针对数据分析师的薪资,我们用describe函数。

它能快速生成各类统计指标。数据分析师的薪资的平均数是17k,中位数是15k,两者相差不大,最大薪资在75k,应该是数据科学家或者数据分析总监档位的水平。标准差在8.99k,有一定的波动性,大部分分析师薪资在17+—9k之间。
用hist函数很方便的就绘制除出直方图,比excel快多了。图表列出了数据分析师薪资的分布,因为大部分薪资集中20k以下,为了更细的粒度。将直方图的宽距继续缩小。

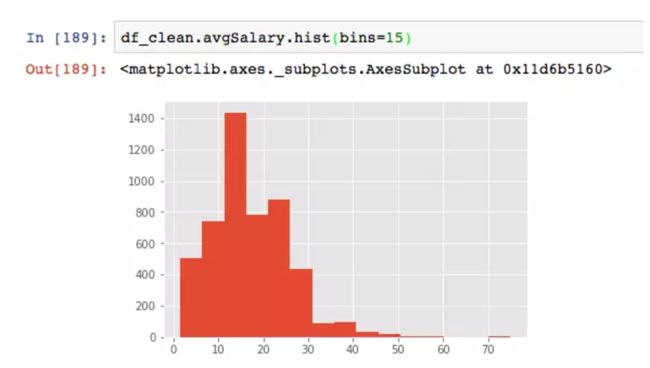
数据分布呈双峰状,因为原始数据来源于招聘网站的爬取,薪资很容易集中在某个区间,不是真实薪资的反应(10~20k的区间,以本文的计算公式,只会粗暴地落在15k,而非均匀分布)。
数据分析的一大思想是细分维度,现在观察不同城市、不同学历对薪资的影响。箱线图是最佳的观测方式。
图表的标签出了问题,出现了白框,主要是图表默认用英文字体,而这里的都是中文,导致了冲突。所以需要改用matplotlib。

到目前为止,我们了解了城市、年限和学历对薪资的影响,但这些都是单一的变量,现在想知道北京和上海这两座城市,学历对薪资的影响。

在by传递多个值,箱线图的刻度自动变成元组,也就达到了横向对比的作用(这方法其实并不好,以后会讲解其他方式)。这种方法并不适宜元素过多的场景。从图上可以看到,不同学历背景下,北京都是稍优于上海的,北京愿意花费更多薪资吸引数据分析师,而在博士这个档次,也是一个大幅度的跨越。我们不妨寻找其中的原因。
在pandas中,需要同时用到多个维度分析时,可以用groupby函数。它和SQL中的group by差不多,能将不同变量分组。

上图是标准的用法,按city列,针对不同城市进行了分组。不过它并没有返回分组后的结果,只返回了内存地址。这时它只是一个对象,没有进行任何的计算,现在调用groupby的count方法。

它返回的是不同城市的各列计数结果,因为没有NaN,每列结果都是相等的。现在它和value_counts等价。

换成mean,计算出了不同城市的平均薪资。因为mean方法只针对数值,而各列中只有avgSalary是数值,于是返回了这个唯一结果。

groupby可以传递一组列表,这时得到一组层次化的Series。按城市和学历分组计算了平均薪资。

后面再调用unstack方法,进行行列转置,这样看的就更清楚了。在不同城市中,博士学历最高的薪资在深圳,硕士学历最高的薪资在杭州。北京综合薪资最好。这个分析结论有没有问题呢?不妨先看招聘人数。
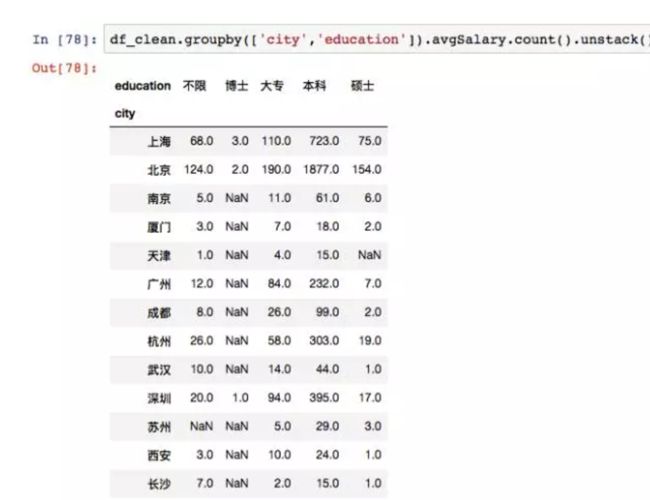
这次换成count,我们在groupby后面加一个avgSalary,说明只统计avgSalary的计数结果,不用混入相同数据。图上的结果很明确了,要求博士学历的岗位只有6个,所谓的平均薪资,也只取决于公司开出的价码,波动性很强,毕竟这只是招聘薪资,不代表真实的博士在职薪资。这也解释了上面几个图表的异常。
接下来计算不同公司招聘的数据分析师数量,并且计算平均数。
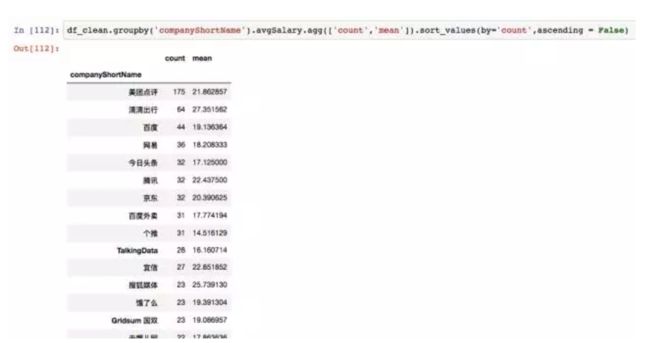
这里使用了agg函数,同时传入count和mean方法,然后返回了不同公司的计数和平均值两个结果。所以前文的mean,count,其实都省略了agg。agg除了系统自带的几个函数,它也支持自定义函数。

