Ajax = 异步JavaScript和XML标准通用标记语言
Ajax 是一种用于创建快速动态网页的技术。
Ajax是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。
对于使用Ajax返回的数据我们通常有两种方式采集数据
- 使用自动化测试工具chromedriver进行采集
-
通过抓包找到网页发送Ajax发送请求并返回的数据

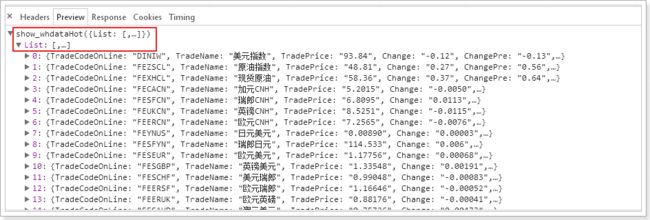 查看返回的数据格式,通过对数据处理采集我们想要的数据
查看返回的数据格式,通过对数据处理采集我们想要的数据
目标网址:全球视野的中文财经网站fx168
目标数据:采集美元指数、上证指数、深证成指、恒生指数、现货黄金、布兰特原油、标普500、离岸汇率的每日价格及涨跌幅
- 使用自动化测试工具来抓取数据信息
import requests
import pymongo
import datetime
from lxml import etree
from selenium import webdriver
from common.pgutils import get_conn
sql_truncate = "truncate TABLE public.news_morning_code"
sql = "insert into public.news_morning_code(TradeName,TradePrice,ChangePre,create_time) values(%s,%s,%s,%s)"
def insert_data(conn, name, present_price, rise_fall):
current_date = datetime.datetime.now()
present_price = float(present_price)
rise_fall = float(rise_fall.split('(')[1][:-2])
with conn.cursor() as cur:
sql_params = [name, present_price, rise_fall, current_date]
cur.execute(sql, sql_params)
def get_usdcny(conn):
"""离岸汇率"""
# client = pymongo.MongoClient('localhost', 27017)
# news = client['news']
# cj_zs = news['cj_zs']
chromedriver = r"/usr/local/share/chromedriver"
driver = webdriver.Chrome(chromedriver)
driver.get('http://quote.fx168.com/USDCNY/')
result = driver.page_source
xml = etree.HTML(result)
datas = xml.xpath(".//div[@class='yjl_fx168_Hangqing_dataDel_zuo']")[0]
name = datas.xpath('./h2/span/text()')[0]
present_price = xml.xpath('//*[@id="hangh3"]/span')[0].xpath('string(.)') # 现价
rise_fall = datas.xpath("./h3/b/text()")[0] # 当日涨跌
print(name, present_price, rise_fall)
insert_data(conn, name, present_price, rise_fall)
# data = {
# 'name': name,
# 'present_price': present_price,
# 'rise_fall': rise_fall,
# }
# cj_zs.insert_one(data)
driver.close()
driver.quit()
print('在岸汇率存储成功')
def get_shcomp(conn):
"""上证综指"""
chromedriver = r"/usr/local/share/chromedriver"
driver = webdriver.Chrome(chromedriver)
driver.get('http://quote.fx168.com/SHCOMP/')
result = driver.page_source
xml = etree.HTML(result)
datas = xml.xpath(".//div[@class='yjl_fx168_Hangqing_dataDel_zuo']")[0]
name = datas.xpath('./h2/span/text()')[0]
present_price = xml.xpath('//*[@id="hangh3"]/span')[0].xpath('string(.)') # 现价
rise_fall = datas.xpath("./h3/b/text()")[0] # 当日涨跌
print(name, present_price, rise_fall)
insert_data(conn, name, present_price, rise_fall)
driver.close()
driver.quit()
print('上证综指存储成功')
def get_szcomp(conn):
"""深圳成指"""
chromedriver = r"/usr/local/share/chromedriver"
driver = webdriver.Chrome(chromedriver)
driver.get('http://quote.fx168.com/SZCOMP/')
result = driver.page_source
xml = etree.HTML(result)
datas = xml.xpath(".//div[@class='yjl_fx168_Hangqing_dataDel_zuo']")[0]
name = datas.xpath('./h2/span/text()')[0]
