在部署的方式的第一部分我们介绍了基础设施即代码的概念、原则和工具,那么现在我们就来看看应用部署的方式有哪些。
In Place Deployment(直接替换部署)
如果你的应用服务器数量很少,比如只有一台,那么最简单的方式就是通过在原来的服务器上直接更新应用。当然,最好是通过使用前面所介绍的基础设施即代码的工具来完成。
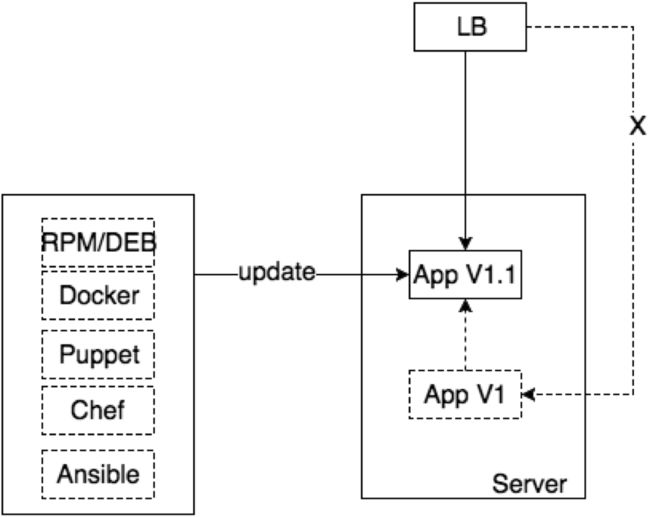
在部署的时候,最好提前自动将loadbalancer指向一个维护的页面,并且donwtime所有监控的服务,比如Nagios,Zabbix等,如果它们发出警报,那么on-call的人就不知道这是在部署还是生产环境真的出了问题。
- 如果部署成功,测试无误,再将loadbalancer指向应用服务器,undowntime监控服务
- 如果部署成功,测试出现问题,如果使用包管理工具进行部署,那么可以用这些工具来revert,比如
yum downgrade app,如果用了其它自动化配置管理工具比如ansible,那么好的实践是revert更新的那次配置的提交,重新运行自动化配置管理的流程(如持续交付/集成流水线),来回滚。不要在服务器上做任何的手动操作。回滚后将loadbalancer指向服务器,同时undowntime监控服务。 - 如果部署失败,同2,回滚配置,通过部署流水线来回滚应用版本,enable loadbalancer,同时undowntime监控服务。
这种方式不好的地方在于需要停止服务部署,不过看上去很多国内的互联网公司都还是在使用这种方式,从正在维护的页面(排除哔因素外),当然这只是不负责任的猜测。
Rolling Update Deployment(滚动更新部署)
当你的应用有多台服务器时,你可以考虑通过滚动更新的方式,也就是逐台或者批量(每几台服务器)更新的方式。比如像下面这样:
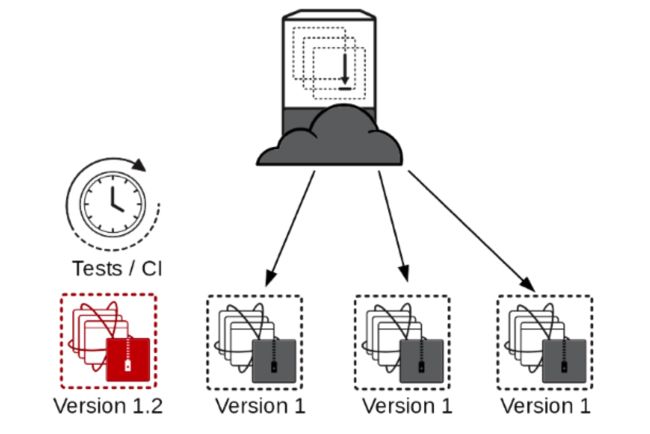
步骤如下:
- 自动化部署的工具通知loadbalancer让它disable其中一台或者几台服务器(得保证有足够数量的服务器在线并能满足当前的请求)
- 同样,downtime监控服务,通过自动化配置工具等更新服务,部署成功,测试完成后,loadbalancer enable已更新的服务器,undowntime监控服务
- 重复2的步骤,直至所有服务器都更新完成
- 如果全部更新完成才发现问题,取决于问题的严重程度,很严重可以将loadbalancer指向维护页面,然后revert自动化配置工具的修改,同时更新全部服务器,如果不是很严重但是需要回退版本,可以revert配置,然后以滚动更新的方式再部署一遍
- 如果在部署的过程中某台服务器失败,根据具体的原因,采取修复或者回退的策略
这种方式的好处就是可以保证服务一直在线(0 downtime),但是不好的地方在于,线上同时存在了两个不同的版本,同时,因为是对已存在的服务器的更新,所以出现第一部分所提到的服务器侵蚀时,很容易导致部署的失败。
Immutable Deployment(不可变部署)
