1、官网地址
http://flume.apache.org/

2、下载Flume1.6 和 Flume1.7

3、下载历史版本
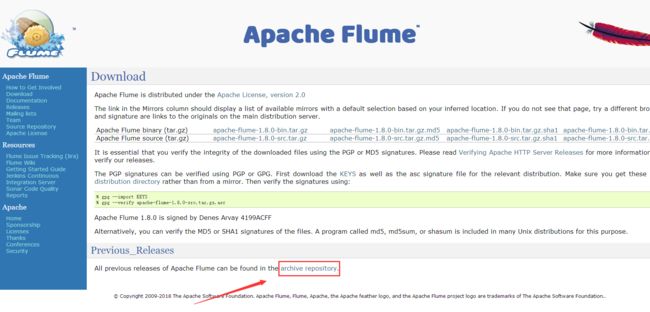
4、历史版本
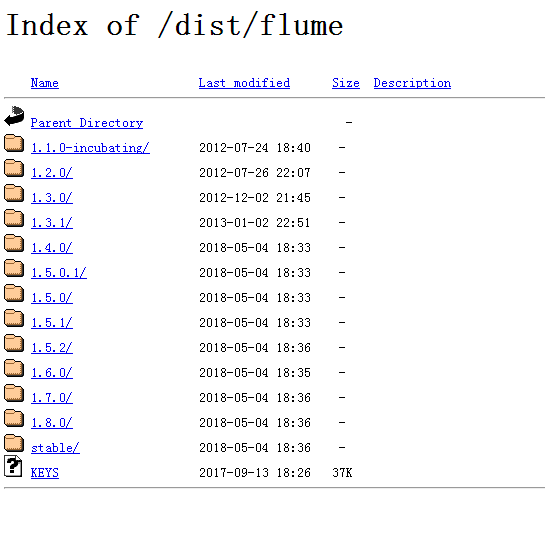
5、Flume 1.7
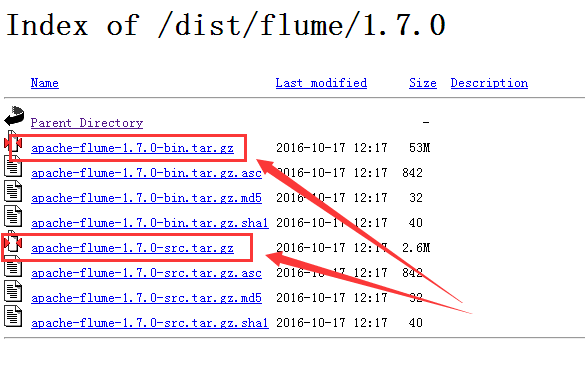
6、Flume 1.6
7、解压Flume1.7 找到下面6个类
PollableSourceConstants.java
ReliableTaildirEventReader.java
TaildirMatcher.java
TaildirSource.java
TaildirSourceConfigurationConstants.java
TailFile.java
8、ReliableTaildirEventReader.java 文件updateTailFiles 方法 源码修改
修改处,标有TODO,有两处修改
/**
* Update tailFiles mapping if a new file is created or appends are detected
* to the existing file.
* 扫描指定的监控目录是否产生了新文件或者文件是否被追加了内容
*/
public List updateTailFiles (boolean skipToEnd) throws IOException {
updateTime = System.currentTimeMillis();
List updatedInodes = Lists.newArrayList();
for (TaildirMatcher taildir : taildirCache) {
Map headers = headerTable.row(taildir.getFileGroup());
//遍历所有匹配的文件
for (File f : taildir.getMatchingFiles()) {
//得到本地文件的inode(储存文件元信息的区域就叫做inode,inode包含除了文件名以外的所有文件信息)
//文件由唯一的inode,不论文件是否重命名,inode不变
long inode = getInode(f);
//tailFiles是一个Map,以inode为key,以TailFile为value
//第一次遍历,此inode对应的Map项肯定不存在
TailFile tf = tailFiles.get(inode);
//源码中导致文件重命名后被重新读取的罪魁祸首
//当文件重命名后,!tf.getPath().equals(f.getAbsolutePath())为True,那么就会创建新的TailFile,然后覆盖Map中原有的key-value对
//TODO 源码修改处
// if (tf == null || !tf.getPath().equals(f.getAbsolutePath())) {
if (tf == null) {
//如果Map中对应文件为空,那么就创建一个TailFile对象
//skipToEnd可配置,决定是否从文件开始位置读取数据还是直接跳到文件结尾
long startPos = skipToEnd ? f.length() : 0;
//openFile中根据传入的参数new了一个新的TailFile
tf = openFile(f, headers, inode, startPos);
} else {
//不为空时进入
//如果文件重命名则进入此分支,由于是对于源码的修改导致重命名后进入,必须再次修改源码以处理重命名情况
//判断此文件的更新时间是否比Map中存储的文件更新时间要新
boolean updated = tf.getLastUpdated() < f.lastModified();
if (updated) {
//如果Map含有对应项,但是得到的tf中封装的文件为null,需要重新创建tf
if (tf.getRaf() == null) {
tf = openFile(f, headers, inode, tf.getPos());
}
// 如果Map中记录的读取位置Pos已经超过了文件长度,那么设置Map中的Pos值为0,即重新从0开始
if (f.length() < tf.getPos()) {
logger.info("Pos " + tf.getPos() + " is larger than file size! "
+ "Restarting from pos 0, file: " + tf.getPath() + ", inode: " + inode);
tf.updatePos(tf.getPath(), inode, 0);
}
}
//重命名后,Map中的文件名还是老的文件名,因此使用openFIle重新创建TailFile用来替换原数据
//TODO 源码修改处
if (!tf.getPath().equals(f.getAbsolutePath())) {
tf = openFile(f, headers, inode, tf.getPos());
}
//modify by zhangpeng end
tf.setNeedTail(updated);
}
//将inode及其对应的tf加入Map中
tailFiles.put(inode, tf);
