数据处理阶段
- 基于
pytorch的一个不得不学的框架,听师兄说最大的优势在于decoder速度巨快无比,大概是t2t的二十几倍,而且有fp16加持,内存占用率减少一半,训练速度加快一倍,这样加大bs以后训练速度可以变为t2t的三四倍。 - 首先
fairseq要让下两个包,一个是mosesdecoder里面有很多有用的脚本,其中一个是用来清除训练过程集合中过长的句子,以及一些src句子和tgt句子的长度比过大的句子。
MOSESDECODER=../mosesdecoder
$MOSESDECODER/scripts/training/clean-corpus-n.perl $TEXT/train zh en $TEXT/train.clean 3 70
$MOSESDECODER/scripts/training/clean-corpus-n.perl $TEXT/valid zh en $TEXT/valid.clean 3 70
- 一个是
subword_nmt是用来根据训练数据建立subword词表的,以及对训练集测试集验证集切分成subword的形式 -
learn_bpe.py的功能是从raw training set中学习一个subword的词表。 -
apply_bpe.py的功能是将刚才学到的词表对训练数据进行subword化。- 可以看到
apply_bpe.py的输入默认是从控制台输入的,而< file.txt的意思是将文件做为控制台进行输入,其实就相当于apply_bpe.py -i train.clean.cn。而> file.txt是将文件的输入重定向的文件,本来是在控制台输出的

- 可以看到
-
get_vocab.py就是将learn_bpe.py学到的词表进行排序然后加上索引

# build subword vocab
SUBWORD_NMT=../subword-nmt/subword_nmt
NUM_OPS=32000
# learn codes and encode separately
CODES=codes.${NUM_OPS}.bpe
echo "Encoding subword with BPE using ops=${NUM_OPS}"
$SUBWORD_NMT/learn_bpe.py -s ${NUM_OPS} < $TEXT/train.clean.en > $TEXT/${CODES}.en
$SUBWORD_NMT/learn_bpe.py -s ${NUM_OPS} < $TEXT/train.clean.zh > $TEXT/${CODES}.zh
echo "Applying vocab to training"
$SUBWORD_NMT/apply_bpe.py -c $TEXT/${CODES}.en < $TEXT/train.clean.en > $TEXT/train.${NUM_OPS}.bpe.en
$SUBWORD_NMT/apply_bpe.py -c $TEXT/${CODES}.zh < $TEXT/train.clean.zh > $TEXT/train.${NUM_OPS}.bpe.zh
VOCAB=vocab.${NUM_OPS}.bpe
echo "Generating vocab: ${VOCAB}.en"
cat $TEXT/train.${NUM_OPS}.bpe.en | $SUBWORD_NMT/get_vocab.py > $TEXT/${VOCAB}.en
echo "Generating vocab: ${VOCAB}.zh"
cat $TEXT/train.${NUM_OPS}.bpe.zh | $SUBWORD_NMT/get_vocab.py > $TEXT/${VOCAB}.zh
# encode validation
echo "Applying vocab to valid"
$SUBWORD_NMT/apply_bpe.py -c $TEXT/${CODES}.en --vocabulary $TEXT/${VOCAB}.en < $TEXT/valid.clean.en > $TEXT/valid.${NUM_OPS}.bpe.en
$SUBWORD_NMT/apply_bpe.py -c $TEXT/${CODES}.zh --vocabulary $TEXT/${VOCAB}.zh < $TEXT/valid.clean.zh > $TEXT/valid.${NUM_OPS}.bpe.zh
# encode test
echo "Applying vocab to test"
$SUBWORD_NMT/apply_bpe.py -c $TEXT/${CODES}.en --vocabulary $TEXT/${VOCAB}.en < $TEXT/test.en > $TEXT/test.${NUM_OPS}.bpe.en
$SUBWORD_NMT/apply_bpe.py -c $TEXT/${CODES}.zh --vocabulary $TEXT/${VOCAB}.zh < $TEXT/test.zh > $TEXT/test.${NUM_OPS}.bpe.zh
- 现在的疑惑就是词表到底是干啥的,为啥不在训练的时候使用这个词表,而是使用了
bpe,然后制作了词表用于后面的验证和测试。 - 没有什么用,
enfr的脚本里面就没有用到这个词表,直接用learn_bpe.py学到的bpe_tokens来对train test valid进行

训练阶段
-
preprocess.py就是把raw data(bpe)形式的数据转换成,二进制文件以及一些索引文件,因此是Binarize the dataset。
-
source_lang和target_lang还是不能省略,因为在里面是用这个找到训练数据和训练词表。


