线程安全:
指的是多个线程共享资源内存时, 需要考虑并发问题.包括:
1.原子变量CAS算法
核心是Unsafe类
CAS (Compare-And-Swap)
是一种硬件对并发的支持,针对多处理器操作而设计的处理器中的一种特殊指令,
用于管理对共享数据的并发访问。
CAS 是一种无锁的非阻塞算法的实现。
CAS 包含了 3 个操作数:
需要读写的内存值 V
进行比较的值 A
拟写入的新值 B
当且仅当 V 的值等于 A 时, CAS 通过原子方式用新值 B 来更新 V 的值,否则不会执行任何操作
1.1java.util.concurrent.atomic包
线程安全的整/浮点/布尔型:
AtomicInteger
AtomicBoolean
AtomicLong
AtomicIntegerArray
AtomicIntegerFieldUpdater
AtomicLongArray
AtomicLongFieldUpdater
AtomicMarkableReference
AtomicReference
AtomicReferenceArray
AtomicReferenceFieldUpdater
AtomicStampedReference
DoubleAccumulator
DoubleAdder
LongAccumulator
LongAdder(可替换AtomicLong)
Striped64
#主要分为四类:
>> 基本类型:
AtomicBoolean,AtomicInteger,AtomicLong
>> 数组类型:
AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
>> 引用类型:
AtomicReference,AtomicStampedRerence,AtomicMarkableReference
>> 对象属性修改类型:
AtomicIntegerFieldUpdater,AtomicLongFieldUpdater,AtomicLongFieldUpdater
1.2 AtomicInteger
package com.zy.juc;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicInteger;
/*
* 一、i++ 的原子性问题:i++ 的操作实际上分为三个步骤“读-改-写”
* int i = 10;
* i = i++; //10
*
* int temp = i;
* i = i + 1;
* i = temp;
*
* 二、原子变量:在 java.util.concurrent.atomic 包下提供了一些原子变量。
* 1. volatile 保证内存可见性
* 2. CAS(Compare-And-Swap) 算法保证数据变量的原子性
* CAS 算法是硬件对于并发操作的支持
* CAS 包含了三个操作数:
* ①内存值 V
* ②预估值 A
* ③更新值 B
* 当且仅当 V == A 时, V = B; 否则,不会执行任何操作。
*/
public class TestAtomicInteger {
public static void main(String[] args) {
ThreadDemo01 threadDemo01 = new ThreadDemo01();
for(int i = 0; i < 10; i ++){
new Thread(threadDemo01).start();
}
}
}
@Slf4j
class ThreadDemo01 implements Runnable{
private AtomicInteger i = new AtomicInteger();
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
log.error("==========");
}
System.out.println(">>>>>>>>i=" + getI() + "<<<<<<<<<");
}
public int getI(){
return i.getAndIncrement();
}
}

AtomicInteger-getAndIncrement.png
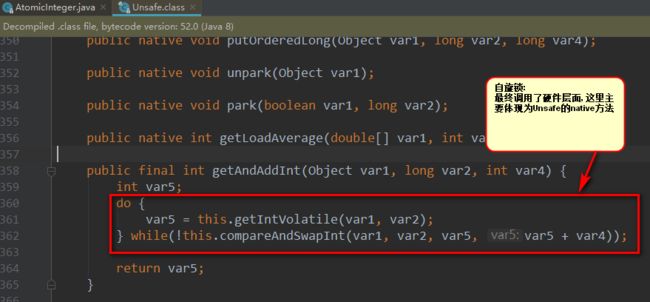
Unsafe-->getAndAddInt.png
Unsafe中对CAS的实现是C++写的
Linux的X86下主要是通过cmpxchgl这个指令在CPU级完成CAS操作的,
但在多处理器情况下必须使用lock指令加锁来完成。
不同处理器的方式实现不同。
CAS的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。
UnSafe 类的 objectFieldOffset() 方法是一个本地方法,
这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。
另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
1.3模拟CAS
package com.zy.juc;
/**
* 模拟CAS算法
* 实际的CAS是通过操作硬件来实现
*/
public class TestCompareAndSwap {
public static void main(String[] args) {
CompareAndSwap cas = new CompareAndSwap();
for(int i = 0; i < 10; i ++){
new Thread(() -> {
int expectedValue = cas.getValue();
boolean b = cas.compareAndSet(expectedValue, (int) (Math.random() * 100));
System.out.println(b);
}).start();
}
}
}
class CompareAndSwap {
private int value;
// 获取内存值
public synchronized int getValue(){
return value;
}
// 比较
public synchronized int compareAndSwap(int expectedValue, int newValue){
