jpa总结:https://segmentfault.com/a/1190000015047290
- ,使用了动态代理,我们的repositoryDao继承了simpleJapRepository implements jpaRepository,使用方法的同时,不用重写abstract method
- spring Data 两种polymorphism, 一种是静态多态spring data规制方法和注解,一种是创建自定义的语句
- 两个概念,placeholder和动态添加语句
- 拼接可以用string,也可以用criterialBuiler,最后createQuery
1, entity manager实现(动态)
2,沒有重载版本,jpaRepository自带可以,用crud不可以,
jpaRepository extend pagingAndSortingRepository, so that It have the findAll method with sort or pageable as peremeter
加了pageable能return一个page, 只带了sort只返回list
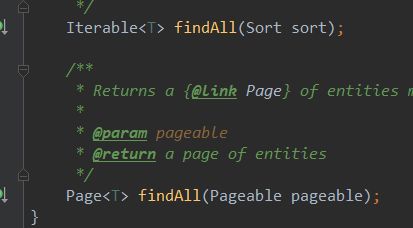
默认sort method, parameter is null mean unsorted, default_direction = direction.asc
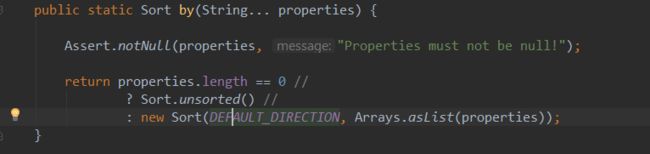
多个排序条件,还有其他方式
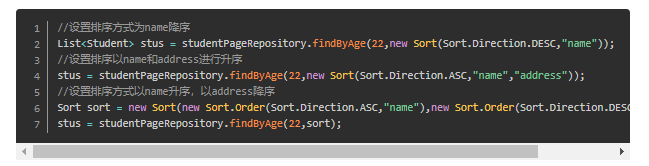
3,jpaRepository的find规制,需要再dao显示重载
start with findBy,可以随意添加分页, 沒有is,一开始的by就是is

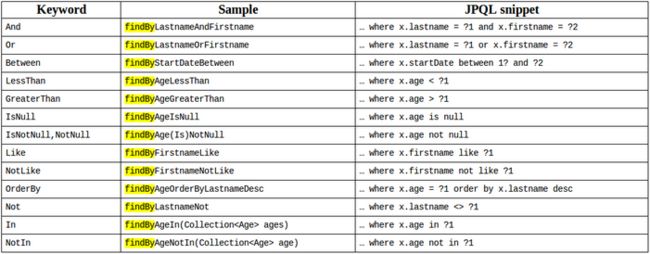
4,@select注解, 需要再dao重载


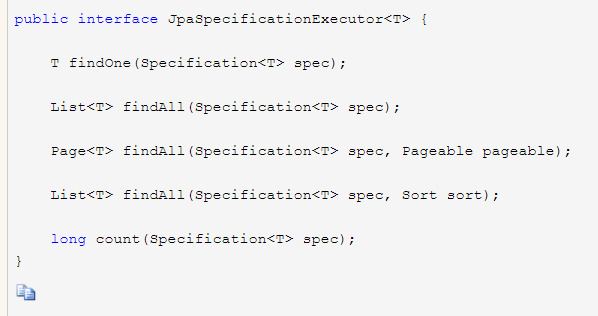
5,JapSpecification实现(动态)(扩充findAll)
一目了然:https://www.jianshu.com/p/659e9715d01d
有时候需要动态拼接语句,比如多条件查询中,要根据有无这个条件才添加 (mybatis可以用xml标签完成
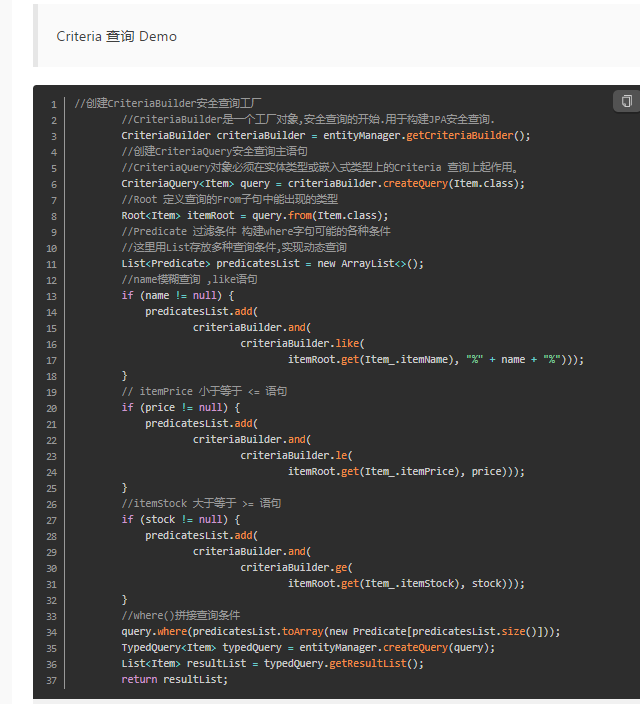
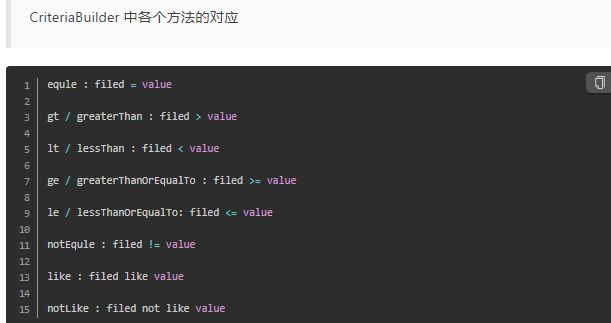
前面使用 equal 直接使用path对象(属性),进行比较即可
但是 gt,lt,ge,le,like 不能直接使用path对象,要根据path对象指定比较的参数类型:path.as(类型的字节码对象),
root.get("title").as(String.class) ,获得一个属性,要specify class,= root.
![]()
![]()
![]()
在雨燕中,有两种,一种是另一种的封装
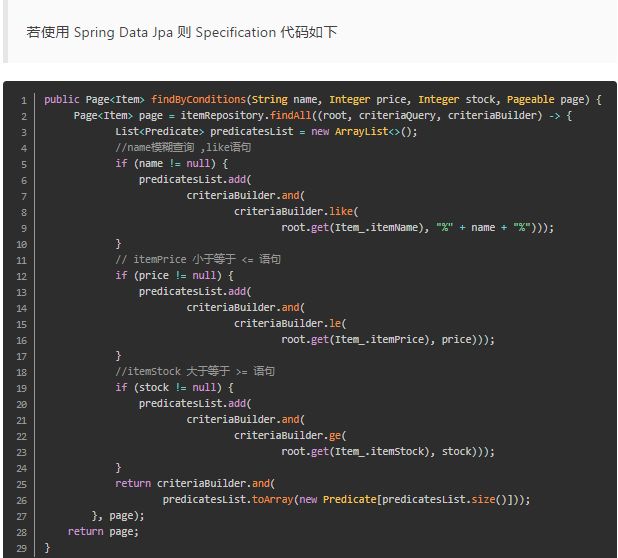
对比:都有需要列名,值,条件
然后和别的condition and or or在一起
最后添加order by,group by, asc这些

