近期易观公司举办了一个OLAP大赛,我们队伍非常荣幸地获得了第一名,成为本次比赛最大黑马。此篇文章主要分享一下我们是如何解决有序漏斗秒查问题的
比赛地址:2017易观OLAP算法大赛
参赛情况: https://www.analysys.cn/media/detail/20018458/
1. 题目分析:
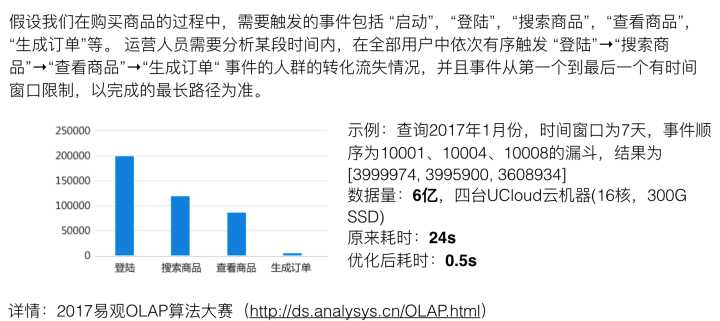
在以上示例场景下,我们在易观提供的6亿测试数据集上,在4台UCloud云主机(16core,16G ram)机器下从24s优化到了0.5s。而在正式比赛的26亿数据集上,使用相同硬件环境,耗时1.6s。
2. 解题分析:
题目描述的有序漏斗问题可以归结为带滑动时间窗口的最左子序列问题, 比如我们需要寻找,2017年7月份中,在3小时的时间窗口下, [A,B,C,D] 漏斗路径下的转化情况, 单个用户只能有 NULL , [a], [A,B], [A,B,C], [A,B,C,D] 五种转化结果,对应的漏斗深度我们称之为level,在[A,B,C,D]漏斗路径下,level的取值可以有[0,1,2,3,4] 四个值,题目的要求即算出所有用户的满足条件下最大level汇总结果。
理解问题之后,我们梳理了一下流程图:
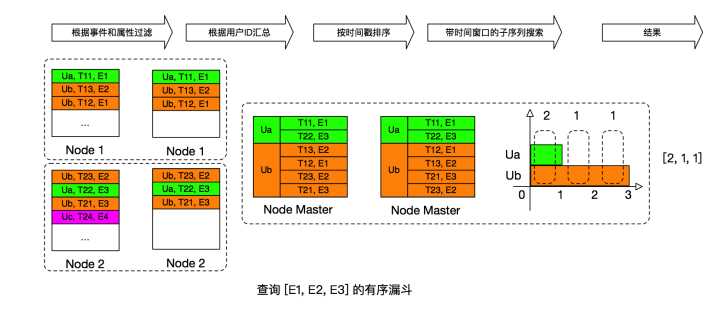
我们将问题解决分为5个步骤:
filter阶段 :根据时间区间和事件属性对数据进行过滤
group阶段: 根据用户Id进行group汇总
sort阶段: 按照时间进行排序
algorithm aggregate 阶段: 带时间窗口的子序列搜索
合并结果
3. 数据库选型:
根据以上分析,需要filter,group,sort,aggregate等操作,数据库是必备的核心,而在OLAP领域,开源的数据库选型有很多,比如:mysql, druid, kylin hdfs + (hive,spark,presto),imapla, kudu etc。