int oldValue = value;
if (oldValue == expectedValue){
this.value = newValue;
}
return oldValue;
}
// 设置
public synchronized boolean compareAndSet(int expectedValue, int newValue){
return expectedValue == compareAndSwap(expectedValue, newValue);
}
}
1.4CAS的缺点
#循环时间开销较大
public final int getAndUpdate(IntUnaryOperator updateFunction) {
int prev, next;
do {
prev = get();
next = updateFunction.applyAsInt(prev);
} while (!compareAndSet(prev, next));
return prev;
}
#只能保证一个共享变量的原子操作
#ABA问题
#1. 基本的ABA问题
在CAS算法中,需要取出内存中某时刻的数据(由用户完成), 在下一时刻比较并替换(由CPU完成,该操作是原子的)。
这个时间差中,会导致数据的变化。
假设如下事件序列:
>> 线程 1 从内存位置V中取出A。
>> 线程 2 从位置V中取出A。
>> 线程 2 进行了一些操作,将B写入位置V。
>> 线程 2 将A再次写入位置V。
>> 线程 1 进行CAS操作,发现位置V中仍然是A,操作成功。
尽管线程 1 的CAS操作成功,但不代表这个过程没有问题——对于线程 1 ,线程 2 的修改已经丢失。
--------- 例如:
如果位置V存储的是链表的头结点,那么发生ABA问题的链表中,原头结点是node1,
线程 2 操作头结点变化了两次,很可能是先修改头结点为node2,再将node1插入表头成为新的头结点。
对于线程 1 ,头结点仍旧为 node1,CAS操作成功,但头结点之后的子链表的状态已不可预知。
#2. 与内存模型相关的ABA问题
在没有垃圾回收机制的内存模型中(如C++),程序员可随意释放内存。
假设如下事件序列:
>> 线程 1 从内存位置V中取出A,A指向内存位置W。
>> 线程 2 从位置V中取出A。
>> 线程 2 进行了一些操作,释放了A指向的内存。
>> 线程 2 重新申请内存,并恰好申请了内存位置W,将位置W存入C的内容。
>> 线程 2 将内存位置W写入位置V。
>> 线程 1 进行CAS操作,发现位置V中仍然是A指向的即内存位置W,操作成功
这里比问题更严重,实际内容已经被修改了,但线程 1 无法感知到线程 2 的修改。
更甚,如果线程 2 只释放了A指向的内存,而线程 1 在 CAS之前还要访问A中的内容,那么线程 1 将访问到一个野指针。
private static AtomicInteger aba = new AtomicInteger(10);
private static AtomicReference aba2 = new AtomicReference<>(23);
public static void main(String[] args) {
new Thread(() -> {
aba.compareAndSet(10, 11);
aba.compareAndSet(11, 10);
aba2.compareAndSet(23, 24);
aba2.compareAndSet(24, 23);
}, "t1").start();
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ">>>>>" + aba.compareAndSet(10, 11111) + "------" + aba.get());
System.out.println(Thread.currentThread().getName() + ">>>>>" + aba2.compareAndSet(23, 22223333) + "------" + aba2.get());
}, "t2").start();
}
# 打印信息如下:
# t2>>>>>true------11111
# t2>>>>>true------22223333
ABA问题的解决方案
#1.基本的ABA问题:
加入版本号即可解决。
#1.1 AtomicStampedReference
除了对象值,AtomicStampedReference内部还维护了一个“状态戳”。
状态戳可类比为时间戳,是一个整数值,每一次修改对象值的同时,也要修改状态戳,从而区分相同对象值的不同状态。
当AtomicStampedReference设置对象值时,对象值以及状态戳都必须满足期望值,写入才会成功。
AtomicStampedReference的几个API在AtomicReference的基础上新增了有关时间戳的信息:
//比较设置 参数依次为:期望值 写入新值 期望时间戳 新时间戳
public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp)
//获得当前对象引用
public V getReference()
//获得当前时间戳
public int getStamp()
//设置当前对象引用和时间戳
public void set(V newReference, int newStamp)
#1.2 AtomicMarkableReference
AtomicMarkableReference和AtomicStampedReference功能相似,
但AtomicMarkableReference描述更加简单的是与否的关系。
它的定义就是将状态戳简化为true|false。如下:
public final static AtomicMarkableReference ATOMIC_MARKABLE_REFERENCE = new AtomicMarkableReference<>("abc" , false);
#操作时:
ATOMIC_MARKABLE_REFERENCE.compareAndSet("abc", "abc2", false, true);
#2.与内存模型相关的ABA问题:
Java的垃圾回收机制已经帮我们解决了。
