一、简介
- EM算法
最大期望算法(Expectation-maximization algorithm,简称EM,又译期望最大化算法)在统计中被用于寻找依赖于不可观察的隐性变量的概率模型中,参数的最大似然估计。在统计计算中,最大期望(EM)算法是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐性变量。最大期望算法经常用在机器学习和计算机视觉得数据聚类领域。EM算法的标准计算框架由E步和M步交替组成,算法的收敛可以确保迭代至少逼近局部极大值。EM算法被广泛应用于处理数据的缺失值,以及很多机器学习算法,包括高斯混合模型和隐马尔科夫模型的参数估计。
- Jensen不等式(又名琴生不等式、詹森不等式)
琴生不等式是以丹麦技术大学数学家约翰·延森(Johan Jensen)命名,它给出积分的凸函数值和凸函数的积分值间的关系。Jensen不等式是关于凸函数性质的不等式,它和凸函数的定义是息息相关的。

- 设f是定义域为实数的函数,如果对于所有的实数x,f(x)的二次导数大于等于0,那么f是凸函数
- 如果f是凸函数,X是随机变量,那么满足Jensen不等式:
- Jensen不等式应用于凹函数时,不等号方向反向。
二、算法原理
1、实例解析

这里有两个硬币分别是A和B,我们进行抛硬币的实验,假设这两个硬币做过手脚,出现正反面的概率不同,初始假设为:
A:0.6几率正面
B:0.5几率正面
那么我们分别抛10次硬币,会出现5正5反的概率:
选择硬币A的概率:
选择硬币B的概率:
我们跟着箭头一步一步看:
第一步:给出了初始假设,选择两个硬币的正面概率分别是0.6和0.5
-
第二步:E-step
- 1、初始值选择A的概率是:0.45,此时有5次H,5次T,可以计算出
选择B的概率是:0.55,此时有5次H,5次T,可以计算出
- 2、先来看一下投掷出9次正面1次反面的概率
选择硬币A的概率选择硬币B的概率
我们分别计算硬币A正反面的期望:
硬币B正反面的期望:
- 3、依次计算出所有的样本,并分别将A和B硬币出现H和T的期望求和,
A硬币:
B硬币:
第三步:M-step
通过E-step计算的结果分别求出两个硬币的分布,
将上述两个结果带入第一步进行迭代,不断更新P(A)和P(B),直到结果收敛为止就得到了我们需要的结果。
2、公式推导
(1) 问题:样本集,包含m个独立的样本,其中每个样本对应的类别是未知的,所以很难用最大似然求解
上式中,要考虑每个样本在各个分布中的情况,本来正常求偏导就可以了,但是现在后面还有求和,这就难解了。(2) 右式分子分母同时乘(是的分布函数)
为什么这么做?目的是凑Jensen不等式-
(3) 利用Jensen不等式求解
由于是的期望
假设 ,则
此时:
-
(4) 结论
下界比较好求,所以我们要优化这个下界来使得似然函数最大。
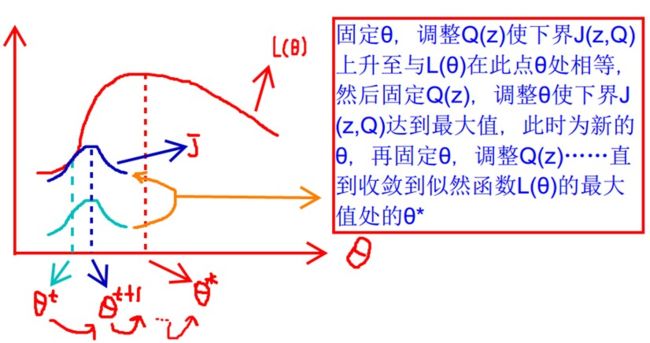
如何能使得等式成立呢?(取等号)
根据Jensen中等式成立的条件是随机变量是常数,则:
由于是z的分布函数,则关于分布函数的和一定为1:
由上式可得,所有的分子和等于常数C(分母相同),即C就是对z求和
代表第个数据是来自的概率,在固定后,使下界拉升的的计算公式,解决了如何选择的问题。这一步就是E-step,建立的下界。接下来的M-step,就是在给定后,调整,去极大化的下界。
3、总结
EM算法流程
1、初始化分布参数
2、E-step:根据参数计算每个样本属于的概率(也就是我们的Q)
3、M-step:根据Q,求出含有的似然函数的下界并最大化它,得到新的参数
4、不断地迭代更新下去,直到收敛。
三、GMM(高斯混合模型)
GMM(Gaussian mixture model),高斯混合模型,也可以简写成MOG.高斯模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,将一个事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型。GMM已经在数值逼近、语音识别、图像分类、图像去噪、图像重构、故障诊断、视频分析、邮件过滤、密度估计、目标识别与跟踪等领域取得了良好的效果。实际上,GMM的目的就是找到一个合适的高斯分布(也就是确定高斯分布的参数μ,Σ),使得这个高斯分布能产生这组样本的可能性尽可能大(即:拟合样本数据)。高斯混合模型也被视为一种聚类方法,是机器学习中对“无标签数据”进行训练得到的分类结果。其分类结果由概率表示,概率大者,则认为属于这一类。
1、算法适合的情形:
数据内部有多个类别,每个类别的数据呈现不同的分布,这时我们就可以使用GMM算法,尤其是有隐变量,隐变量有不同的分布。
2、公式推导
一般化的描述为:假设混合高斯模型由K个高斯模型组成(即数据包含K个类),则GMM的概率密度函数如下:
其中,是第k个高斯模型的概率密度函数,可以看成选定第K个模型后,该模型产生x的概率;是第k个高斯模型的权重,称作选择第K个模型的先验概率,且满足,
概率密度知道后,我们看一下最大化对数似然函数的意义:
首先直观化地解释一下最大化对数似然函数要解决的是什么问题。
假设我们采样得到一组样本yt ,而且知道变量Y服从高斯分布(本文只提及高斯分布,其他变量分布模型类似),数学形式表示为Y∼N(μ,Σ)。采样的样本如下图所示,我们的目的就是找到一个合适的高斯分布(也就是确定高斯分布的参数μ,Σ),使得这个高斯分布能产生这组样本的可能性尽可能大。那怎么找到这个合适的高斯分布呢(在如下图中的表示就是1~4哪个分布较为合适)?这时候似然函数就闪亮登场了。
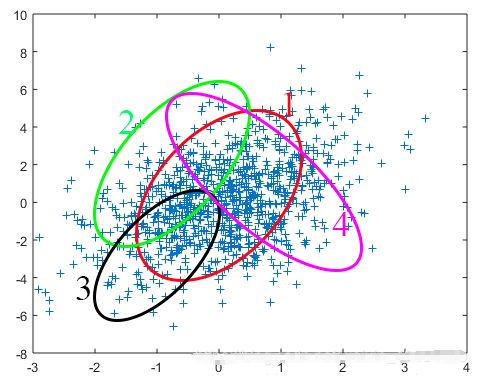
似然函数数学化:设有样本集是高斯分布的概率分布函数,表示变量的概率。假设样本的抽样是独立的,那么我们同时抽到这N个样本的概率是抽到每个样本概率的乘积,也就是样本集Y的联合概率。此联合概率即为似然函数:
对上式进行求导并令导数为0(即最大化似然函数,一般还会先转化为对数函数再最大化),所求出的参数就是最佳的高斯分布对应的参数。所以最大化似然函数的意义就是:通过使得样本集的联合概率最大来对参数进行估计,从而选择最佳的分布模型。
