
说下 TreeSet 和 HashSet 什么区别呢?

它们的区别点主要在他们的底层数据结构不同,HashSet 使用的是 HashMap 来实现,而 TreeSet 使用的是 TreeMap 来实现的。
哦?那你了解 HashMap 和 TreeMap 的区别吗?
HashMap 是一个最常用的数据结构,它主要用于我们有通过固定值(key)获取内容的场景,时间复杂度可以最快优化到 O(1) 哈,当然效果不好的时候时间复杂度是 O(logN) 或者O(n)。虽然固定值查找提高了速度,但是 HashMap 不能保证固定值,也就是 key 的顺序,所以这个时候 TreeMap 就出现了,虽然它的查找、删除、更新的时间复杂度都是 O(logN),但是他可以保证 key 的有序性。
恩恩,掌握的还不错,那你和我说一下 HashMap 和 TreeMap 的底层实现有什么不同,才导致的他们有这么大的差异?
这个原因主要是它们底层用的实现不同,HashMap 使用的是数组(桶)和哈希的方式实现,巧妙通过 key 的哈希路由到每一个数组用于存放内容,这时候通过 key 获取 value 的时间复杂度就是 O(1),当然因为 key 的哈希可能碰撞,所以就需要针对碰撞的时候做处理,HashMap 里面每一个数组(桶)里面存的其实是一个链表,key 的哈希冲突以后会追加到链表上面,这时候再通过 key 获取 value 的时候时间复杂度就变成了 O(n),那么数据碰撞越来越多的时候岂不是查询很慢?最后呢为了优化这个时间复杂度,HashMap 当一个 key 碰撞次数超过 TREEIFY THRESHOLD 的时候就会把链表转换成红黑树,这样虽然插入的时候也增加了时间复杂度,但是对于频繁哈希碰撞的问题的查询效率有很大的提高,使得查询的时间复杂度变成了 O(logN)。
哈,说到红黑树就把 HashMap 和 TreeMap 联系到了一起,因为 TreeMap 的底层实现就是红黑树。
恩恩,既然你说到了红黑树,那么我想问下为什么采用的是红黑树,而不是二叉树搜索树呢?
恩,通常情况当我们听到二叉搜索树的时候以为它是平衡树,其实不是。它只是左子树的值小于根节点,右子树的值大于根节点,如果构建根节点以后插入的数据是有序的,那么构造出来的二叉搜索树就不是平衡树,而是一个链表,那么它的时间复杂度就是 O(n),如下图。然而红黑树呢?就是通过每个节点标色的方式,每次更新数据以后再进行平衡,以此来保证其查找效率。
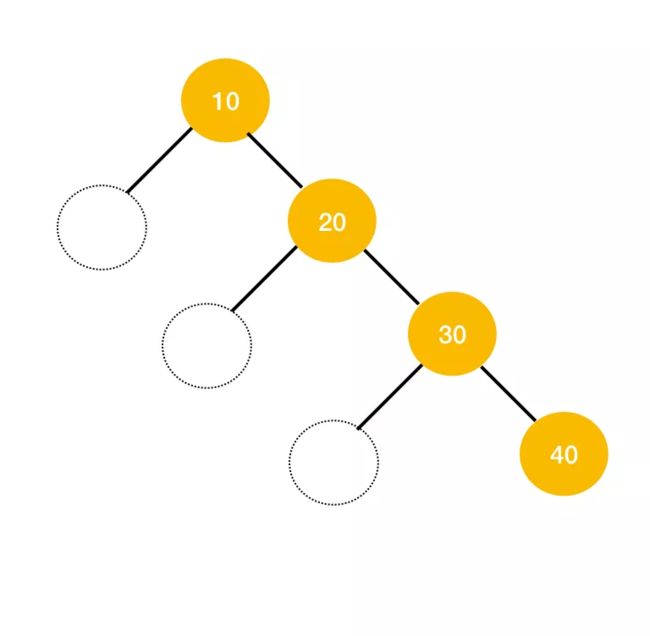
恩好的,那既然你说到了这里,那么你再展开说明一下它是怎么做到的每次插入都平衡。
恩,红黑树因为它每个节点都有黑色或者红色两种颜色,当然它也有一些特性,比如
1、根节点是黑色的
2、红色节点的子节点必须是黑色并且父节点也是黑色,
3、任何一条路径的黑色节点个数相同。
它通过这些特性再重新插入的时候做着色处理,配合左旋,右旋来达到最终的平衡。所以可以理解黑色红色其实是为了更好的辅助平衡。当有了这个着色以后配合红黑树的性质,就可以定义出来一个平衡的公式如下,首先插入的元素必须是红色,因为黑色破坏他的性质的几率更大。
假定 X 是新插入的节点,P是父节点,Y是叔父节点,G是祖父节点,P 为 G 的左孩子
当 Y 为红色 -> P、Y 变黑,G 变红,X 变 G
当 Y 为黑色,X 是右孩子 -> 左旋 P,X 变 P
当 Y 为黑色,X 为左孩子 -> G 变红,P变黑,右旋 G