上图用lamba函数,返回了不同公司中最高薪资和最低薪资的差值。agg是一个很方便的函数,它能针对分组后的列数据进行丰富多彩的计算。但是在pandas的分组计算中,它也不是最灵活的函数。
现在我们有一个新的问题,我想计算出不同城市,招聘数据分析师需求前5的公司,应该如何处理?agg虽然能返回计数也能排序,但它返回的是所有结果,前五还需要手工计算。能不能直接返回前五结果?当然可以,这里再次请出apply。

可以看到,虽说是数据分析师,其实有不少的开发工程师,数据产品经理等。这是抓取下来数据的缺点,它反应的是不止是数据分析师,而是数据领域。不同城市的需求不一样,北京的数据产品经理看上去要比上海高。
agg和apply是不同的,虽然某些方法相近,比如求sum,count等,但是apply支持更细的粒度,它能按组进行复杂运算,将数据拆分合并,而agg则必须固定为列。
运用group by,我们已经能随意组合不同维度。接下来配合group by作图。
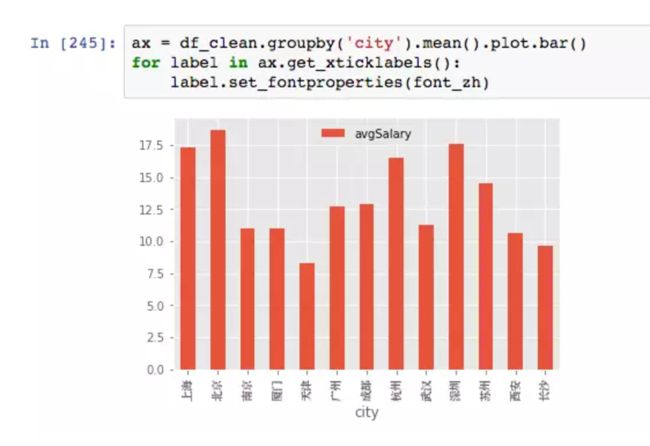
多重聚合在作图上面没有太大差异,行列数据转置不要混淆即可。

上述的图例我们都是用pandas封装过的方法作图,如果要进行更自由的可视化,直接调用matplotlib的函数会比较好,它和pandas及numpy是兼容的。plt已经在上文中调用并且命名
一种分析思路是对数据进行深加工。我们将薪资设立出不同的level

cut的作用是分桶,它也是数据分析常用的一种方法,将不同数据划分出不同等级,也就是将数值型数据加工成分类数据,在机器学习的特征工程中应用比较多。cut可以等距划分,传入一个数字就好。这里为了更好的区分,我传入了一组列表进行人工划分,加工成相应的标签。

cut的作用是分桶,它也是数据分析常用的一种方法,将不同数据划分出不同等级,也就是将数值型数据加工成分类数据,在机器学习的特征工程中应用比较多。cut可以等距划分,传入一个数字就好。这里为了更好的区分,我传入了一组列表进行人工划分,加工成相应的标签。

用lambda转换百分比,然后作堆积百分比柱形图(matplotlib好像没有直接调用的函数)。这里可以较为清晰的看到不同等级在不同地区的薪资占比。它比箱线图和直方图的好处在于,通过人工划分,具备业务含义。0~3是实习生的价位,3~6是刚毕业没有基础的新人,整理数据那种,6~10是有一定基础的,以此类推。
现在只剩下最后一列数据没有处理,标签数据。

现在的目的是统计数据分析师的标签。它只是看上去干净的数据,元素中的[]是无意义的,它是字符串的一部分,和数组没有关系。
你可能会想到用replace这类函数。但是它并不能直接使用。df_clean.positionLables.replace会报错,为什么呢?因为df_clean.positionLables是Series,并不能直接套用replace。apply是一个好方法,但是比较麻烦。
这里需要str方法。

str方法允许我们针对列中的元素,进行字符串相关的处理,这里的[1:-1]不再是DataFrame和Series的切片,而是对字符串截取,这里把[]都截取掉了。如果漏了str,就变成选取Series第二行至最后一行的数据,切记。

使用完str后,它返回的仍旧是Series,当我们想要再次用replace去除空格。还是需要添加str的。现在的数据已经干净不少。