private static AtomicStampedReference aba_resolve = new AtomicStampedReference<>(33, 1);
public static void main(String[] args) {
new Thread(() -> {
int stamp = aba_resolve.getStamp();
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
aba_resolve.compareAndSet(33, 1912, stamp, stamp + 1);
System.out.println(Thread.currentThread().getName() + "线程------值是: " + aba_resolve.getReference() + "----version是:" + aba_resolve.getStamp());
}, "t2").start();
new Thread(() -> {
aba_resolve.compareAndSet(33, 34, aba_resolve.getStamp(), aba_resolve.getStamp() + 1);
aba_resolve.compareAndSet(34, 33, aba_resolve.getStamp(), aba_resolve.getStamp() + 1);
System.out.println(Thread.currentThread().getName() + "线程------值是: " + aba_resolve.getReference() + "----version是:" + aba_resolve.getStamp());
}, "t1").start();
}
# 打印结果如下:
# t1线程------值是: 33----version是:3
# t2线程------值是: 33----version是:3
#注:
根据实际情况,判断是否处理ABA问题。
如果ABA问题并不会影响我们的业务结果,可以选择性处理或不处理;
如果ABA会影响我们的业务结果的,这时就必须处理ABA问题了。
#追注:
对于AtomicInteger等,没有什么可修改的属性;
且我们只在意其结果值,所以对于这些类来说,
本身就算发生了ABA现象,也不会对原线程的结果造成什么影响。
2.并发容器类之线程不安全容器 & 解决方案
Java 5.0 在 java.util.concurrent 包中提供了多种并发容器类来改进同步容器的性能。
ConcurrentHashMap 同步容器类是Java 5 增加的一个线程安全的哈希表。
对于多线程的操作,介于 HashMap 与 HashTable 之间。
内部采用“锁分段”机制替代 HashTable 的独占锁, 进而提高性能。
HashTable锁住的是整个表,而ConcurrentHashMap采用分段加锁
Java8后,将锁分段机制,转换为了CAS算法!!!!!!!!!!!!!
此包还提供了设计用于多线程上下文中的 Collection 实现:
ConcurrentHashMap、
ConcurrentSkipListMap、
ConcurrentSkipListSet、
CopyOnWriteArrayList、
CopyOnWriteArraySet。
当期望许多线程访问一个给定 collection 时,
ConcurrentHashMap 通常优于同步的(即用synchronized修饰后的) HashMap,
ConcurrentSkipListMap 通常优于同步的 TreeMap。
当期望的读数和遍历远远大于列表的更新数时,
CopyOnWriteArrayList 优于同步的 ArrayList。
2.1ArrayList
# java.util.ConcurrentModificationException
public static void main(String[] args) {
List list = new ArrayList<>();
for (int i = 0; i < 30; i ++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0, 3));
System.out.println(list);
}).start();
}
}
#解决方案:
推荐: CopyOnWriteArrayList --> ReentrantLock可重入锁解决
不推荐: Vector, Collections.synchronizedList(new ArrayList<>()).
2.2HashSet(底层数据结构是HashMap)
# java.util.ConcurrentModificationException
public static void main(String[] args) {
Set set = new HashSet<>();
for (int i = 0; i < 30; i ++) {
new Thread(() -> {
set.add(UUID.randomUUID().toString().substring(0, 3));
System.out.println(set);
}).start();
}
}
#解决方案:
推荐: CopyOnWriteArraySet
不推荐: Collections.synchronizedSet(new HashSet<>())
2.3HashMap
# java.util.ConcurrentModificationException
public static void main(String[] args) {
Map map = new HashMap<>();
for (int i = 0; i < 30; i ++) {
new Thread(() -> {
map.put(Thread.currentThread().getName(), UUID.randomUUID().toString().substring(0, 2));
System.out.println(map);
}, String.valueOf(i)).start();
}
}
#解决方案:
推荐: ConcurrentHashMap
不推荐: HashTable, Collections.synchronizedMap(new HashMap<>());