-
-
testpref和validpref可以同时传入多个文件,之间用逗号隔开。

- 所以在这里要注意了就是默认使用的词典是
trainpref目录下的那个词典,如果是要使用别的词典那么在preprocess的时候指定自己的词典。
- 所以在这里要注意了就是默认使用的词典是
python3 preprocess.py \
--source-lang en \
--target-lang de \
--tgtdict=$EN_DICT_PATH \
--srcdict=$DE_DICT_PATH \
--trainpref $TMP_DIR/train \
--validpref $TMP_DIR/valid \
--testpref $TMP_DIR/test \
--destdir $DATA_DIR
python3 train.py $DATA_DIR/ckpt \
--arch transformer_vaswani_wmt_en_de_big \ # --share-all-embeddings requires a joined dictionary
--optimizer adam --adam-betas '(0.9, 0.98)' \
--clip-norm 0.0 \
--lr-scheduler inverse_sqrt \
--warmup-init-lr 1e-07 \
--warmup-updates 4000 \
--lr 0.001 \
--min-lr 1e-09 \
--dropout 0.3 \
--weight-decay 0.0 \
--criterion label_smoothed_cross_entropy \
--label-smoothing 0.1 \
--max-tokens $TRAIN_BS \ # bs
--update-freq $GRADIENTS_ACCUMULATIONS \ # gradients accumulations is 32 then its equal to bs is 32 times than before
--tensorboard-logdir $TRAIN_DIR/log \
--log-format json --save-dir $TRAIN_DIR/log \
--fp16 # use-fp16
# Average 10 latest checkpoints:
python3 scripts/average_checkpoints.py \
--inputs $TRAIN_DIR/ckpt \
--num-epoch-checkpoints 10 \
--output $TRAIN_DIR/ckpt/model.pt
# generate preprocessed data
echo "Preprocessing datasets..."
DATADIR=data-bin/wmt17_zh_en
rm -rf $DATADIR
mkdir -p $DATADIR
fairseq-preprocess --source-lang zh --target-lang en \
--trainpref $TEXT/train.${NUM_OPS}.bpe --validpref $TEXT/valid.${NUM_OPS}.bpe --testpref $TEXT/test.${NUM_OPS}.bpe \
--thresholdsrc 0 --thresholdtgt 0 --workers 12 --destdir $DATADIR
# training
echo "Training begins"
mkdir -p checkpoints
fairseq-train $DATADIR \
-a transformer --optimizer adam -s zh -t en \
--label-smoothing 0.1 --dropout 0.3 --max-tokens 4000 \
--min-lr '1e-09' --lr-scheduler inverse_sqrt --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --max-update 200000 \
--warmup-updates 10000 --warmup-init-lr '1e-7' --lr '0.001' \
--adam-betas '(0.9, 0.98)' --adam-eps '1e-09' --clip-norm 25.0 \
--keep-last-epochs 20 --save-dir checkpoints --log-format json > train.log
- 多卡运行,在
8块V100一运行
# Training
SAVE="save/dynamic_conv_wmt16en2de"
mkdir -p $SAVE
python -m torch.distributed.launch --nproc_per_node 8 $(which fairseq-train) \
data-bin/wmt16_en_de_bpe32k --fp16 --log-interval 100 --no-progress-bar \
--max-update 30000 --share-all-embeddings --optimizer adam \
--adam-betas '(0.9, 0.98)' --lr-scheduler inverse_sqrt \
--clip-norm 0.0 --weight-decay 0.0 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--min-lr 1e-09 --update-freq 16 --attention-dropout 0.1 --keep-last-epochs 10 \
--ddp-backend=no_c10d --max-tokens 3584 \
--lr-scheduler cosine --warmup-init-lr 1e-7 --warmup-updates 10000 \
--lr-shrink 1 --max-lr 0.001 --lr 1e-7 --min-lr 1e-9 --warmup-init-lr 1e-07 \
--t-mult 1 --lr-period-updates 20000 \
--arch lightconv_wmt_en_de_big --save-dir $SAVE \
--dropout 0.3 --attention-dropout 0.1 --weight-dropout 0.1 \
--encoder-glu 1 --decoder-glu 1
- 极致的增大
bs,设置梯度累积,同时设置大bs以后还可以扩大学习率为原来的两倍,因此实验速度又大大变快了。