即便是在没有人工干预的情况下,服务器也会因为如日志写满磁盘却没有定期rotate导致服务器部署出错,这样的服务器我们可以成为可变基础设施(Mutable infrastructure),也就是说这个服务器本身是会变化或者被修改的。怎么理解这个问题呢,我们以Scala来举例。Scala中有通过val定义的不可变变量,也有通过var定义的可变变量。当你创建一个val变量时,你没有办法对它做任何修改,如果想更改它的值只能通过新建另一个val变量,但是在用var声明的时候,它的值就是可变的,你完全无法预期它会被赋上什么值。当然,我们通过代码在命令行里面去修改,这个变化可见、可控,但是应用在服务器上运行,它变化成什么无法预测的,你怎么知道它不会从国际主义者变成狭隘的民族主义者。
scala> val immutable = 2
immutable: Int = 2
scala> immutable =3
:8: error: reassignment to val
immutable =3
^
scala> var mutable = 3
mutable: Int = 3
scala> mutable = 4
mutable: Int = 4
所以最好的办法就是每次部署都从头开始,重新创建服务器,安装新版本的服务以及应用对应的新配置。测试完成后,如果没有问题,将loadbalancer指向新的服务器集群,同时干掉旧的服务器集群。
支持这样的部署方式,需要你的虚拟化解决方案(通过命令行或者API的方式)的支持。以我们的基础设施为例,在自建的数据中心中采用了VMware的虚拟化解决方案,支持通过API的方式动态创建、销毁服务器,Loadbalancer使用NetScaler,也提供了SOAP API去动态更改配置,同理,监控使用Nagios也支持。那么很容易就可以实现一个这样的自动化部署工具,每次在部署时重新生成服务器,安装部署应用,然后干掉旧的服务器。好的云平台,比如AWS,它提供的Cloudformation工具,内建了这种不可变部署的功能,使用起来更加的简单。
从不可变的部署,我们可以引出另一个概念,不可变基础设施(immutable infrastructure).不可变基础设施是一种在IT资源上管理服务和软件部署的方法,其中组件被替换而不是更改,每次的变更通过这种替换的方式有效地重新部署应用程序或服务。其主要目的是为了解决可变基础设施的下列问题:
- 当你的业务发展,或者是微服务拆分时导致服务、服务器数量增加时,基础设施的维护成本也倍增。
- 可变基础设施上部署更容易出错。如我们在第一部分所介绍的雪花服务器,配置漂移等都会导致未知的部署错误。
- 鉴别错误、分析威胁的成本很高。比如操作系统、基础软件经常会出现一些漏洞,需要给服务器打补丁,去查找那些服务器需要打补丁要耗费很多时间,虽然你可以安装类似Security Center这样的工具帮你分析大,但是这给带来了额外的成本开销。还有因为雪花服务器或者服务器侵蚀导致的问题,定位问题的时间开销也很大。
- 如果我们在云平台上也做类似的事情,如果服务器需要补丁,很有可能会被平台主动patch,重启服务。
而我们采用不可变基础设施,可以简化维护的过程,部署也会更加简单,成功率更高,如果你保持每天部署,很多威胁、补丁都在基础镜像中更新过了,也避免了分析威胁错误的成本。如果你采用了云计算平台或者你的基础设施支持这种方式,那么最好采用这种不可变部署方式去更新应用或者服务。
