在开发中,除了基本数据类型和String类型,还有集合类为我们带来了很大的便利,所以在这里梳理一下相关的内容。从字面就可以简单的理解集合类的作用,即数据集,或者说容器。能力有限,有误请指出。
Java为我们提供了丰富的集合类,常见的就有ArrayList、HashSet、HashMap、TreeMap等,如下所示即为简单的集合关系图:
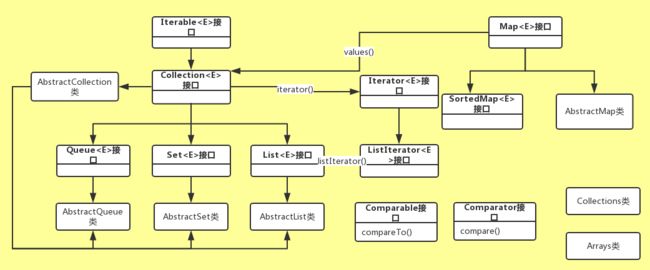
在上图中,个人认为可以为集合类部分分成5个大块,即以Collection为中心的集合块,Iterator为中心的迭代器,Map为中心的键值对,Comparable/Comparator比较工具,以处理集合类的Collections/Arrays的工具类。从简单的Iterator迭代器开始看。
Iterator接口
在我们的代码中经常可以看到迭代器,其本身只是一个接口,内部拥有三个方法next()、hasNext()与remove()来进行相应的操作,使用示例如下所示:
/**
**Iterator迭代器示例
**/
public static void main(String[] arg0){
LinkedList list = new LinkedList();
list.add("test1");
list.add("test2");
list.add("test3");
Iterator iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
iterator.remove();
}
}
输出:
test1
test2
test3
因为这个接口本身并没有实现类,所以可以通过Collection接口中的iterator()方法转化为迭代器,然后再调用相应方法。其中的remove()方法删除的是刚刚next()的对象,如果在调用next()方法之前使用remove()方法,则会报错IllegalStateException。
当然,在Iterator接口下,还存在ListIterator子接口,从名字就看的出来,这是个List的迭代器,其中内置了些对List处理的操作,如hasPrevious()方法,对应于hasNext(),previous()方法对应于next()方法,当然,List还有下标index,ListIterator也有nextIndex()或previousIndex()来获取下标;ListIterator还有set()和add()方法来处理。如下所示:
/**
**ListIterator迭代器示例
**/
public static void main(String[] arg0){
LinkedList list = new LinkedList();
list.add("test1");
list.add("test2");
list.add("test3");
ListIterator iterator = list.listIterator(0);
iterator.add("test4");
while(iterator.hasNext()){
System.out.println("next: index="+iterator.nextIndex()+",obj="+iterator.next());
// iterator.remove();
}
}
输出:
next: index=1,obj=test1
next: index=2,obj=test2
next: index=3,obj=test3
在上面可以看到,index是从1开始打印的,说明每调用一次add()或remove()或previous()或next()都会使相应的参数index移动,故而才会出现这种情况。
Comparable & Comparator接口
从名字上“比较”就可以看出来,这两个接口是用来做什么的,对于在集合中的元素,并不是都像List一样有顺序的,但是通过使用这个两个接口就可以用Collections.sort或Arrays.sort让集合中存储的对象变成有序集合。有两个这样的接口,自然是因为这两个接口之间是有区别的,查看源码如下:
/**
**Comparator & Comparable接口源码
**/
public interface Comparator {
public abstract int compare(Object obj, Object obj1);
public abstract boolean equals(Object obj);
}
public interface Comparable {
public abstract int compareTo(Object obj);
}
可以看到,这两个接口中Comparator接口拥有两个方法,其中一个为equals(obj),这处理的是两个对象相等的问题,但是由于Object对象默认就有的equals方法所以可以不用显示实现,不显示实现时使用默认的equals方法。这两个接口比较排序的功能都是其中的compare或compareTo方法来完成,如下所示:
/**
**Comparable使用示例
**/
public static void main(String[] arg0){
List list = new ArrayList();
list.add(new Person("test3",3));
list.add(new Person("test1",1));
list.add(new Person("test2",2));
System.out.println("--before---");
for(Person p:list){
System.out.println(p.toString());
}
System.out.println("--after---");
Collections.sort(list);
for(Person p:list){
System.out.println(p.toString());
}
}
输出:
--before---
Person [name=test3, age=3]
Person [name=test1, age=1]
Person [name=test2, age=2]
--after---
Person [name=test1, age=1]
Person [name=test2, age=2]
Person [name=test3, age=3]
在这里的Person实现了Comparable接口,表示的就是这个类可排序,故而可以通过集合的方法来实现排序功能,当然,对于Comparator方法也是这样,它使用的场景是在于这个原始类并不能被修改的情况下,直接使用Comparator接口来比较两个类型,在Collections中存在sort方法的这种使用方式,这里就不放示例了。
Map集合