当 P 为 G 的右孩子的时候,直接做镜像操作即可。
https://mmbiz.qpic.cn/mmbiz_gif/zoa6DXqcuUib4mphsLL0YC5FKje7VMbbuQD2jAKl6k1tRgiaiaDDWMQO9qWqcib4TfNwc4m8tAasHh7U1yHomLWj2A/640?wx_fmt=gif&tp=webp&wxfrom=5&wx_lazy=1
当然这样还是非常的晦涩,如果还是没直观,可以直接看一下下面的视频讲解版本。
https://www.bilibili.com/video/av23890827
提到了 Hash,那么如果我想自定义一个 Class 作为 key,那么应该注意什么呢?
我觉得应该是注意重写 hashCode 和 equals 方法。以 put 方法为例,因为在 HashMap 内部 hash 的时候需要用到 hashCode,以此来判断两个 Class 实例的 hash 是否一致。equals 是用来在 hash 碰撞以后追加链表的时候比对看是否相同以便更新。
恩,那既然你提到了 hash 用到了 hashCode 方法,你来解释一下 HashMap 里面的 hash 具体怎么实现的呢?
好的,这个我还专门研究过,打开 HashMap源码,从 put 说起吧。它最先调用的是 hash 函数,然后和当前的 n - 1 做与运算得到 bucket 的下标,关键代码如下:
(h = key.hashCode()) ^ (h >>> 16) // 338 行
tab[i = (n - 1) & hash] // 692 行具体逻辑,先是获取 key 的 hashCode,然后把 hashCode 低位位移 16 位后和之前的 hashCode 做亦或运算得到最终的 hash 值, bucket 数量是有限的,所以需要和 n -1 与运算得到最终的下标
这么说可能比较晦涩,我简单画一个图吧。以 key 是 “我是key” 为例,n 默认为 16,下图是把十进制转换为二进制进行计算。
String value = "我是key";
int hashCode = value.hashCode(); //817810155
int lowBit = hashCode >>> 16; //12478
int hash = hashCode ^ lowBit; //817822293
int index = (n - 1) & hash; //5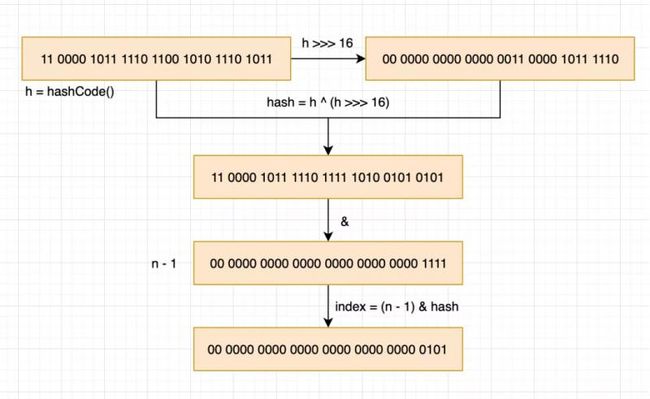
如图,可以清楚的了解到 hash 的全过程,最后一步 (n -1) & hash 很好理解,就是为了把计算好的 hash 映射到所有的 bucket 槽位。那么 h ^ (h >>> 16) 是因为通常情况 bucket 的槽位很少,用于参与运算的只有 hashCode 低位,为了让高位也可以参与运算,尽可能的在不影响性能的情况下避免冲突,所以做了一下高位右移 16 位然后亦或运算。
接下来的流程就相对比较好理解了,获取到 index 以后没有碰撞直接放入 bucket,如果碰撞了就追加到链表尾部,JDK8以前是头部,JDK8是为了计算步长等于 8 的时候转换为红黑树,所以每次都是遍历链表插入到尾部。说到红黑树上次已经回答你 漫画:HashSet 和 TreeSet 的实现与原理,最后如果 size 超过了 factor * capacity 就会 resize()。
那顺便和我说说你理解的 resize 吧?
