1.Chris 的 T 恤尺寸(直觉)
在某些类型的机器学习算法中,特征缩放是特征预处理的一项重要步骤
特征缩放的作用
进行特征缩放的必要性
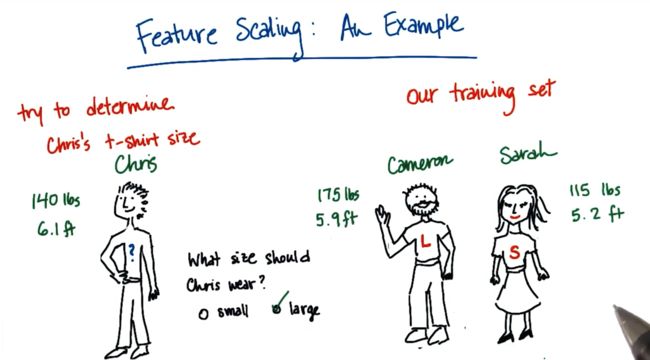
2. 由我们的度量确定的 Chris T恤尺寸
我们新建一个度量值“身高+体重”,根据这一度量更接近谁的数据来决定chris的衣服尺码
6. 利用不同的尺度来比较特征
“身高+体重”这一度量的两个特征“身高”和“体重”非常不平衡
身高范围:5~7
体重范围:115~175
因此如果计算两种特征的合计,那么就是体重几乎完全主导了答案,而身高成了舍入误差
我们可能希望在进行合计时,两个特征能够得到同等的重视,这时我们就需要特征缩放,这是一种重新缩放此类特征的一种方法,从而使特征跨越的范围有可比性,通常介于0~1
即体重和身高都用介于0~1的值进行表达,但不遗漏信息,这样再合计两个特征时,体重不再起着主导作用
7.特征缩放公式练习 1
特征缩放的一个优点是简单易懂

x`是要构建的新特征 要通过原始特征来决定新特征取什么值
x-min 是原始特征在被缩放前所取的最小值
x-max 是原始特征在被缩放前所取的最大值
x 需要缩放的特征的原始值
特征缩放公式的一个特点是:
缩放后的特征值在[0,1]之间,这是优点也是缺点
优点:
预估输出相对稳定
缺点:
如果输入特征中有异常数值,那么特征缩放会比较棘手,因为x-min和x-max可能是极端值
10. 最小值/最大值重缩放器编码练习
def featureScaling(arr):
new_features = []
max_value = max(arr)
min_value = min(arr)
for i in arr:
if max_value > min_value:
new_features.append(float(i-min_value)/float(max_value-min_value))
return new_features
data = [115, 140, 175]
print featureScaling(data)
11. sklearn 中的最小值/最大值缩放器
from sklearn.preprocessing import MinMaxScaler
import numpy as np
weights = np.array([[115.],[140.],[175.]])
scaler = MinMaxScaler()
rescaled_weights = scaler.fit_transform(weights) #fit 查找max min //transform 根据数据集中的所有元素应用公式
print rescaled_weights
MinMaxScaler
numpy array中的每个元素都会成为不同的训练点,训练点中的每个元素都会成为特征
列表中最小值经过重新缩放后的值为0
列表中最大值经过重新缩放后的值为1
12. 需要重缩放的算法练习
哪些机器学习算法会受到特征缩放的影响?
□× 决策树
□ √使用 RBF 核函数的 SVM
□ ×线性回归
□ √K-均值聚类
在支持向量机和k-mean cluster中,计算距离时,其实是在利用一个维度和另一个维度进行交换
以支持向量机为例,它有一条将距离最大化的线,而计算距离就是用一个维度和另一个维度进行交换
以k-mean cluster为例,我们有一个集群中心,要计算每个点到集群中心的距离
决策树不会呈现对角线,它会呈现出一系列水平线和垂直线,所以不存在交换,它只是在不同的方向上进行切割,在处理某一维度时,无需考虑另一维度
在线性回归中,每个特征都有一个系数,这个系数总是与相应的特征同时出现,特征a的变化不会影响特征b的系数
13. 特征缩放迷你项目简介
特征缩放改变聚类算法的输出
14. 特征缩放迷你项目
在上一个迷你项目中,你将安然人物的财务数据作为输入,对这些人物执行了 k-均值聚类。我们将更新那部分工作,以包含被缩放的特征,看看会有怎样的变化。
15缩放类型
回顾 [K-均值聚类迷你项目最后一部分]我们当时没有详细探讨缩放算法而部署了缩放,但是你现在更加了解具体的缩放算法了,并且可以分析出我们使用的是哪类缩放。
哪类缩放被部署了?
MinMaxScaler
16. 计算重缩放特征
对你在上一节课中的 k 均值聚类代码的“salary”和“exercised_stock_options”特征(仅这两项特征)运用特征缩放。 原始值为 20 万美元的“salary”特征和原始值为 1 百万美元的“exercised_stock_options”特征的重缩放值会是多少? (确保呈现浮点型而非整数型数字!)
开始练习
原值为 200,000 的“salary”特征在尺度变换后的值会是什么,以及原值为 100 万美元的“exercised_stock_options”特征在尺度变换后的值会是什么?
from sklearn.preprocessing import MinMaxScaler
import numpy as np
salary_array = np.array(salary_list)
scaler = MinMaxScaler()
rescaled_salary = scaler.fit_transform(salary_array)
print scaler.transform(200000) #0.18
salary_list = []
for i in data_dict:
salary = data_dict[i]['salary']
if salary !='NaN':
salary_list.append([salary])
stock_list = []
for i in data_dict:
stock = data_dict[i]['exercised_stock_options']
if stock !='NaN':
stock_list.append([stock])
stock_array = np.array(stock_list)
rescaled_stock = scaler.fit_transform(stock_array)
print scaler.transform(1000000) #0.03
17.何时部署特征缩放
有人可能会质疑是否必须重缩放财务数据,也许我们希望 10 万美元的工资和 4 千万美元的股票期权之间存在巨大差异。如果我们想基于“from_messages”(从一个特定的邮箱帐号发出的电子邮件数)和“salary”来进行集群化会怎样? 在这种情形下,特征缩放是不必要的,还是重要的?
如果你使用“from_messages”和“salary”作为聚类的特征,尺度将是不必要的还是重要的?
重要
Emails typically number in the hundreds or low thousands, salaries are usually at least 1000x higher.