我们尝试使用最大化对数似然函数来解决GMM模型,然后求导,令导数为0,就可以得到模型参数(μ,Σ,π) ,然而仔细观察可以发现,对数似然函数里面,对数里面还有求和。实际上没有办法通过求导的方法来求这个对数似然函数的最大值。此时,就需要借助EM算法来解决此问题了
接下来我们使用EM算法求解GMM模型,
EM算法可以用于解决数据缺失的参数估计问题(隐变量的存在实际上就是数据缺失问题,缺失了各个样本来源于哪一类的记录)。
引入隐变量,它的取值只能是1或者0。
取值为1:第j个观测变量来自第k个高斯分量
取值为0:第j个观测变量不是来自第k个高斯分量
那么对于每一个观测数据都会对应于一个向量变量,,那么有:
其中,K为GMM高斯分量的个数, 为第k个高斯分量的权值。因为观测数据来自GMM的各个高斯分量相互独立,而 刚好可以看做是观测数据来自第k个高斯分量的概率,因此可以直接通过连乘得到整个隐变量的先验分布概率。
得到完全数据的似然函数
对于观测数据,当已知其是哪个高斯分量生成的之后,其服从的概率分布为: 由于观测数据从哪个高斯分量生成这个事件之间的相互独立的,因此可以写成:
这样我们就得到了已知的情况下单个测试数据的后验概率分布。结合之前得到的的先验分布,则我们可以写出单个完全观测数据的似然函数为:取对数,得到对数似然函数为:得到各个高斯分量的参数计算公式,
首先,我们将上式的根据单高斯的向量形式的概率密度函数的表达形式展开:
假设我们已经知道隐变量的取值,对上面得到的似然函数分别对和求偏导并且偏导结果为零,可以得到:
现在参数空间中剩下一个还没有求。这时一个约束满足问题,因为必须满足约束.我们使用拉格朗日乘数法结合似然函数和约束条件对求偏导,可以得到:将上式的左右两边分别对k=1,2,...,K求和,可以得到:,
将带入,最终得到:至此,我们在隐变量已知的情况下得到了GMM的三种类型参数的求解公式。
得到隐变量的估计公式
根据EM算法,现在我们需要通过当前参数的取值得到隐变量的估计公式也就是说隐变量的期望的表现形式。即如何求解。
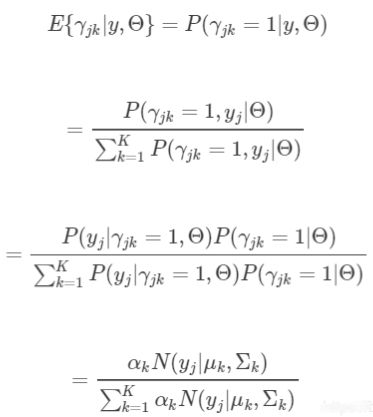
四、案例分析
案例一
这里的数据集是每天经过美国西雅图弗莱蒙特桥上自行车的数量,时间间隔是[2012/10/02-2014/5/31]有需要的同学可以私信。
1、先来看一下数据集
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.mixture import GaussianMixture
def dataset():
"""
读取数据并处理
:return:
"""
data = pd.read_csv('../../../数据集/机器学习/EM算法/FremontHourly.csv',index_col='Date',parse_dates=True)
print(data.head(20))
if __name__=="__main__":
dataset()

2、将数据以图的形式展示
data.plot()
plt.show()