但在这个场景下,结合以往对其他数据的深入研究分析对比经验,我们几乎毫不犹豫就选择了ClickHouse(纵然它不支持udaf),,我们相信ClickHouse是目前cpu领域最快的olap开源数据库,它最突出的优点就是快,如果你是第一次用,相信ClickHouse会让你感到非常惊艳。

ClickHouse 由俄罗斯Yandex开发,09年原型,12年生产可用,16年开源,目前最大的线上部署实例是 Yandex.Metrica: 472个节点,每秒处理2T数据,实时在线分析。ClickHouse 在OLAP上的查询性能非常彪悍,平均查询性能几乎是vertica的三倍。
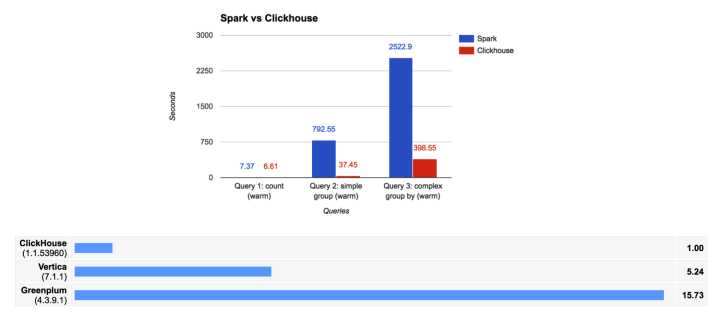
ClickHouse不仅速度快,它系统架构灵活,性能优越,代码优雅, 非常适合大数据下需要极致性能的应用场景。ClickHouse目前暂不支持UDAF,但没关系,我们可以通过修改源代码并重新编译来实现自定义AggregateFunction。
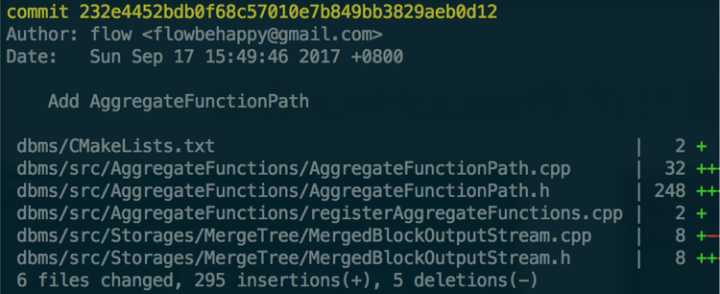
以上就是针对漏斗场景的代码修改情况,可以看出我们只用了不到300行代码就为ClickHouse加入了漏斗计算(aggregate function path)的功能。
对比官方的presto + hdfs 方案实现的24s速度,使用ClickHouse之后,我们在测试环境下跑的速度达到了8s。
下面开始我们的正式优化过程
4. 按照用户ID分区:
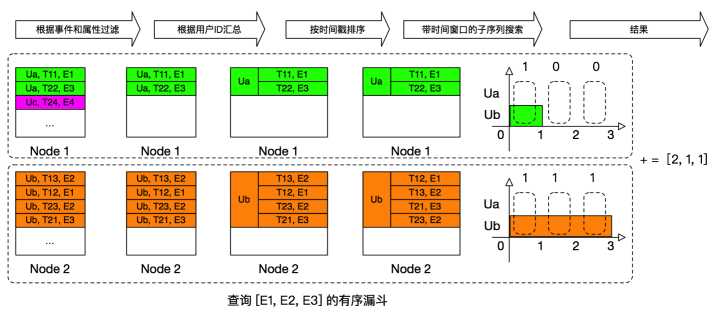
我们注意到,漏斗的计算中,每个用户都是相互独立的,所以我们可以将数据按照uid来分区,这样就将数据分散到了四台机器上,我们可以分别向每个数据库节点发送请求,然后将数据进行汇总,得到最终结果。
通过这次优化,我们在测试环境下跑的速度达到了1.6s。
5. 以(uid,timestamp)作为primary key
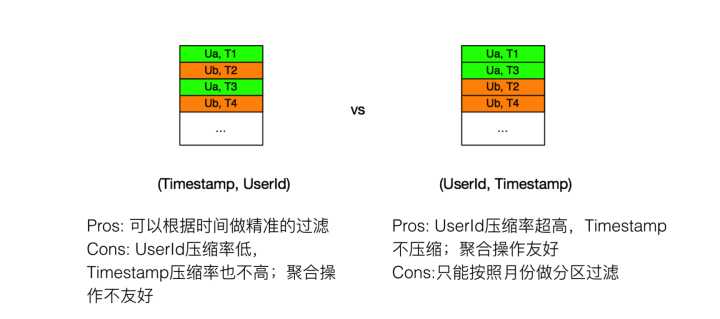
ClickHouse中primary key代表了数据的组织排序方式
左边的以(timestamp,uid)为主键,时间是有序的,方便做时间精准过滤,但uid压缩率低;右边的以(uid,timestamp) 为主键,uid压缩率高,方便做uid group, 但对时间过滤支持不够好。