Red-Black Deployment(红黑部署)
这是Netflix采用的部署手段,Netflix的主要基础设施是在AWS上,所以它利用AWS的特性,在部署新的版本时,通过AutoScaling Group用包含新版本应用的AMI的LaunchConfiguration创建新的服务器。测试不同过,找到问题原因后,直接干掉新生成的服务器以及Autoscaling Group就可以,测试通过,则将ELB指向新的服务器集群,然后销毁掉旧的服务器集群以及AutoScaling Group。
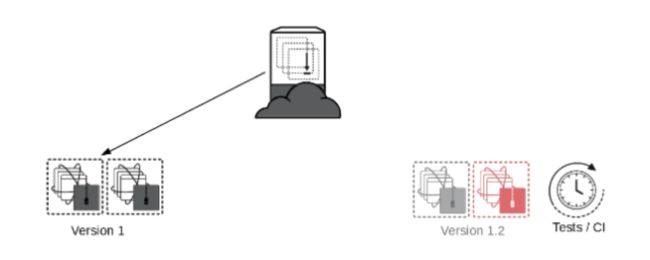
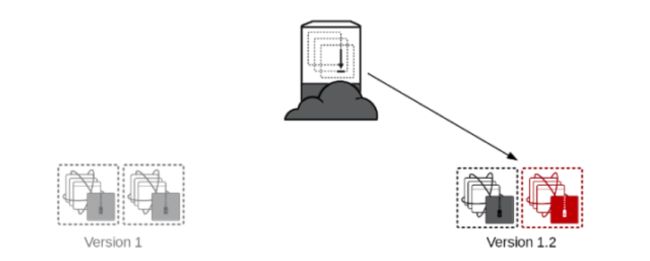
红黑部署的好处是服务始终在线,同时采用不可变部署的方式,也不像蓝绿部署一样得保持冗余的服务始终在线。
AWS的Cloudformation内建了对红黑部署的支持,比如我的这个例子里面的配置项:
autoScalingGroup:
CreationPolicy:
ResourceSignal:
Count: 1
Timeout: PT10M
AutoScalingCreationPolicy:
MinSuccessfulInstancesPercent: 100
UpdatePolicy:
AutoScalingScheduledAction:
IgnoreUnmodifiedGroupSizeProperties: false
AutoScalingReplacingUpdate:
WillReplace: true
这是我的应用的AutoScaling Group的配置项,其中AutoScalingReplacingUpdate的配置项中的WillReplace为true时,在LaunchConfiguration有任何变动时,比如我修改了user-data中运行容器的版本号,在我更新Cloudformation时,它会自动创建新的服务器,并且在服务器通过ELB的health-check后,将ELB指向新的服务器,然后干掉旧的服务器,如此则完成了一次0 downtime的不可变部署。
Blue-Green Deployment(蓝绿部署)
蓝绿部署是最常见的一种0 downtime部署的方式,原理上很简单,就是通过冗余来解决问题。通常在Loadbalancer上你需要两组配置,一组是active的生产环境的配置,一组是inactive的配置(也算是生产环境),用户来访问的时候,Loadbalancer只会让他访问active的服务器集群,但是inactive的环境是可访问的。这个时候如果你需要部署,只要针对inactive环境,更新所有的服务器即可,然后Loadbalancer切换下active或者inactive指向服务器集群即可。这种方式的好处在你可以始终很放心的去部署inactive环境,如果出错并不影响生产环境的服务,如果切换后出现问题,也可以在非常短的时间内把再做一次切换,就完成了回滚。而且同时在线的只有一个版本。这种方式不好的地方在于冗余产生的额外维护、配置的成本,以及服务器本身运行的开销。
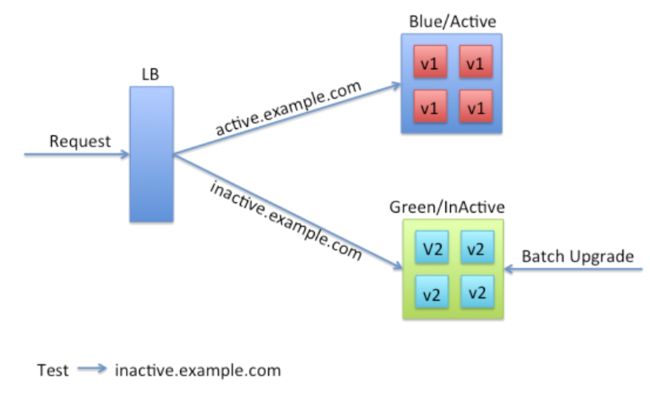
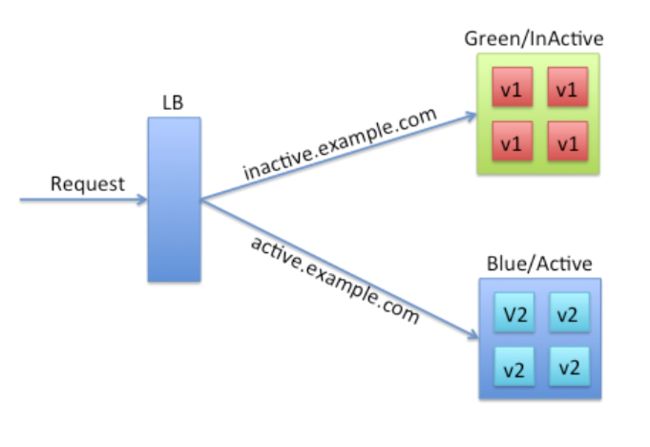