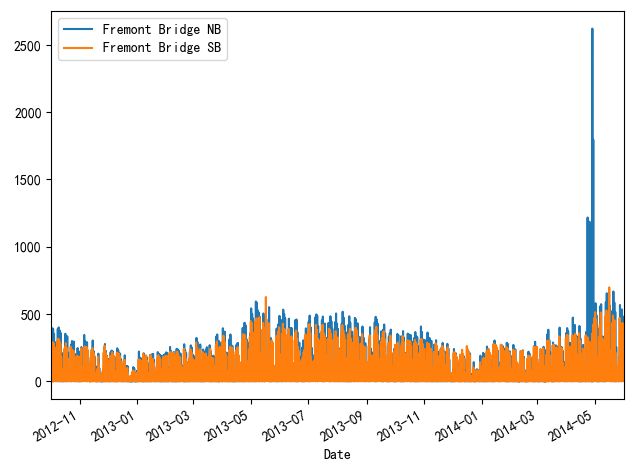
这时我们发现数据太多密集,我们以"周(week)"的形式展示
#在时间上进行重采样
data.resample('w').sum().plot()
plt.show()
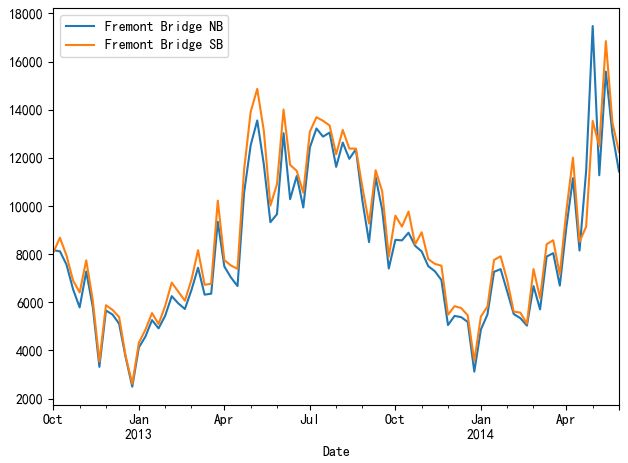
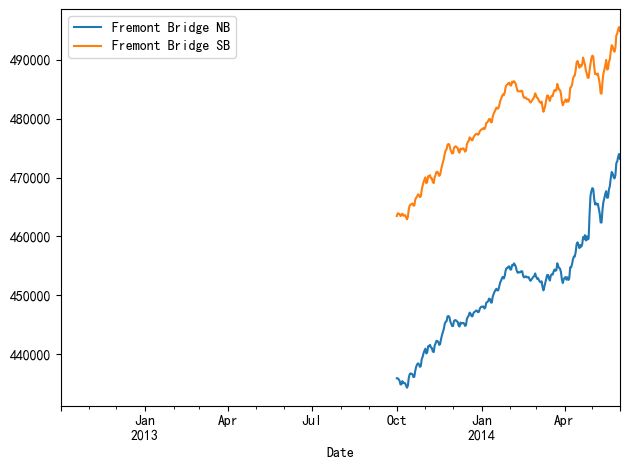
我们还可以以"天(day)"的形式将一年的数据呈现出来
data.resample('D').sum().rolling(365).sum().plot()
plt.show()
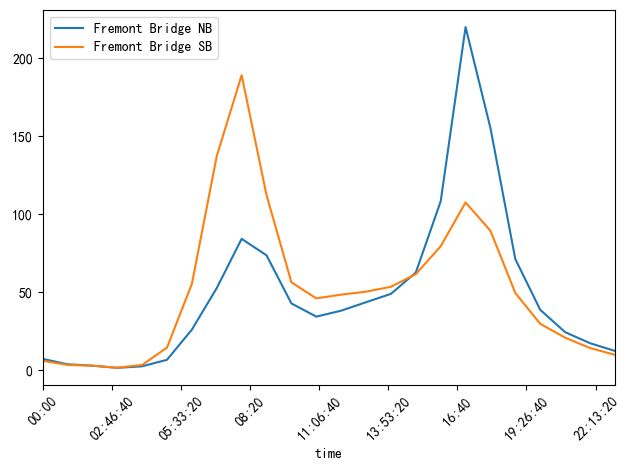
我们按照每天的时间进行求平均值,看一下一天的那个时间点是峰值
data.groupby(data.index.time).mean().plot()
plt.xticks(rotation=45)
plt.show()
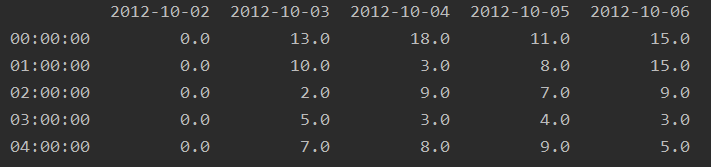
我们按照桥的两侧,分别计算每个时间点的停车量
data.columns=['East','West']
data['Total']=data['East']+data['West']
pivoted = data.pivot_table('Total',index=data.index.time,columns=data.index.date)
print(pivoted.iloc[:5,:5])
pivoted.plot(legend=False,alpha=0.01)
plt.xticks(rotation=45)
plt.show()
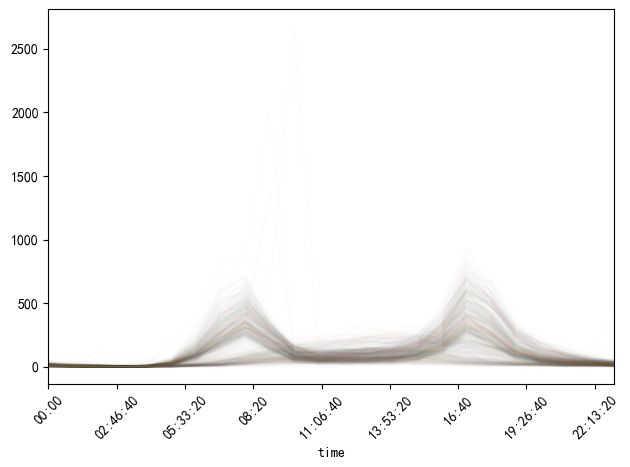
由于数据量比较少,上图不是很清晰,但是可以隐约看到是有两种分布的数据存在。
接下来我们看一下数据结构,
print(pivoted.shape)
通过上图我们得知数据是24 x 607的矩阵,这对于聚类来说是不合理的,数据量太少特征值过多,所以这里我们将矩阵进行转置,
X = pivoted.fillna(0).T.values
print(X.shape)
这时数据处理完后,我们发现特征值有点多,所以我们利用PCA进行降维处理,降到两维,我们看一下图像,
#PCA降维成2维
pca = PCA(n_components=2)
Y = pca.fit_transform(X)
# print(Y.shape)
plt.scatter(Y[:,0],Y[:,1])
plt.show()

降维结束后,我们开始使用GMM算法进行聚类,首先我们先看一下聚成两类之后的概率值,由于数据集比较明显,所以分出的概率值差异比较大,
def gmm(data,pivoted):
"""
利用GMM聚类算法进行聚类
:return:
"""
gmm = GaussianMixture(n_components=2)#两种高斯分布
gmm.fit(data)
