一、背景
到目前为止quartz集群模式必须开启存储模式才可以使用,我这边存储使用的是mysql数据库;因为我本人看源码喜欢从多维度去剖析,今天希望通过结合mysql-binlog日志的方式了解一下quartz的集群环境下的启动过程;
二、首先配置mysql开启binlog日志功能
因为binlog默认是关闭的;可以通过修改my.ini文件来实现,有一种简单的配置,一个参数就可以搞定
log-bin=/var/lib/mysql/mysql-bin
具体也可以百度一下怎么开启binlog; binlog日志只记录新增、修改、删除的SQL;
三、启动quartz服务,查看binlog
在停止一个quartz集群节点一段时间后(本例是3分钟),重新启动该quartz节点, 应用启动完成后已经产生了一部分binlog日志,这时我想导出来查看到底做了哪些修改操作; 因为binlog日志是二进制文件不能直接阅读,因此通过mysql/bin/目录下的mysqlbinlog工具导出binlog日志;
./mysqlbinlog ../logs/mysql-bin.000001 > d:/binlog.txt;
然后打开binlog.txt看一下mysql的binlog日志如下
# at 347638
#181017 9:07:05 server id 1 end_log_pos 347870 Query thread_id=18 exec_time=0 error_code=0
SET TIMESTAMP=1539738425/*!*/;
UPDATE JOB_QRTZ_SCHEDULER_STATE SET LAST_CHECKIN_TIME = 1539738425978 WHERE SCHED_NAME = 'schedulerFactoryBean' AND INSTANCE_NAME = 'DESKTOP-7U74VP91539738404656'
/*!*/;
# at 347870
#181017 9:07:05 server id 1 end_log_pos 348128 Query thread_id=18 exec_time=0 error_code=0
SET TIMESTAMP=1539738425/*!*/;
INSERT INTO JOB_QRTZ_SCHEDULER_STATE (SCHED_NAME, INSTANCE_NAME, LAST_CHECKIN_TIME, CHECKIN_INTERVAL) VALUES('schedulerFactoryBean', 'DESKTOP-7U74VP91539738404656', 1539738425978, 5000000)
/*!*/;
# at 348128
#181017 9:07:05 server id 1 end_log_pos 348326 Query thread_id=18 exec_time=0 error_code=0
SET TIMESTAMP=1539738425/*!*/;
DELETE FROM JOB_QRTZ_FIRED_TRIGGERS WHERE SCHED_NAME = 'schedulerFactoryBean' AND INSTANCE_NAME = 'DESKTOP-7U74VP91539681653705'
/*!*/;
# at 348326
#181017 9:07:05 server id 1 end_log_pos 348525 Query thread_id=18 exec_time=0 error_code=0
SET TIMESTAMP=1539738425/*!*/;
DELETE FROM JOB_QRTZ_SCHEDULER_STATE WHERE SCHED_NAME = 'schedulerFactoryBean' AND INSTANCE_NAME = 'DESKTOP-7U74VP91539681653705'
去除不必要的日志,主要是以下4个语句
1.当前实例心跳,更新心跳时间LAST_CHECKIN_TIME
UPDATE JOB_QRTZ_SCHEDULER_STATE SET ....
2.如果上面返回结果为0,即更新失败,则新增一个服务器实例
INSERT INTO JOB_QRTZ_SCHEDULER_STATE ....
3.删除与心跳失败的实例关联的即将触发或正在出发的记录(FIRED_TRIGGERS)
DELETE FROM JOB_QRTZ_FIRED_TRIGGERS WHERE...
4.删除心跳失败的实例
DELETE FROM JOB_QRTZ_SCHEDULER_STATE WHERE...
四、分析源码
本实例使用spring+quartz+mysql来启动的;
quartz.properties配置了集群属性org.quartz.jobStore.isClustered: true
1.先看Spring工厂类SchedulerFactoryBean的定义和初始化
public class SchedulerFactoryBean extends SchedulerAccessorimplements FactoryBean,
BeanNameAware, ApplicationContextAware, InitializingBean, DisposableBean, SmartLifecycle
1.1 SchedulerFactoryBean 实现了InitializingBean接口
在初始化时通过afterPropertiesSet方法调用createScheduler方法完成属性scheduler的实例化即StdScheduler
@Override
public void afterPropertiesSet()throws Exception {
if (this.dataSource ==null &&this.nonTransactionalDataSource !=null) {
this.dataSource =this.nonTransactionalDataSource;
}
.............................此处省略部分代码............................................................
// Get Scheduler instance from SchedulerFactory.
try {
this.scheduler = createScheduler(schedulerFactory, this.schedulerName);
.............................此处省略部分代码............................................................
registerListeners();
registerJobsAndTriggers();
}
1.2 SchedulerFactoryBean 实现了SmartLifecycle接口
自动启动autoStartup属性默认值为true,可以调用start方法,start再调用startScheduler方法

startScheduler方法利用上一步1.1初始化得到的scheduler属性最终调用scheduler.start()

