 那么,让我们回到地图集的mixed4d,将“有轨电车”与“救火船”所看到的模式进行比较。 让我们更仔细地看一下四个突出的区域:突出显示了救火艇的三个区域以及一个有轨电车高度激活的区域。
如果放大,可以更好地了解这一层的两个分类的区别。
如果看几个输入示例,可以看到建筑物和水的背景是区分“消防船”和“有轨电车”的一个简单方法。
通过隔离对一个类有强贡献的激活并将其与其他类激活进行比较,可以看到哪些激活在类之间是保持的,哪些激活又重组以在后面的层中形成更复杂的激活。下面你可以通过几层InceptionV1探索ImageNet中许多类的激活模式。 你甚至可以探索负面归因,我们在本次讨论中忽略了这些归因。
进一步隔离类
突出显示完整地图集的特定类别激活有助于了解该类如何与网络“可以看到”的完整空间相关联。但是,如果想要真正隔离有助于特定类的激活,可以删除所有其他激活而不是仅仅调暗它们,创建我们称之为一个类激活地图集的内容。 与一般地图集类似,在类特定的激活向量上执行降维,以便在类激活地图集中安放显示的特征可视化。
一个类激活地图集使我们能够更清楚地了解网络使用哪些检测器对特定类进行排序。 在“呼吸管”示例中,可以清楚地看到海洋、水下和彩色面具。
在前面的示例中,仅显示那些针对相关激活最强归因。这将向我们展示激活,这些激活主要对我们的类有所贡献,即使它们的整体强度很低(如背景探测器)。 但在某些情况下,我们希望看到强烈的相关性(比如鱼和浮潜器)。 相比我们感兴趣的一个类,这些激活本身可能对别的一个不同的类贡献更大。但它们的存在也可以对我们感兴趣的类产生强的贡献。对此,我们需要选择不同的滤波方法。
使用幅度滤波方法,让我们尝试比较两个相关的类,看看是否可以更容易地看到它们的区别。 (我们可以改为使用排序,或两者的组合,但幅度足以向我们展示各种各样的概念)。
立即理解类之间的所有差异可能有点困难。 为了使比较更容易,可以将两个视图合并为一个。 我们将横向绘制“浮潜员”和“水肺潜水员”的归因之间的差异,并使用t-SNE垂直聚类相似的激活。
在这个比较中,可以在左侧看到一些类似鸟类的生物和透明管,暗示与“通气管”的相关性,以及一些类似鲨鱼的生物和右边的圆形,有光泽和金属的东西,暗示与“水肺潜水”的相关性 “(该激活对蒸汽机车类有很强的归因)。 让我们从标记为“浮潜”的ImageNet数据集中获取图像,并添加类似于此图标的内容,以了解它如何影响分类分数。
这里的失效模式似乎是该模型正在使用其检测用于“蒸汽机车”类来识别空气罐以帮助对“潜水员”进行分类。(译者注:即把“浮潜“误判为”水肺潜水”) 我们称之为“多用途”特征- 检测器可以对视觉上相似的非常不同的概念做出反应。 下面看这个问题的另一个例子。让我们来看看“灰鲸”和“大白鲨”之间的区别。
在这个例子中,我们看到另一个似乎扮演两个角色的检测器:检测棒球上的红色缝线和鲨鱼的白色牙齿和粉红色的口。这个检测器也出现在激活地图集层mixed5b滤波到“大白鲨”。它的归因是各种各样的球,最重要的是“棒球”。
让我们将一个棒球图片添加到ImageNet的“灰鲸”图片中,看看它是如何影响分类的。
结果非常接近前面例子中的模式。 添加一个小型棒球确实将顶级分类改为“大白鲨”。随着它越来越大,它主导了分类,所以顶部的位置变为“棒球”。
让我们看一个例子:“煎锅”和“炒锅”。
这里有一个不同之处 - 存在相关食物的类型。 在右边,我们可以清楚地看到类似面条的东西(它们对“carbonara”类有很强的归因)。 让我们从ImageNet拍下一张标有“煎锅”的照片,并添加一些面条的插图。
这里的图块在降低初始分类方面不那么有效。这是有道理的,因为面条状图标更多地朝着可视化的中心绘制,因此归因的差异较小。 我们怀疑训练集只包含更多的面条炒锅图像而不是煎锅面条。
在数千张图像上测试数十个图块
到目前为止,我们只展示了这些图块的单个示例。下面我们展示了十个样本图块的结果(每个集合包括我们上面探讨过的一个例子),通过执行来自相关类的ImageNet训练集的1,000个图像。 虽然它们在所有情况下都没有效果,但它们确实将图像分类翻转到大约五分之二的图像中。 如果还允许将图块定位在最有效尺寸的图像的四个角中的最佳位置(左上,右上,左下,右下),则成功率达到约每2个图像1个。 为了确保不仅阻止了最初类的证据,我们还将每次与随机噪声图像图块进行比较。


我们的attacks可以看作是一部分研究人员在传统的epsilon球对抗性例子(epsilon ball adversarial examples)之外探索输入attacks。 在许多方面,我们的attacks最类似于对抗图块(adversarial patches),它也会在输入图像中添加一个小图块。 从这个角度来看,对抗性图块更加有效,工作更加可靠。 但是,我们认为我们的attacks很有趣,因为它们是人从对模型的理解中合成的,并且似乎在更高的抽象层次上模型。
我们还想强调的是,并非所有类之间比较都显示这些类型的图块,并且并非所有可视化中的图标都有同样有效。我们只在一个模型上测试它们。 如果想更系统地找到这些图块,一个不同的方法可能更有效。 然而,类激活地图集技术是在我们知道寻找它们之前就揭示这些图块的存在。
结论和未来的工作
激活地图集为我们提供了一种融入卷积视觉网络的新方法。它们为隐藏层中的概念提供了全局、层次化和人可解释的概念的概观。这不仅可以让我们更好地了解这些复杂系统的内部工作原理,而且可以启用新的接口来处理图像。
模型的内在属性
绝大多数神经网络研究侧重于网络行为的定量评估。模型的准确度如何? precision-recall曲线是什么?
