首先来一个最传统的网络, 最简单的练习, 预测一个两段的函数:
X> 0.5 ? X * 0.8 - 0.5 : -X * 0.6 + 0.2
import tensorflow as tf
import numpy as np
X = np.linspace(0, 0.99, 100).reshape(100, 1).astype(np.float32)
y = np.where(X> 0.5, X * 0.8 - 0.5, -X * 0.6 + 0.2)
plt.plot(y)
plt.show()
输出
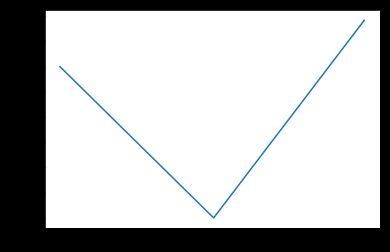
image.png
定义构成网络的一些通用的函数:
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def variable_summaries(var):
pass
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
with tf.name_scope(layer_name):
# This Variable will hold the state of the weights for the layer
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('pre_activations', preactivate)
if act == None:
activations = preactivate
else:
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
return activations
定义网络:
x = tf.placeholder(dtype=tf.float32, shape=[None, 1], name="input")
label = tf.placeholder(tf.float32, [None, 1], name="label")
x_l2 = tf.nn.l2_normalize(x, dim=0)
hidden = None
hidden1 = hidden = nn_layer(x_l2, 1, 10, "layer1")
# hidden2 = nn_layer(hidden1, 10, 20, "layer2")
output = nn_layer(hidden, 10, 1, "layer2", act=None)
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.square(output-label))
optimizer = tf.train.AdamOptimizer(learning_rate=0.05)
train = optimizer.minimize(loss)
# print(day.shape, label.shape)
tf.summary.scalar("loss", loss)
merged = tf.summary.merge_all()
训练网络,注意这个地方, 最外面是多次训练网络, 其原因在于最开始写的代码会导致结果收敛于局部最优解:
predicts = []
for j in range(2):
with tf.Session() as sess:
train_writer = tf.summary.FileWriter('./summary/train_time1', sess.graph)
tf.global_variables_initializer().run()
for i in range(1000):
if i % 50 == 0:
_, summary, train_loss = sess.run([train, merged, loss], feed_dict={x: X, label: y})
train_writer.add_summary(summary, i)
print("step %d loss=%f"%(i, train_loss))
else :
_, summary = sess.run([train, merged], feed_dict={x: X, label: y})
train_writer.add_summary(summary, i)
_loss, predict = sess.run([loss, output], feed_dict={x:X, label: y})
print("try %d loss=%f"%(j, _loss))
predicts.append(predict)
如果结果正常收敛: 画出结果
predict = predicts[0]
plt.figure()
plt.plot(predict, 'b')
plt.plot(y, 'r')
plt.show()
plt.figure(1)
plt.plot((predict - y))
plt.show()
print("loss", np.square(predict - y).T)

image.png
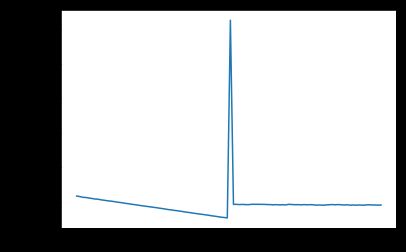
image.png
到现在为止, 小结一些遇到的问题:
- 最好按照一个通用俗称的代码习惯来命令一些入口, 和出口, 比如统一名称X, y, input, output, label什么的
- 这次是完全自己定义的结构和数据, 结果遇到一个问题, 出来的预测曲线始终是一条直线, 后来查了很久, 才发现是自己把自己坑了, 最后一个也使用了relu作为激活函数, 其直接结果就是relu只能输出正数或者0, 如何能输出负数部分的结果呢?
- 问题接踵而至, 预测结果总是还是输出一条直线, 只是偶尔会是正确的结果, 最开始把其倒数第二层的激活函数换成了tanh, 发现收敛速度大大变慢? 而且很大的几率出现直线的结果, 应该是陷入局部最优解, 或者参数都变成0, 无法继续学习了。后来找了一圈, 最后发现其实是网络太深了, 造成的, 试着把网络改成2层隐含层, 一层relu, 另外一层无激活函数, 结果ok, 而且训练速度大大加快。至于为什么, 我也是模模糊糊的感觉, 先不误导大家了, 自己思考下。
- 中间遇到过一个问题
merged = tf.summary.merge_all()这句代码, 在jupyter notebook里面第二次运行的时候, 会把以前的x也统计进来, 导致后面_, summary = sess.run([train, merged], feed_dict={x: X, label: y})这句的时候, 并没有输入原来的placeholder对应的值, 自然就会失败, 提示错误, 目前看来重启整个kernel是最简单的解决方法。- 那么留一个问题, 假设我的网络就是很深, 有没有好的办法避免出现局部最优解呢?
2017.11.24更新
batch norm
接着上面一个问题, 如何让网络比较深的时候, 也能成功收敛呢?