labels = gmm.predict_proba(data)
x = gmm.predict(data)
print(labels)
if __name__=="__main__":
data,pivoted = dataset()
gmm(data,pivoted)
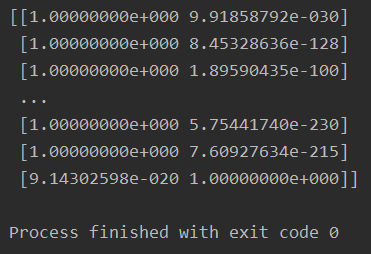
我们输出一下分类的结果看一下,
print(x)

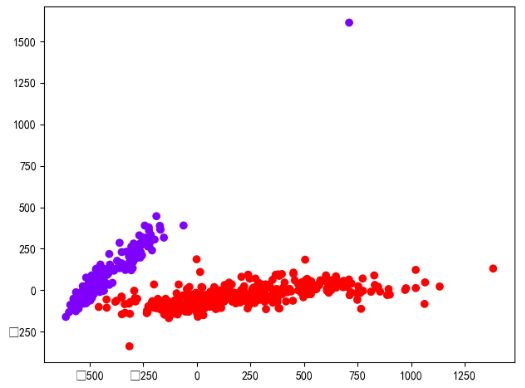
接下来我们画图看一下分类的结果,
plt.scatter(data[:,0],data[:,1],c=x,cmap='rainbow')
plt.show()
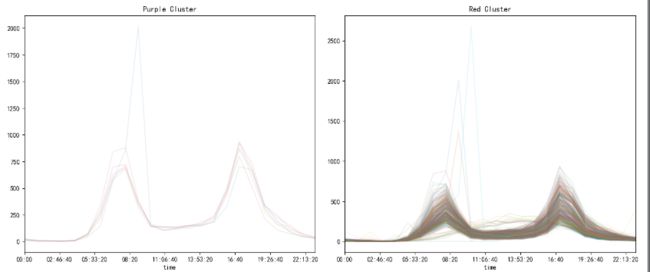
最后我们看一下原始数据集分类后的分布图
fig, ax = plt.subplots(1, 2, figsize=(14, 6))
pivoted.T[labels == 0].T.plot(legend = False,alpha=0.1,ax=ax[0])
pivoted.T[labels == 1].T.plot(legend=False, alpha=0.1, ax=ax[1])
ax[0].set_title('Purple Cluster')
ax[1].set_title('Red Cluster')
plt.show()
这里是所有的代码
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.mixture import GaussianMixture
def dataset():
"""
读取数据并处理
:return:
"""
data = pd.read_csv('../../../数据集/机器学习/EM算法/FremontHourly.csv',index_col='Date',parse_dates=True)
# print(data.head(30))
# data.plot()
# plt.show()
# #在时间上进行重采样
# data.resample('w').sum().plot()
# data.resample('D').sum().rolling(365).sum().plot()
# plt.show()
# data.groupby(data.index.time).mean().plot()
# plt.xticks(rotation=45)
# plt.show()
data.columns=['East','West']
data['Total']=data['East']+data['West']
pivoted = data.pivot_table('Total',index=data.index.time,columns=data.index.date)
print(pivoted.iloc[:5,:5])
pivoted.plot(legend=False,alpha=0.01)
plt.xticks(rotation=45)