沒有用spring data下的原始方法,事实上,springdata就帮你干了这些
in条件

![]()
join (注意:不添加条件也是关联查询,强调一个条件
one to one
先获得主表的root的join,在通过这个join去增加条件
![]()
one to many
也一样的
![]()
分组查询
4步曲替换(由于返回类型是tuple,所以只能自己写
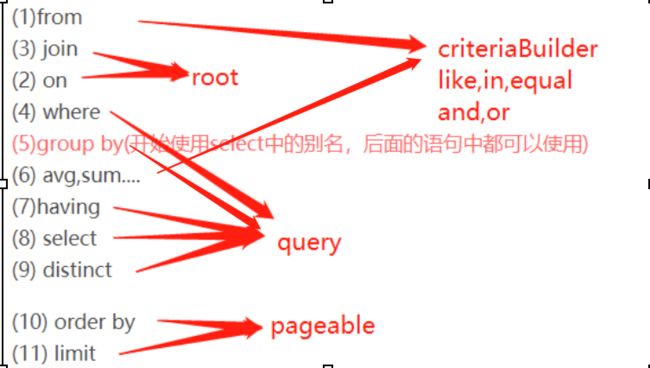
获得CriteriaBuilder:entityManager.getCriteriaBuilder
获得query:criteriaBuilder.createQuery -> createTupleQuery( is same as
![]()
获得from:set root Object: Root root = query.from(u.class)
添加predicate: criteriaBuilder.add predicate -> add group by
添加select:root或者select 一些root getpath
entityManager 添加 query: TypedQuery
初步估计 Criteria.tuple和Multiselect是一样的
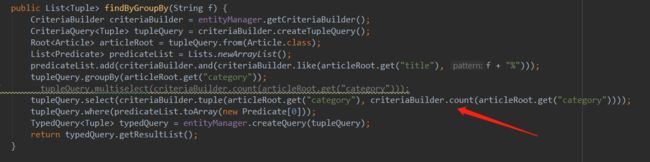
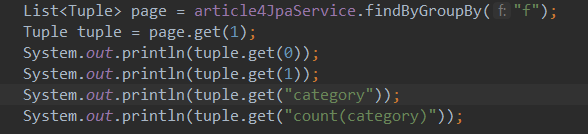
root -> from -> path -> expression -> selection -> tupleElement
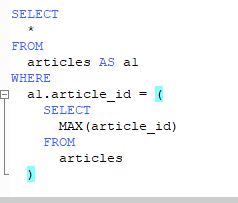
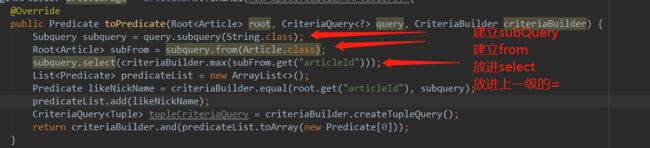
子查询和自连接
自连接onetoone自己(其他不加
选出最大的(还有一些in的情况![]()