答案就是batch norm, 引入batch norm后, 哪怕网络再深一点, 也基本能成功收敛。
原理暂时不讲, 每个人都有自己的理解, 我的理解还很模糊。
直接上代码, 注意和前面的代码稍有不同的是, 我加了一些功能函数, 要模拟的数据变成了周期的数据, 也加入了噪音
import datetime
import time
import os
import shutil
def clear_summary():
for root, dirs, files in os.walk("./summary/"):
for d in dirs:
if d[:len('train_time')] == 'train_time':
shutil.rmtree(os.path.join(root, d))
def get_time():
ts = time.time()
return datetime.datetime.fromtimestamp(ts).strftime('%Y%m%d-%H:%M:%S')
import tensorflow as tf
import numpy as np
from tensorflow.contrib.rnn import BasicLSTMCell
from matplotlib import pyplot as plt
import pandas as pd
from sklearn import preprocessing
import tensorflow as tf
import numpy as np
X = np.linspace(0, 99, 100).reshape(100, 1).astype(np.float32)
X_week = X % 7
# print(X_week)
X = np.hstack([X, X_week])
print(X.shape)
X_raw = X
scalerX = preprocessing.StandardScaler()
X_ = scalerX.fit_transform(X)
week_rate = [1.1, 1.3, 1.2, 1.1, 1.2, 2.8, 1.9]
y = np.linspace(3, 6, 100).reshape(100, 1)
for i in range(0, 100):
y[i] = y[i] * week_rate[i%7]
noise = np.random.normal(0, 1, y.shape)
y = y + noise
# day = np.hstack([day, day_w])
scaler = preprocessing.StandardScaler()
y_raw = y
y = scaler.fit_transform(y)
plt.figure()
plt.plot(y_raw)
plt.plot(y)
plt.show()
X = X_
# print(X[:20])
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def variable_summaries(var):
pass
def nn_layer(input_tensor, input_dim, output_dim, layer_name, norm=True, act=tf.nn.relu):
with tf.name_scope(layer_name):
# This Variable will hold the state of the weights for the layer
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
if norm != None:
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
else:
biases = 0
with tf.name_scope('Wx_plus_b'):
wx_b = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('wx_b', wx_b)
if norm:
with tf.name_scope("norm"):
fc_mean, fc_var = tf.nn.moments(wx_b,axes=[0])
ema = tf.train.ExponentialMovingAverage(decay=0.5) # exponential moving average 的 decay 度
def mean_var_with_update():
ema_apply_op = ema.apply([fc_mean, fc_var]) #TODO : what's this???
with tf.control_dependencies([ema_apply_op]):
return tf.identity(fc_mean), tf.identity(fc_var)
mean, var = mean_var_with_update() # 根据新的 batch 数据, 记录并稍微修改之前的 mean/var
epsilon = 0.001
scale = tf.Variable(tf.ones([1]), name="norm_scale")
shift = tf.Variable(tf.zeros([1]), name="norm_shift")
# 将修改后的 mean / var 放入下面的公式
preactivate = tf.nn.batch_normalization(wx_b, mean, var, shift, scale, epsilon)
else:
preactivate = wx_b
if act == None:
activations = preactivate
else:
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
return activations
def add_fc():
pass # 获得链式的写法
_layer_number = 0
def make_name():
global _layer_number
try :
return "layer%d"%_layer_number
finally:
_layer_number += 1
x = tf.placeholder(dtype=tf.float32, shape=[None, 2], name="input")
label = tf.placeholder(tf.float32, [None, 1], name="label")
hidden = None
hidden = nn_layer(x, 2, 10, make_name())
hidden = nn_layer(hidden, 10, 20, make_name())
hidden = nn_layer(hidden, 20, 10, make_name())
output = nn_layer(hidden, 10, 1, make_name(), act=None)
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.square(output-label))
optimizer = tf.train.AdamOptimizer(learning_rate=0.05)
train = optimizer.minimize(loss)
# print(day.shape, label.shape)
tf.summary.scalar("loss", loss)
merged = tf.summary.merge_all()
predicts = []
clear_summary()
for j in range(1):
with tf.Session() as sess:
train_writer = tf.summary.FileWriter('./summary/train_time' + get_time(), sess.graph)
tf.global_variables_initializer().run()
for i in range(1000):
if i % 50 == 0:
_, summary, train_loss = sess.run([train, merged, loss], feed_dict={x: X, label: y})
train_writer.add_summary(summary, i)
print("step %d loss=%f"%(i, train_loss))
else :
_, summary = sess.run([train, merged], feed_dict={x: X, label: y})
train_writer.add_summary(summary, i)
_loss, predict = sess.run([loss, output], feed_dict={x:X, label: y})
print("try %d loss=%f"%(j, _loss))
predicts.append(predict)
print(X_raw[:, 0].shape, y_raw.shape)
for i in range(len(predicts)):
plt.plot(scaler.inverse_transform(predicts[i]), 'b')
# plt.scatter(X_raw[:, 0].reshape(100, 1), y_raw, c='r')
plt.plot(y_raw, c='r')
plt.show()
# plt.figure()
# plt.plot(scaler.inverse_transform(predicts[1]), 'b')
# # plt.plot(predicts[0], 'b')
# plt.plot(y_raw, 'r')
# plt.show()
# print("loss", np.square(predict - y).T)
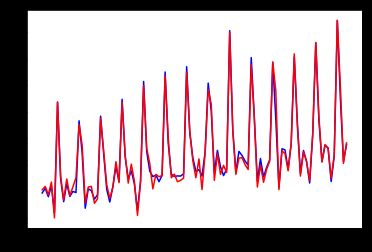
预测结果
遗留的问题:
- 如何不手动引入7的周期的情况下, 让网络自己学习到周期的问题呢?之前没有引入周期的时候, 网络只能学习到平均数, 不会学习到其中的周期变化。加深网络估计可以得到周期?只是我怀疑, 我加深网络的时候, 是否会过拟合?
- 没有分train&test
参考链接
原理解读:
深度学习(二十九)Batch Normalization 学习笔记
官网解读
batch_normalization
代码参考:
莫烦Python