present_price = xml.xpath('//*[@id="hangh3"]/span')[0].xpath('string(.)') # 现价
rise_fall = datas.xpath("./h3/b/text()")[0] # 当日涨跌
print(name, present_price, rise_fall)
insert_data(conn, name, present_price, rise_fall)
driver.close()
driver.quit()
print('深圳成指存储成功')
def get_hsi(conn):
"""恒生指数"""
chromedriver = r"/usr/local/share/chromedriver"
driver = webdriver.Chrome(chromedriver)
driver.get('http://quote.fx168.com/HSI/')
result = driver.page_source
xml = etree.HTML(result)
datas = xml.xpath(".//div[@class='yjl_fx168_Hangqing_dataDel_zuo']")[0]
name = datas.xpath('./h2/span/text()')[0]
present_price = xml.xpath('//*[@id="hangh3"]/span')[0].xpath('string(.)') # 现价
rise_fall = datas.xpath("./h3/b/text()")[0] # 当日涨跌
print(name, present_price, rise_fall)
insert_data(conn, name, present_price, rise_fall)
driver.close()
driver.quit()
print('恒生指数存储成功')
def get_dini(conn):
"""美元指数"""
chromedriver = r"/usr/local/share/chromedriver"
driver = webdriver.Chrome(chromedriver)
driver.get('http://quote.fx168.com/DINI/')
result = driver.page_source
xml = etree.HTML(result)
datas = xml.xpath(".//div[@class='yjl_fx168_Hangqing_dataDel_zuo']")[0]
name = datas.xpath('./h2/span/text()')[0]
present_price = xml.xpath('//*[@id="hangh3"]/span')[0].xpath('string(.)') # 现价
rise_fall = datas.xpath("./h3/b/text()")[0] # 当日涨跌
print(name, present_price, rise_fall)
insert_data(conn, name, present_price, rise_fall)
driver.close()
driver.quit()
print('美元指数存储成功')
def get_xau(conn):
"""现货黄金"""
chromedriver = r"/usr/local/share/chromedriver"
driver = webdriver.Chrome(chromedriver)
driver.get('http://quote.fx168.com/XAU/')
result = driver.page_source
xml = etree.HTML(result)
datas = xml.xpath(".//div[@class='yjl_fx168_Hangqing_dataDel_zuo']")[0]
name = datas.xpath('./h2/span/text()')[0]
present_price = xml.xpath('//*[@id="hangh3"]/span')[0].xpath('string(.)') # 现价
rise_fall = datas.xpath("./h3/b/text()")[0] # 当日涨跌
print(name, present_price, rise_fall)
insert_data(conn, name, present_price, rise_fall)
driver.close()
driver.quit()
print('现货黄金存储成功')
def get_spciw(conn):
"""标普500"""
chromedriver = r"/usr/local/share/chromedriver"
driver = webdriver.Chrome(chromedriver)
driver.get('http://quote.fx168.com/SPCIW/')
result = driver.page_source
xml = etree.HTML(result)
datas = xml.xpath(".//div[@class='yjl_fx168_Hangqing_dataDel_zuo']")[0]
present_price = xml.xpath('/html/body/section[1]/div/div/div[2]/div[1]/div/div[1]/h3/span')[0].xpath('string(.)') # 现价
rise_fall = datas.xpath("./h3/b/text()")[0] # 当日涨跌
print('标普500', present_price, rise_fall)
name = '标普500'
insert_data(conn, name, present_price, rise_fall)
driver.close()
driver.quit()
print('标普500存储成功')
def get_brents(conn):
"""布兰特油"""