查看结构图可知Map下拥有个接口SortedMap和抽象类AbstractMap,其中SortedMap下还有子接口NavigableMap,java.util下的map集合主要围绕这个抽象类和接口进行,其中存在常见的HashMap、LinkedHashMap和TreeMap,也有不怎么用的IdentityHashMap和EnumMap。在Map接口的源代码中存在一个静态的内部接口Entry,其中就包含了几个方法如getKey(),getValue(),setValue(Obj),equals()和hashCode(),这个内部接口在子类的源码中肯定是属于核心。下面从抽象类HashMap开始:
HashMap
查看源码可知,这个类继承了AbstractMap类,并实现了Map,Cloneable, Serializable三个接口,这些接口中也没有很特殊的,所以可以从AbstractMap中入手.在类AbstractMap中,提供了两个Map.Entry接口的内部实现,其中SimpleImmutableEntry类并不能对Value进行设置;同时,可以看到AbstractMap类拥有两个字段Set类型的keySet和Collection的values,需要注意的是其中返回Set的方法entrySet(),在这个抽象类中并没有它的实现,但是大体上也可以清楚它是一个返回Map.Entry集合的方法。
跳出这个抽象类,回到这个类HashMap本身,由源码可知,在HashMap类中存在8个静态内部类,看起来可能很多,但是简单的划分一下就可以得出跟Iterator相关的就有5个类,跟Set相关的则有3个,说明内部结构只用了这2个,横向来看可以看到这里有Entry、Key、Value,说明HashMap内部会有关于这三部分的内容,在这里查看一下Entry类,可以发现它有如下属性:
/**
**HashMap.Entry 属性
**/
final Object key; //键
Object value; //值
Entry next; //下一个节点
final int hash; //hash值
可以看到,其中一个很重要的属性是Entry类型的next字段,说明这是个链表结构的类型。切回HashMap类查看其属性可知:
/**
**HashMap的属性
**/
static final int DEFAULT_INITIAL_CAPACITY = 16; //默认初始化容量大小
static final int MAXIMUM_CAPACITY = 1073741824; //最大容量值
static final float DEFAULT_LOAD_FACTOR = 0.75F; //默认的加载因子
transient Entry table[]; //数据存储
transient int size; //长度
int threshold; //变长的临界值
final float loadFactor; //加载因子
volatile transient int modCount; //修改次数
private transient Set entrySet; //Entry的set集合
根据如上的属性字段,查看HashMap的构造器就会有所发现,如下所示:
/**
**HashMap的某一构造器
**/
public HashMap(int i, float f) {
entrySet = null;
if (i < 0)
throw new IllegalArgumentException(
(new StringBuilder()).append("Illegal initial capacity: ").append(i).toString());
if (i > 1073741824)
i = 1073741824;
if (f <= 0.0F || Float.isNaN(f))
throw new IllegalArgumentException(
(new StringBuilder()).append("Illegal load factor: ").append(f).toString());
int j;
for (j = 1; j < i; j <<= 1)
;
loadFactor = f;
threshold = (int) ((float) j * f);
table = new Entry[j];
init();
}
...
在第一个构造器中就可以发现HashMap构造时,就会初始化它的属性,其中包括loadFactor,threshold,table,并将entrySet置空,这样对于一个普通的HashMap就产生了。
上面这些理解后,在看下其中的put(key,val)方法,源码如下:
/**
**HashMap源码 put()
**/
public Object put(Object key, Object val) {
if (key == null)
return putForNullKey(val);
int i = hash(key.hashCode());
int j = indexFor(i, table.length);
for (Entry entry = table[j]; entry != null; entry = entry.next) {
Object obj2;
if (entry.hash == i && ((obj2 = entry.key) == key || key.equals(obj2))) {
Object obj3 = entry.value;
entry.value = val;
entry.recordAccess(this);
return obj3;
}
}
modCount++;
addEntry(i, key, val, j);
return null;
}
void addEntry(int i, Object key, Object val, int j) {
Entry entry = table[j];
table[j] = new Entry(i, key, val, entry);
if (size++ >= threshold)
resize(2 * table.length);
}
在如上的代码中,首先判断key值是否为null,如果为null那么就将val放入entry数组下标为0的null对应值中;如果key不为null,那么就将通过hash(hashcode)得到一个数i,再通过indexFor()将i与Entry的数组长度进行&运算,获取这个值在这个Entry数组的下标值,然后遍历这个下标下的链表,找出是否已经存在这样一个key满足他们的hashcode和key都相等,如果存在,更新这个链表中Entry的值,不存在则调用后面的addEntry()方法放入这个键值对。