resize 就是自动扩容,当 size 达到阈值以后会扩容到原来的 2 倍,关键代码 newCap = oldCap << 1。但是这里有一个非常巧妙的解决方法,因为扩容是扩充的 2 倍,n-1 转换为二进制也就是高位变成了1,那么根据(n - 1) & hash 计算,如果 hash 高位是 1 那么新的 index 位置就是 oldIndex + 16,如果hash 的高位 是 0 ,那么 index 的位置就是原来的 oldIndex 的位置,这样直接判断高位就可以了,省去了重新计算hash。
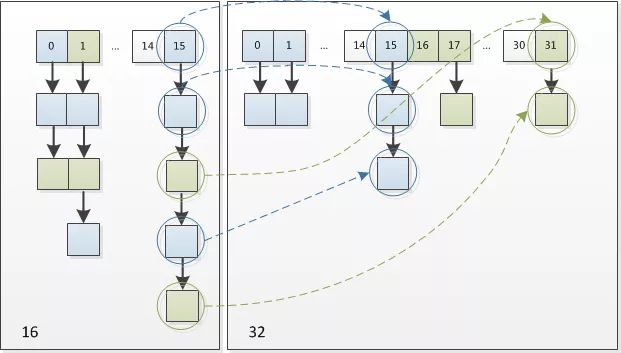
通过 HashMap 源码我们也可以清楚的看到,714-743 行:
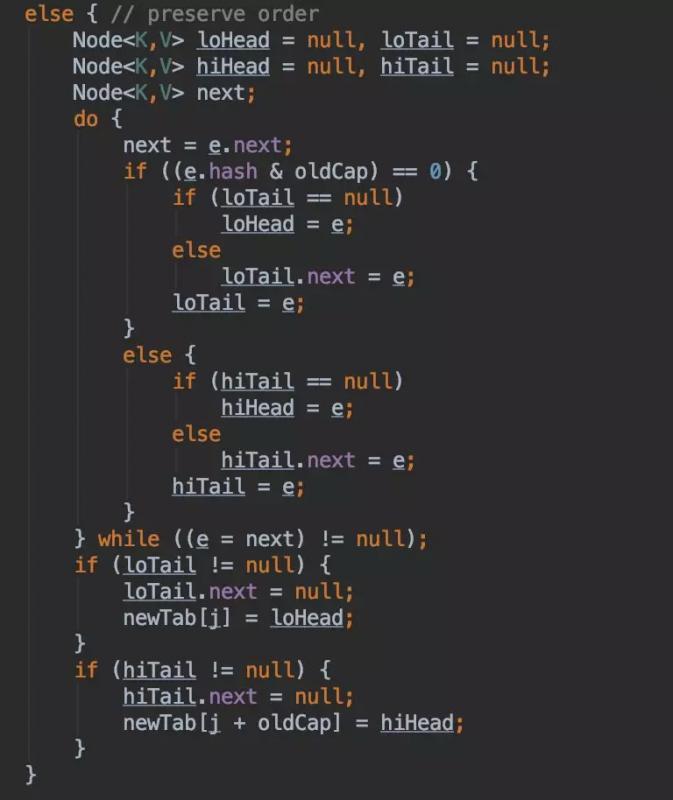
关于HashMap扩容为什么总是2的次幂推荐阅读:https://blog.csdn.net/u010841296/article/details/82832166
恩恩,掌握的还不错嘛,对了,说了这么多 HashMap 终究不是线程安全的,那么怎么样把它变成线程安全的你知道吗?
有一个工具方法,java.util.Collections#synchronizedMap(Map
但是最好的还是使用ConcurrentHashMap
参考:
https://mp.weixin.qq.com/s/VKSMDFCA2RbCDQECmcvE8A
https://mp.weixin.qq.com/s/yqCcugeqzxCQD107tfXt0w