chromedriver = r"/usr/local/share/chromedriver"
driver = webdriver.Chrome(chromedriver)
driver.get('http://quote.fx168.com/BRENTS/')
result = driver.page_source
xml = etree.HTML(result)
datas = xml.xpath(".//div[@class='yjl_fx168_Hangqing_dataDel_zuo']")[0]
name = datas.xpath('./h2/span/text()')[0]
present_price = xml.xpath('//*[@id="hangh3"]/span')[0].xpath('string(.)') # 现价
rise_fall = datas.xpath("./h3/b/text()")[0] # 当日涨跌
print(name, present_price, rise_fall)
insert_data(conn, name, present_price, rise_fall)
driver.close()
driver.quit()
print('布兰特油存储成功')
def main():
conn = get_conn()
try:
with conn:
with conn.cursor() as cur:
cur.execute(sql_truncate)
get_usdcny(conn)
get_shcomp(conn)
get_szcomp(conn)
get_hsi(conn)
get_dini(conn)
get_xau(conn)
get_spciw(conn)
get_brents(conn)
finally:
if conn:
conn.close()
if __name__ == '__main__':
main()
- 分析网页结构及数据返回的方法,采集数据
#!/usr/bin/env python3.4
# encoding: utf-8
"""
Created on 17-12-12
@author: Xu
"""
import json
import requests
import time
import datetime
from common.pgutils import get_conn
def get_json():
url = 'http://fx168api.fx168.com/InterfaceCollect/Default.aspx?Code=fx168&bCode=IQuoteDataALL&succ_callback=show_whdata&_=1512984141823'
my_headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
'Host': 'fx168api.fx168.com',
'Referer': 'http://quote.fx168.com/BRENTS/',
}
current_time = int(time.time())
current_date = datetime.datetime.now()
datas = {
'Code': 'fx168',
'bCode':'IQuoteDataALL',
'succ_callback': 'show_whdata',
'_': current_time
}
cont = requests.get(url=url, headers=my_headers, data=datas)
cont.encoding = 'utf-8'
result = cont.text
content = result[12:-1]
info = json.loads(content)['List']
# print(info)
sql_truncate = "truncate TABLE public.news_morning_code"
sql = "insert into public.news_morning_code(TradeName,TradePrice,ChangePre,create_time) values(%s,%s,%s,%s)"
# 0:美元指数 30:上证指数 74:深证成指 76:恒生指数 19:现货黄金 73:布兰特原油 29:标普500 45:离岸汇率
code_list = [0, 30, 74, 76, 19, 73, 29, 45]
conn = get_conn()
try:
with conn:
with conn.cursor() as cur:
cur.execute(sql_truncate)
for i in code_list:
sql_params = [info[i]['TradeName'], info[i]['TradePrice'], info[i]['ChangePre'], current_date]
# print(sql_params)
cur.execute(sql, sql_params)
finally:
if conn:
conn.close()
if __name__ == '__main__':
get_json()
- 连接postgresql数据库,保存数据
#!/usr/bin/env python3.4
# encoding: utf-8
"""
Created on 17-12-12
@author: Xu
"""
import psycopg2
def get_conn():
database = '数据库名'
user = '用户名'
password = '密码'
host = 'ip地址'
port = '5432'
return psycopg2.connect(database=database, user=user, password=password, host=host, port=port)
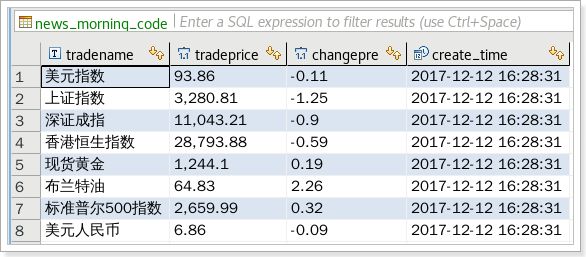
数据展示
这两种方式从效率上来讲显然第二种更快捷,两者的差别是第一种需要解析html的结构取得数据,而第二种可以直接对返回的数据进行处理进而保存我们想要的数据。