我们在自建的数据中心里面就采用蓝绿部署,同时是不可变的部署方式。因为失败的成本很低,所以当自动化流水线搭建起来时,任何人都可以去做部署。
我在这里用haproxy模拟了一个蓝绿部署的例子,有兴趣的可以看下。
Multi Region Deployment(多区域部署) or DR As Deployment(灾备即部署)
如果你的服务需要给不同的地区使用,为了提高使用体验,你的应用或者服务会部署到尽量靠近用户的位置,所以会出现数据中心处于不同的region(区域)的情况,比如大陆和北美。这种方式同时是一种灾备的考量,如果其中一个区域的数据中心停电,那么还有另外一个数据中心可以提供服务,保证业务的可用性。想要让多个区域的服务做到0 downtime部署,就得采取类似蓝绿部署的策略,但是不同的地方在于蓝绿部署是active-inactive模式,而多区域的部署是active-active模式。
我举一个我们做多区域部署的例子。我们主站的基础设施最前面是Akamai,它分别将60%和40%的流量loadbalancer到两个不同区域的数据中心,每个数据中心中最前面是NetScaler做Loadbalancer,将请求分发给25台主站的服务器。每台服务器上运行的Java应用都会运行newrelic的agent将服务的数据传给Newrelic服务器。Akamai通过心跳检测来确定数据中心是否在线。
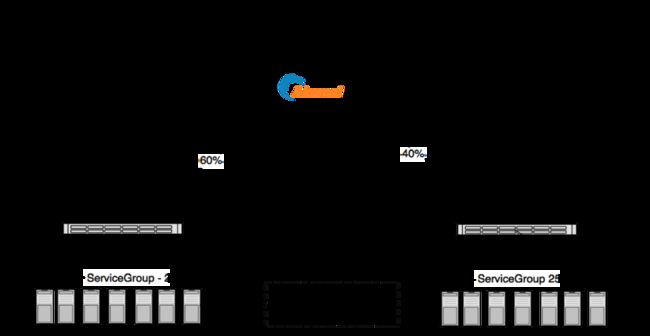
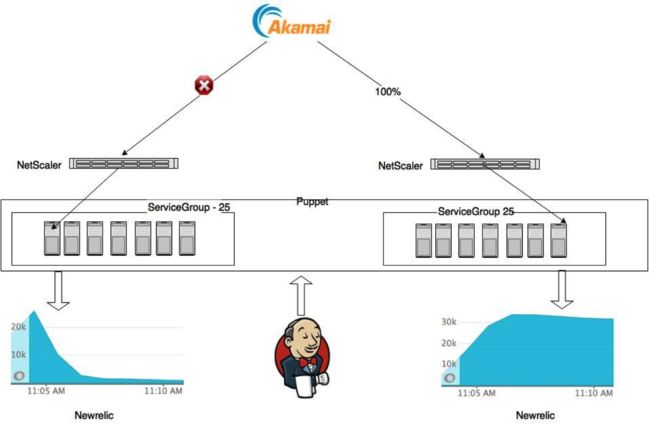
- 在开始部署的时候,首先通过自动化部署流水线,让NetScaler禁止Akamai访问其中一个数据中心A,那么Akamai就认为这个数据中心宕机了,然后会把100%流量都指向另一个数据中心B
- 自动化脚本会检查Newrelic中A数据中心的RPM(Request Per Minute),如果这个数值降到1000一下,那么我们可以认为几乎没有任何外部的服务访问这个数据中心,就可以放心的触发下一个build job去自动化部署数据中心B中所有应用,这里需要通过批量滚动部署的方式,以保证数据中心内部访问这个服务不出问题。
- 完成部署、测试后。再通过自动化脚本让Akamai心跳检测可以访问到A数据中心,然后不让它访问B数据中心。同理,等到数据中心B中服务的访问RPM降低到安全数值时,做相同的事情。
- B中所有服务更新测试完成后,通过自动化脚本让Akamai的心跳检测可以访问到两个数据中心,然后流量会自动的切换到60%/40%。
这样的部署相对比较安全,服务始终在线而且出错的回滚也比较容易。不太好的地方就是稍微有点耗时,如果对整个部署的过程做简单优化的话,部署的时间大概会在一个小时左右。所以部署的时间成本会比较高。
如果你使用云平台,比如AWS、Azure,可以通过它们的DNS服务来做到相同的事情,比如你可以告诉AWS的R53,让它主动的将服务failover到其中一个region。
我所知道的自动化部署的方式大概就是这些,下一节我会分享使用基于12factors原则针对docker部署的经验。
Reference
- 不可变基础设施
- Red Black Deployment
- Blue Green Deployment