论文地址:https://arxiv.org/abs/1612.01105
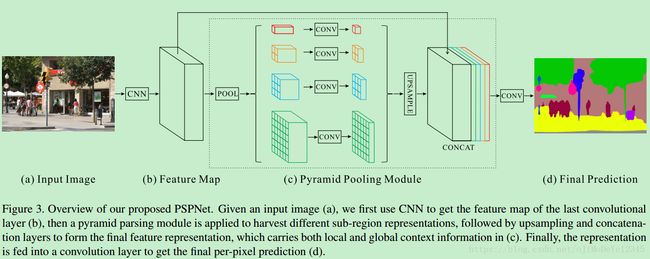
c图为论文核心结构
特征整合(Feature Ensembling)
又分为:
多尺度(multi-scale)
多级(multi-level)
个人感觉,multi-scale和multi-level是同时存在的。图像金字塔并不是多尺度特征表征的唯一方式,CNN计算的时候本身就存在多级特征图(feature map hierarchy),且不同层的特征图尺度就不同,形似金字塔结构
参考:https://blog.csdn.net/weixin_36060730/article/details/82798087
PSPnet 一句话总结
作者认为现有模型由于没有引入足够的上下文信息及不同感受野下的全局信息而存在分割出现错误的情景,于是,提出了使用global-scence-level的信息的pspnet,另外本文提出了引入辅助loss的ResNet优化方法。
参考:https://blog.csdn.net/fu6543210/article/details/80674444
采用 pyramid pooling module 对提取的 feature map 进行处理,以收集上下文信息得到的不同 levels 的 feature maps,再通过一个1x1卷积降维,将4个level的特征上采样到和原特征一样的尺度+原特征进行combine得到含有多尺度信息的feature map
PSP模块代码:https://github.com/warmspringwinds/pytorch-segmentation-detection/blob/master/pytorch_segmentation_detection/models/psp.py
class PSP_head(nn.Module):
def __init__(self, in_channels):
super(PSP_head, self).__init__()
out_channels = int( in_channels / 4 )
self.conv1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(True))
self.conv2 = nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(True))
self.conv3 = nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(True))
self.conv4 = nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(True))
self.fusion_bottleneck = nn.Sequential(nn.Conv2d(in_channels * 2, out_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(True),
nn.Dropout2d(0.1, False))
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
fcn_features_spatial_dim = x.size()[2:]
pooled_1 = nn.functional.adaptive_avg_pool2d(x, 1)
pooled_1 = self.conv1(pooled_1)
pooled_1 = nn.functional.upsample_bilinear(pooled_1, size=fcn_features_spatial_dim)
pooled_2 = nn.functional.adaptive_avg_pool2d(x, 2)
pooled_2 = self.conv2(pooled_2)
pooled_2 = nn.functional.upsample_bilinear(pooled_2, size=fcn_features_spatial_dim)
pooled_3 = nn.functional.adaptive_avg_pool2d(x, 3)
pooled_3 = self.conv3(pooled_3)
pooled_3 = nn.functional.upsample_bilinear(pooled_3, size=fcn_features_spatial_dim)
pooled_4 = nn.functional.adaptive_avg_pool2d(x, 6)
pooled_4 = self.conv4(pooled_4)
pooled_4 = nn.functional.upsample_bilinear(pooled_4, size=fcn_features_spatial_dim)
x = torch.cat([x, pooled_1, pooled_2, pooled_3, pooled_4],
dim=1)
x = self.fusion_bottleneck(x)
return x