通过测试对比,我们发现以 (uid,timestamp) 作为主键性能略快,查询时间达到了 1.4s。
6. 分组预排序
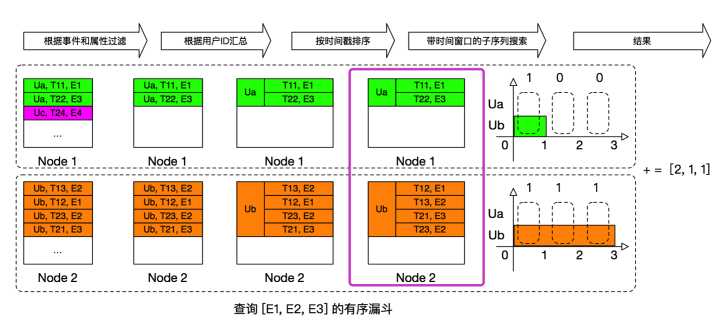
当我们以 (uid,timestamp) 作为primary key后, 分组内的数据其实已经有序了, 我们可以去掉代码中的sort方法,来提高性能,经过这个优化,查询时间达到了 0.9s。
7. 带时间窗口的子序列搜索优化
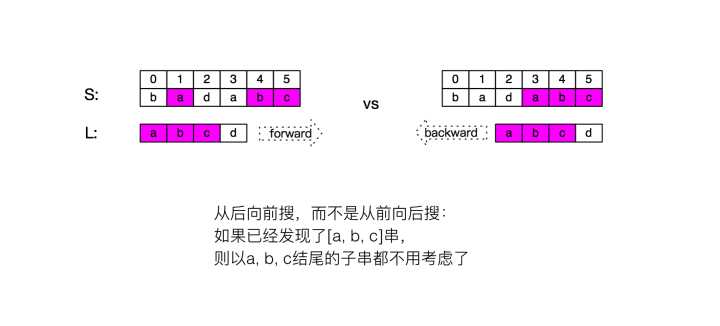
这里主要是用了一些 剪枝的策略,当我们从左往右去搜索 a,b,c,d 漏斗的时候,我们需要找到最大的深度,必须一直去搜索以a开头的子序列;但我们从右往左搜索时, 我们只要考虑比当前结尾更大的子串即可, 比如我们找到了 a,b,c, 后面我们只需要考虑以d结尾的串,这样减小了搜索的复杂度,查询时间达到了0.8s。
8. 数据结构优化
事件ID到数组下标Index的映射,我们直接遍历了数组搜索,而不使用std::unordered_map, 因为在events数据量不大的情况下, 数组搜索O(1)比O(n)慢。
使用纯C++数组存储事件序列,不使用std::vector,去掉了vector的开销,灵活控制内存分配。
经此优化,查询时间达到了0.6s。
9. 部分压缩
数据库通常会对字段进行压缩,这样做节省了硬盘空间,但却浪费了cpu计算,为了提供性能,我们对字段进行了部分压缩,经此优化,查询时间达到了最终的0.5s。
uid => 压缩
timestamp => 不压缩
event_id => 不压缩
event_name => 压缩
event_tag => 压缩
date => 不压缩
总结:
我们已经将代码和PPT开源:
https://github.com/analysys/olap
0.5s当然不会是极限,当我们在这条路上渐行渐远的时候,我们发现做数据库的研究其实是一件非常有意思的事情,我们来自广州向量线科技,一家专注下一代分析技术的初创公司,期待各路人才的加入,欢迎私信勾搭。