虽然这些问题可以描述网络在特定情况下的行为,但它并没有让我们很好地理解它的行为方式。要真正理解网络行为的原因,需要充分了解网络的丰富内部世界 - 它是隐藏的层。 例如,更好地了解InceptionV1如何从mixed4d中的组件部件构建救火船的分类器,这可以帮助我们建立对模型的信心,并且可以在不满足我们想要时原因浮出水面。
参与这个内在世界也邀请我们以新的方式进行深度学习研究。通常情况下,每个神经网络实验只给出一些反馈 - 无论损失是上升还是下降 - 以通知下一轮实验。在多年积累的模糊直觉的指导下,我们通过几乎盲目的试验和错误来设计架构。在未来,我们希望研究人员能够对它们模型中每一层所做的事情进行丰富的反馈,而不是以当前看起来像在黑暗中磕磕绊绊摸索的方法。
激活地图集,就像它们目前的情况一样,不足以真正帮助研究人员迭代模型,部分原因是它们无法比较。 如果你看两个略有不同的模型的地图集,很难带走任何东西。 在未来的工作中,我们将探索类似的可视化如何比较模型,从而显示错误率之外的相似点和差异。
新接口
机器学习模型通常被部署为黑盒子,可以自动执行特定任务,并自行执行。 但是越来越多的人认为,我们可能有另一种方式与它们联系:可以更直接地使用它们,而不是逐渐使任务自动化。 我们发现特别引人注目的这种增强的一个愿景是神经网络学习的内部表示可以被重新用作工具。 我们已经在图像和音乐中看到了令人兴奋的演示。
我们认为激活地图集揭示了图像的机器学习字母表 - 一组简单的原子概念,它们被组合并重新组合以形成更复杂的视觉想法。 与使用文字处理器将字母转换为单词,将单词转换为句子的方式相同,我们可以想象一种工具,它允许我们从机器学习的语言系统中为图像创建图像。 类似于GAN绘画,想象使用类似激活地图集的东西作为调色板 - 可以将画笔浸入“树”激活并用它绘画。 这里是用概念的调色板而不是颜色的调色板。
虽然分类模型通常不被认为是用于生成图像,但有技术已经表明这完全是可能的。 在这个特定的例子中,我们想象通过从图集(或某些推导)中选择它们来构建激活网格,然后优化与用户构造的激活矩阵相对应的输出图像。
我们还可以使用这些地图集来查询大型图像数据集。 与使用单词检测大型文本语料库的方式相同,我们也可以使用激活地图集来查找大型图像数据集中的图像类型。 使用单词来搜索类似“树”的东西是相当强大的,但随着你查询的具体化,人类语言通常不适合描述特定的视觉特征。 相比之下,神经网络的隐藏层是为了表示视觉概念而唯一目的而优化的语言。 而不是使用众所周知的千言万语来唯一地指定一个人正在寻找的图像,我们可以想象有人使用激活地图集的语言。
最后,我们还可以将激活地图集比作直方图。 与传统直方图为大型数据集提供良好摘要的方式相同,激活地图集可用于对大量图像建立汇总。
在本文的示例中,我们使用相同的数据集来训练模型,就像我们收集激活一样。 但是,如果我们使用不同的数据集来收集激活,我们可以使用图集作为检查未知数据集的方法。 激活地图集可以向我们显示图像中存在的学习概念的直方图。 这样的工具可以向我们展示数据的语义,而不仅仅是视觉上的相似性,比如显示常见像素值的直方图。
虽然我们对激活地图集的潜力感到兴奋,但我们对于为其他类型的模型开发类似技术的可能性更加兴奋。 想象一下,如果对图像、音频和文本有一系列机器学习学习到的、人可解释的语言,值得期待。
后记:本人博客将会不断推出深度学习之计算机视觉方面的文章,请关注。常回来看看。