接上scheduler.start()也即StdScheduler实例的start()直接调用了sched.start()


通过QuartzScheduler的start方法,调用本文的重点 getJobStore().scheduleStarted();

2. 分析任务持久化jobStore的基础抽象类JobStoreSupport
接上文getJobStore().scheduleStarted(),使用的是JobStoreSupport实例的方法scheduleStarted()方法,初始化了一个集群管理的后台线程ClusterManager, 即initialize()方法
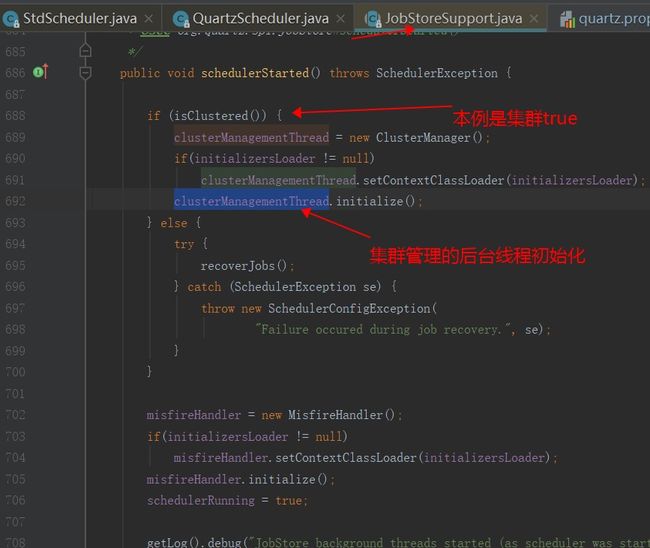

接着看doCheckin方法,因为是初始化,所以执行clusterCheckIn

这个方法的返回值是长时间没有心跳的失败节点, 我们本例的背景前提即是停止服务节点一段时间后启动服务器的,所以数据库里记录的心跳节点已经长时间没有更新了;详见findFailedInstances()
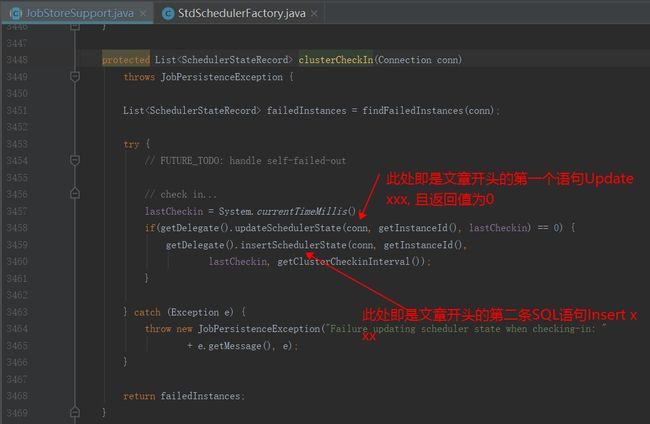
clusterCheckIn方法执行完回到doCheckin方法,因为此时肯定有失败的实例即failedInstances, 所以程序会运行到clusterRecover(conn, failedRecords)方法

总结
1.spring环境下的quartz是通过工厂类SchedulerFactoryBean来实现初始化的,SchedulerFactoryBean通过实现接口InitializingBean进行初始化各种资源和schedule, SchedulerFactoryBean通过实现接口SmartLifecycle来自动执行start方法等从而实现了quartz的初始化
2.quartz在初始化的最后,通过QuartzScheduler的start方法,调用了getJobStore().scheduleStarted(); 而JobStoreSupport在实现这个方法时,启动了一个线程ClusterManager, 在初始化时进行失败实例的检测,并且也启动了该线程一直循环检测失败实例;
3.当一个集群节点从故障中恢复或者重启,一般都会执行4个SQL语句,其中前两个是用于更新/新增 本节点的心跳信息;第3个是删除集群中失败节点所触发任务的数据FIRED_TRIGGERS(保存了任务被哪个集群节点所调度的信息), 第4个SQL语句是删除集群中失败的节点;
4.quartz集群的Failover就是通过ClusterManager的一直循环执行clusterRecover方法来实现的
4.1 clusterRecover方法执行时会检查失败节点上的之前没有完成调度的任务,当任务的requestsRecovery属性为true的时候会直接被当前正常运行的节点接管过来并运行一次;
4.2 clusterRecover方法执行时会检查失败节点上曾经获取过的任务,并把这些任务的状态由STATE_ACQUIRED修改为STATE_WAITING,以便集群中的正常运行节点可以在下次获取任务时获取到该任务进行调度