通过这个方法,就可以知道整个hashMap的结构是内部存在一个数组用来存放链表,而在链表中才是真正存放数据的地方。而对于数组来说,需要结合实际情况来构造适当长度的数组来满足性能上的需求,因为链表结构上就不适合做循环遍历。理解了如上过程,那么hashMap就没有多少秘密可言了,其他的方法大体上也是这样一个操作过程。还有就是刚开始说的那几个Set、Iterator内部类,实现的就是entrySet或者keySet之类的功能,并没有很特别的地方。
TreeMap
查看TreeMap源码可知,这个类继承了抽象类AbstractMap同时实现了NavigableMap、Cloneable、Serializable这三个接口,其中NavigableMap属于SortedMap的子接口。作为一个有序的Map规则,SortedMap定义了一些方法如:comparator()、subMap()、headMap()、firstKey()等操作边界的方法,在它的子接口NavigableMap中则多添加了一些以某个有序key为标准的操纵方法,如lowerEntry(key)返回小于且最靠近这个key的Entry。
查看源码可知TreeMap拥有13个内部类,其中有8个内部类和HashMap类似,在这里可以看一下最重要的一个内部类Entry,从field属性中就可以看出一二,源码如下:
/**
**TreeMap.Entry 字段field
**/
Object key; //键
Object value; //值
Entry left; //左子节点
Entry right; //右子节点
Entry parent; //父节点
boolean color; //颜色
可以看到,这个Entry和之前HashMap中的Entry不同,在这里它是一个树形结构,拥有左子节点left,右子节点right,父节点parent与颜色color,看到这里,大概就知道它是使用的红黑树来写的,所以在代码中不可避免的会使用到红黑树的一些操作,如左旋、右旋、着色,如果感兴趣的可以去继续了解红黑色。
知道了内部结构之后,可以继续查看TreeMap几个重要的属性,如下所示:
/**
**TreeMap 源码 field
**/
private final Comparator comparator; //比较器
private transient Entry root; //根节点
private transient int size; //容器大小
private transient int modCount; //结构修改的次数
private static final boolean RED = false;
private static final boolean BLACK = true;
其中的comparator用来比较存放的实体大小,查看TreeMap的构造器,如下所示:
/**
**TreeMap的构造器
**/
public TreeMap() {
root = null;
size = 0;
modCount = 0;
entrySet = null;
navigableKeySet = null;
descendingMap = null;
comparator = null;
}
在这个构造器中,并不会给comparator传值,但是也能正常使用TreeMap,查看到这里,就可以看一下重要的方法put(key,val),源码如下所示:
/**
** TreeMap put(key,val)源码
**/
public Object put(Object key, Object val) {
Entry entry = root;
if (entry == null) {
root = new Entry(key, val, null);
size = 1;
modCount++;
return null;
}
Comparator comparator1 = comparator;
int i;
Entry entry1;
if (comparator1 != null) {
do {
entry1 = entry;
i = comparator1.compare(key, entry.key);
if (i < 0)
entry = entry.left;
else if (i > 0)
entry = entry.right;
else
return entry.setValue(val);
} while (entry != null);
} else {
if (key == null)
throw new NullPointerException();
Comparable comparable = (Comparable) key;
do {
entry1 = entry;
i = comparable.compareTo(entry.key);
if (i < 0)
entry = entry.left;
else if (i > 0)
entry = entry.right;
else
return entry.setValue(val);
} while (entry != null);
}
Entry entry2 = new Entry(key, val, entry1);
if (i < 0)
entry1.left = entry2;
else
entry1.right = entry2;
fixAfterInsertion(entry2);
size++;
modCount++;
return null;
}
这部分代码看起来一大串,其实并不复杂,主要逻辑如下:1.将root根节点赋值给变量entry,判断这个entry是否为null,如果为entry为null,则将这个存储的数据放在根节点上;如果entry不为null,则判断comparator是否为null,如果comparator为空,则将key强转为Comparable,然后调用comparaTo方法,而对于不为空的情况,就可以直接对比两个对象了,这两个只是对比的方式不同,在循环对比后就是给这个对象安家落户,到这里已经完成大部分的代码了,但是这并没有完成;既然属于红黑树,那么就会对可能造成失去平衡的情况进行纠正,也就是之前说的需要进行左旋右旋着色等操作让这个二叉树变平衡,即fixAfterInsertion(entry2)。可以想到的是,为了保持平衡,在插入数据的时候会进行修复操作,那么删除的时候,肯定也是会进行操作的,也就是说,当原有的树结构发生变化的时候就会修复一次。
到这里Map就大体的梳理了一下,其实梳理的并不完整,在TreeMap这部分原本打算把红黑树也放进去,但是关于数据结构的部分,觉得还是专门放在数据结构部分写吧,明年会找个时间总结一下。越到年底越忙,争取在12月结束之前完成梳理基础系列的内容。最近越来越觉得自己太菜了,,能力有限,如果有误,请多多指教。
参考
Java程序设计语言
http://blog.csdn.net/chenssy/article/details/26668941