从本文开始,我们进入Spark中的调度部分,首先本文将对TaskScheduler和SchedulerBackend的实现原理进行分析。
我们从SparkContext中的源码开始:
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
追踪到SparkContext的createTaskScheduler方法:
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
createTaskScheduler方法中根据master的值进行模式匹配,这里我们以Standalone为例,即匹配到的结果是:SPARK_REGEX(sparkUrl):
case SPARK_REGEX(sparkUrl) =>
// 实例化TaskSchedulerImpl
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
// 实例化SparkDeploySchedulerBackend(Standalone模式)
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
// 执行TaskSchedulerImpl的初始化操作
scheduler.initialize(backend)
(backend, scheduler)
TaskScheduler是Spark中的底层调度器,目前只被TaskSchedulerImpl具体实现。TaskScheduler会获得DAGScheduler提交过来的对应Stage的tasks的集合,并负责将这些tasks发送给集群中运行(如果task运行失败会进行一定次数的重试,也会对慢任务进行处理),并向DAGSchuduler汇报。
TaskScheduler的具体实现TaskSchedulerImpl会通过SchedulerBackend根据不同的集群模式对tasks进行调度,而SchedulerBackend会根据集群部署模式的不同而有不同的实现,如下图所示(注:下图列出的都是生产环境下(Production)的实现,诸如FakeSchedulerBackend并没有列出):
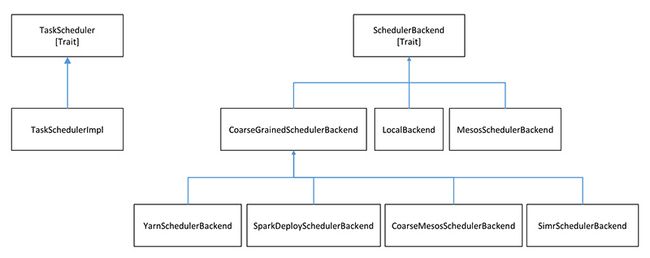
本文中我们以Standalone模式为例进行说明,即SchedulerBackend的具体实现为SparkDeploySchedulerBackend,因为继承自CoarseGrainedSchedulerBackend,所以其资源分配的方式是粗粒度的。
大家可能已经看出,其实SparkContext、TaskSchedulerImpl、SchedulerBackend这三者的配合使用的就是设计模式中的策略模式(关于策略模式的解释可以参考网络上的资源),从上面的代码中可以看出,SparkContext中具体实例化TaskScheduler的时候首先进行了模式匹配(根据master),即匹配到底使用哪种策略,匹配到相应的策略后(此处以Standalone模式为例,即匹配到的是SPARK_REGEX)就会调用TaskSchedulerImpl的initialize()方法来设置具体的策略(TaskSchedulerImpl拥有抽象策略类的实例),设置完成后,在SparkContext中会调用TaskSchedulerImpl的start()方法来执行具体的功能,所以我们可以看到后面SparkContext中执行start()方法,实际上就是执行了具体策略即SparkDeploySchedulerBackend的start()方法,如下面源码所示:
_taskScheduler.start() //SparkContext中调用TaskSchedulerImpl的start()方法
override def start() { //TaskSchedulerImpl的start()方法
backend.start() //实际上是调用具体策略(SparkDeploySchedulerBackend)的start()方法
我们再用一张图总结一下:

经过以上的分析,我们已经大致了解了程序的执行流程,所以下面对涉及到的源码进行具体分析:
TaskSchedulerImpl的initial方法:
def initialize(backend: SchedulerBackend) {
// 这里就是上图中的步骤4
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
// 调度模式,默认是FIFO,即先进先出,会用专门的文章进行说明
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools()
}
根据上面TaskSchedulerImpl源码中的start方法已经看到实际上是调用的backend的start方法,所以下面分析SparkDeploySchedulerBackend中的start方法:
override def start() {
// 首先调用父类也就是CoarseGrainedSchedulerBackend的start方法,最重要的就是创建并注册DriverEndpoint
super.start()
launcherBackend.connect()
// 获取Driver的Endpoint的地址,可以看到这里我们使用了上一篇文章中我们获得的driver的host和port
// The endpoint for executors to talk to us
val driverUrl = rpcEnv.uriOf(SparkEnv.driverActorSystemName,
RpcAddress(sc.conf.get("spark.driver.host"), sc.conf.get("spark.driver.port").toInt),
CoarseGrainedSchedulerBackend.ENDPOINT_NAME)
// 下面都是CoarseGrainedExecutorBackend运行时需要的一些参数
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
// 构建运行CoarseGrainedExecutorBackend的命令
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
// 应用程序的UI地址
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
// 为每个Executor分配的cores的个数
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
// 封装成ApplicationDescription
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory,
command, appUIAddress, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor)
// 下面就是App注册和启动Executor的部分了,我会在下一篇文章中进行详细分析
client = new AppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
CoarseGrainedSchedulerBackend中的start方法:
override def start() {
val properties = new ArrayBuffer[(String, String)]
for ((key, value) <- scheduler.sc.conf.getAll) {
if (key.startsWith("spark.")) {
properties += ((key, value))
}
}
// TODO (prashant) send conf instead of properties
driverEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint(properties))
}
从上面的源码可以看出,我们即将进入App注册和启动Executor的部分,这一部分会放在下一片文章中进行详细阐述,本文主要聚焦的是TaskScheduler和SchedulerBackend的部分。
本文参照的是Spark 1.6.3版本的源码,同时给出Spark 2.1.0版本的连接:
Spark 1.6.3 源码
Spark 2.1.0 源码
本文为原创,欢迎转载,转载请注明出处、作者,谢谢!