plt.show()
# print(pivoted.shape)
X = pivoted.fillna(0).T.values
print(X.shape)
#PCA降维成2维
pca = PCA(n_components=2)
Y = pca.fit_transform(X)
# print(Y.shape)
plt.scatter(Y[:,0],Y[:,1])
plt.show()
return Y,pivoted
def gmm(data,pivoted):
"""
利用GMM聚类算法进行聚类
:return:
"""
gmm = GaussianMixture(n_components=2)#两种高斯分布
gmm.fit(data)
labels = gmm.predict_proba(data)
x = gmm.predict(data)
print(labels)
plt.scatter(data[:,0],data[:,1],c=x,cmap='rainbow')
plt.show()
fig, ax = plt.subplots(1, 2, figsize=(14, 6))
pivoted.T[labels == 0].T.plot(legend = False,alpha=0.1,ax=ax[0])
pivoted.T[labels == 1].T.plot(legend=False, alpha=0.1, ax=ax[1])
ax[0].set_title('Purple Cluster')
ax[1].set_title('Red Cluster')
plt.show()
return None
if __name__=="__main__":
data,pivoted = dataset()
gmm(data,pivoted)
案例二
这里我们举例对比一下GMM算法与K-means算法的聚类效果。
首先我们先制作一些数据集,同时画图展示一下。
from sklearn.datasets.samples_generator import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
import numpy as np
def datasets():
"""
使用datasets包产生一些数据
:return:
"""
plt.rcParams['axes.unicode_minus'] = False#解决不显示负数问题
X,y_true = make_blobs(n_samples=800,centers=4,random_state=11)
plt.scatter(X[:,0],X[:,1])
plt.show()
if __name__ == "__main__":
datasets()
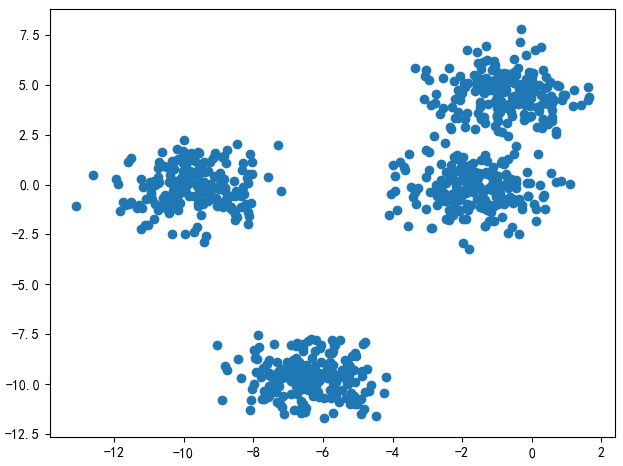
接下来我们先用K-means算法聚类一下,看看效果。
def GmmKmean(data):
"""
GMM算法与Kmeans算法对比
:return:
"""
kmeans = KMeans(n_clusters=4)
kmeans.fit(data)
y_kmeans = kmeans.predict(data)
plt.scatter(data[:,0],data[:,1],c=y_kmeans,s=50,cmap='viridis')
plt.show()
centers = kmeans.cluster_centers_
print(centers)
return None
if __name__ == "__main__":
data = datasets()
GmmKmean(data)
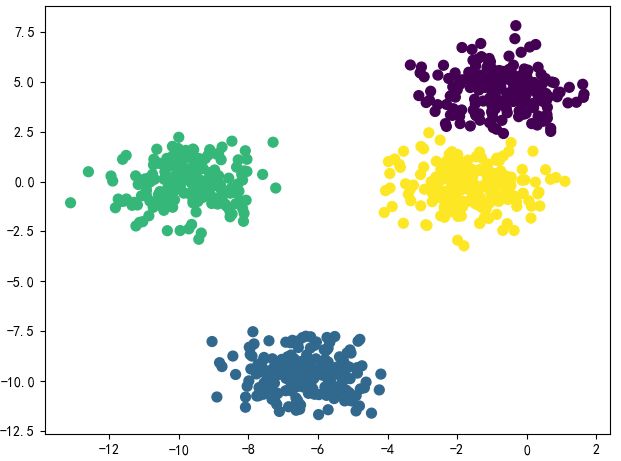
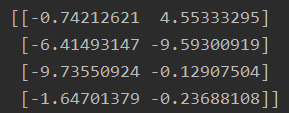
我们再用GMM算法实现一下,
gmm = GaussianMixture(n_components=4,random_state=1)
gmm.fit(data)
labels = gmm.predict(data)
plt.scatter(data[:,0],data[:,1],c=labels,s=40,cmap='viridis')
plt.show()
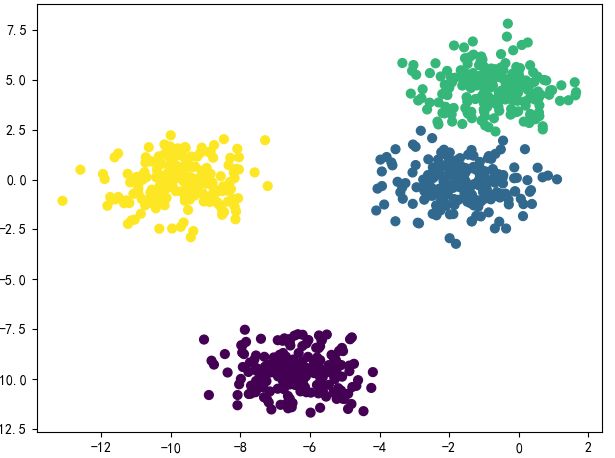
通过上面两个算法的对比,我们发现比较简单的数据集上,两者的分类效果差不多。
接下来,我们再制作一些数据集对比一下聚类效果,
plt.show()
rng = np.random.RandomState(13)
Y = np.dot(X,rng.randn(2,2))
plt.scatter(Y[:,0],Y[:,1])
plt.show()
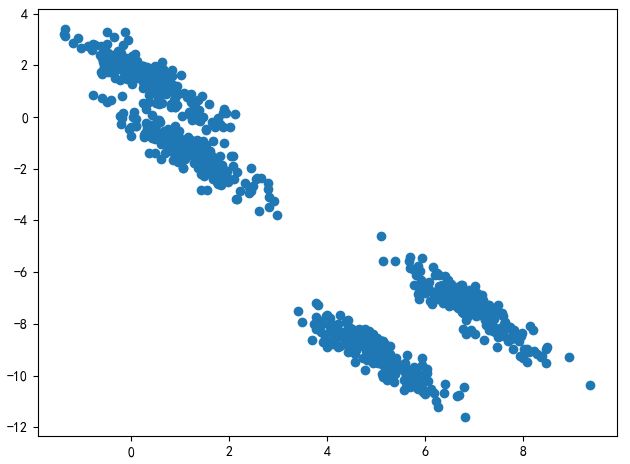
我们的目的是希望能分出四个类,左上角两个,右下角两个
首先我们先看一下K-means算法的效果,
kmeansy = KMeans(n_clusters=4,random_state=1)
kmeansy.fit(dataY)
datay_kmeans = kmeansy.predict(dataY)
plt.scatter(dataY[:,0],dataY[:,1],c=datay_kmeans,s=40,cmap='viridis')
plt.show()
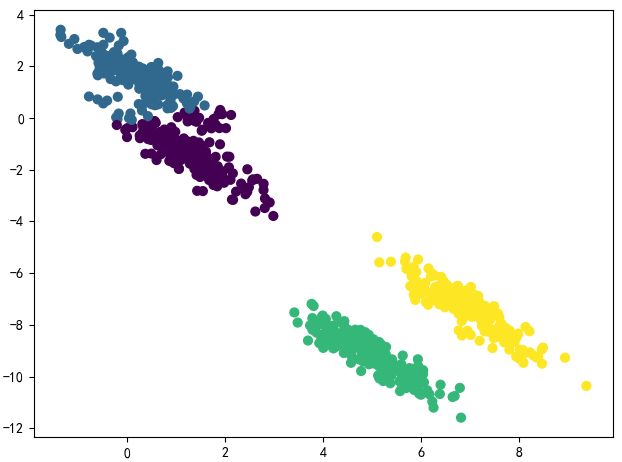
通过上图我们发现,K-means算法能够聚类出来,但是左上角两个类分出的效果并不是很理想,接下来我们用GMM算法再聚类一下,
gmm.fit(dataY)
labelsY = gmm.predict(dataY)
plt.scatter(dataY[:,0],dataY[:,1],c=labelsY,s=40,cmap='viridis')
plt.show()
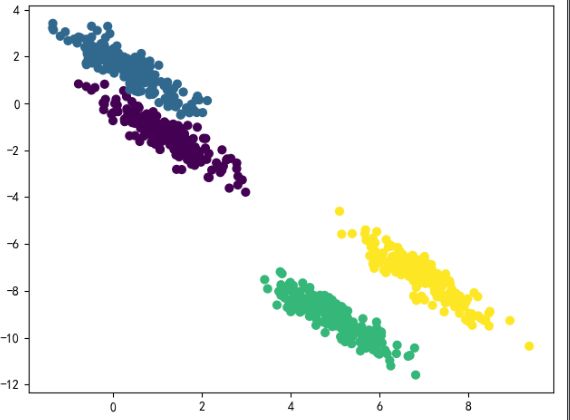
这时我们发现GMM算法的聚类效果就非常好。
代码在这里展示一下,