预处理脚本prepare-wmt14en2fr.sh
- 下载一个用于文本处理的包和一个用于
sub_word的包 - 然后下载所需要的训练数据,然后对训练数据处理从
sgm格式处理成一行一个文件的形式(raw_text)。 - 然后对
raw_text进行处理比如切分出来一部分当成验证集。 - 然后从训练数据中学习
bpe - 然后对训练数据,测试数据,验证数据应用
bpe - 然后将
src和tgt句子之比过长的句子以及句子超过250的句子进行丢弃。
perl $CLEAN -ratio 1.5 $tmp/bpe.train $src $tgt $prep/train 1 250
perl $CLEAN -ratio 1.5 $tmp/bpe.valid $src $tgt $prep/valid 1 250
- 最后将真正需要的训练数据
copy到外面
for L in $src $tgt; do
cp $tmp/bpe.test.$L $prep/test.$L
done
interactive
如果我们要想在预训练模型上测试我们自己的数据那么就需要使用python interactive.py脚本因为python generator.py脚本是针对目标文件夹中的二进制测试文件,顾名思义,interactive.py是以交互的方式生成翻译的语句对的,因此写个shell脚本用管道的方式传数据会很方便
- 因为
model使用的是BPE词表,因此在翻译之前需要将src文件转换成这种格式,使用apply_bpe.py脚本进行转换,下载的预训练模型自带了bpecodes文件用于进行转换。
$SUBWORD_NMT/apply_bpe.py -c $TEXT/${CODES}.en < $TEXT/train.clean.en > $TEXT/train.${NUM_OPS}.bpe.en
-
--remove-bpe在interactive.py中是用来将原来的句子中有各种@号变成了可以读的sentencepiece的句子,作用就相当于下面的sed命令
grep -P '^H' |cut -f3- | sed 's/@@\s*//g' > translation.en
- 下面两个代码的作用是一样的
cat $TEXT_FILE_PATH | python3 $SUBWORD_NMT/apply_bpe.py -c $SUBWORD_PATH | \
python3 interactive.py $(dirname $CHECKPOINT_PATH)\
--path $CHECKPOINT_PATH \
--beam $BEAM_SIZE \
--source-lang $SOURCE_LANG \
--target-lang $TARGET_LANG \
--fp16 \
--num-workers 12 \
--batch-size $DECODER_BS \
--buffer-size $DECODER_BS | grep -P '^H' |cut -f3- | sed 's/@@\s*//g' | tee $TRAIN_DIR/$TRANS-$FLAGS.translation.$TARGET_LANG
cat $TEXT_FILE_PATH | python3 $SUBWORD_NMT/apply_bpe.py -c $SUBWORD_PATH | \
python3 interactive.py $(dirname $CHECKPOINT_PATH)\
--path $CHECKPOINT_PATH \
--beam $BEAM_SIZE \
--source-lang $SOURCE_LANG \
--target-lang $TARGET_LANG \
--fp16 \
--num-workers 12 \
--remove-bpe \
--batch-size $DECODER_BS \
--buffer-size $DECODER_BS | grep -P '^H' |cut -f3- | tee $TRAIN_DIR/$TRANS-$FLAGS.translation.$TARGET_LANG
fairseq论文里面的东西
- 每个
mini-batch都是一样的大小,以便最小的进行padding,因此每个epoch只对batch之间进行shuffle。

- 加速原理,多个
batch以后才一起更新
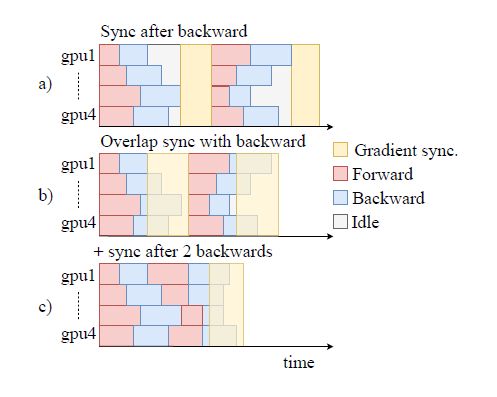
- 每个
GPU上都有一个模型的副本 -
fp16是在前向计算和后项计算的时候使用的,更新模型参数的时候先把梯度转换成fp32然后再更新参数。

- 推理的时候是用的是
no-recurrent模型,所以才这么快

- 推断的时候也可以使用
fp16,效果不变,加速50%,并且decoder的时候设置的bs是最大可以使用的bs。

- 在翻译中
en-de和en-fr都是使用的BPE只不过en-de的BPE的词表是32K,而英法的BPE的词表是40K。