from sklearn.datasets.samples_generator import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
import numpy as np
def datasets():
"""
使用datasets包产生一些数据
:return:
"""
plt.rcParams['axes.unicode_minus'] = False#解决不显示负数问题
X,y_true = make_blobs(n_samples=800,centers=4,random_state=11)
plt.scatter(X[:,0],X[:,1])
plt.show()
rng = np.random.RandomState(13)
Y = np.dot(X,rng.randn(2,2))
plt.scatter(Y[:,0],Y[:,1])
plt.show()
return X,Y
def GmmKmean(data,dataY):
"""
GMM算法与Kmeans算法对比
:return:
"""
kmeans = KMeans(n_clusters=4)
kmeans.fit(data)
y_kmeans = kmeans.predict(data)
plt.scatter(data[:,0],data[:,1],c=y_kmeans,s=50,cmap='viridis')
plt.show()
centers = kmeans.cluster_centers_
print(centers)
gmm = GaussianMixture(n_components=4,random_state=1)
gmm.fit(data)
labels = gmm.predict(data)
plt.scatter(data[:,0],data[:,1],c=labels,s=40,cmap='viridis')
plt.show()
kmeansy = KMeans(n_clusters=4,random_state=1)
kmeansy.fit(dataY)
datay_kmeans = kmeansy.predict(dataY)
plt.scatter(dataY[:,0],dataY[:,1],c=datay_kmeans,s=40,cmap='viridis')
plt.show()
# gmmY = GaussianMixture(n_components=4)
gmm.fit(dataY)
labelsY = gmm.predict(dataY)
plt.scatter(dataY[:,0],dataY[:,1],c=labelsY,s=40,cmap='viridis')
plt.show()
return None
if __name__ == "__main__":
data,dataY = datasets()
GmmKmean(data,dataY)
好了,EM算法与GMM算法的学习到这里就结束了,本节的公式推导比较多,希望大家能够手动推一下!