updatedInodes.add(inode);
}
}
return updatedInodes;
}
9、ReliableTaildirEventReader.java 文件loadPositionFile方法 源码修改
修改处,标有TODO,有一处修改
/**
* Load a position file which has the last read position of each file.
* 加载并解析记录了每个文件最新读取位置的position file
* If the position file exists, update tailFiles mapping.
* 如果position file存在则更新tailFiles映射
*/
public void loadPositionFile(String filePath) {
Long inode, pos;
String path;
FileReader fr = null;
JsonReader jr = null;
//对position file进行读取和解析
try {
fr = new FileReader(filePath);
jr = new JsonReader(fr);
jr.beginArray();
while (jr.hasNext()) {
inode = null;
pos = null;
path = null;
jr.beginObject();
while (jr.hasNext()) {
switch (jr.nextName()) {
case "inode":
inode = jr.nextLong();
break;
case "pos":
pos = jr.nextLong();
break;
case "file":
path = jr.nextString();
break;
}
}
jr.endObject();
for (Object v : Arrays.asList(inode, pos, path)) {
Preconditions.checkNotNull(v, "Detected missing value in position file. "
+ "inode: " + inode + ", pos: " + pos + ", path: " + path);
}
//判断position file中的inode是否存在于TailFile Map中
TailFile tf = tailFiles.get(inode);
//根据对updatePos的分析,当出现重命名时,position file中的path项对应的文件名是旧文件名,而通过updateTailFiles()已经将Map中的文件名更新成了重命名后的文件名
//因此,为了updatePos能够顺利更新pos,应该传入tf.getPath(),即新文件名,tailfile与tailfile自身的文件名的比较必然是相等的
//TODO 源码修改处
//if (tf != null && tf.updatePos(path, inode, pos)) {
if (tf != null && tf.updatePos(tf.getPath(), inode, pos)) {
tailFiles.put(inode, tf);
} else {
logger.info("Missing file: " + path + ", inode: " + inode + ", pos: " + pos);
}
}
jr.endArray();
} catch (FileNotFoundException e) {
logger.info("File not found: " + filePath + ", not updating position");
} catch (IOException e) {
logger.error("Failed loading positionFile: " + filePath, e);
} finally {
try {
if (fr != null) fr.close();
if (jr != null) jr.close();
} catch (IOException e) {
logger.error("Error: " + e.getMessage(), e);
}
}
}
10、pom.xml
4.0.0
com.djt.flume
taildirsource
1.0-SNAPSHOT
UTF-8
org.apache.flume
flume-ng-core
1.6.0
provided
flume-taildirsource
org.apache.maven.plugins
maven-resources-plugin
2.6
${project.build.sourceEncoding}
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.7
1.7
${project.build.sourceEncoding}
11、maven package 打包
12、移植
将flume1.7打包好的源码放到flume1.6/lib目录下即可使用
13、Flume 应用案例 数据采集
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
a1.sources.r1.type = com.victor.flume.source.TaildirSource
a1.sources.r1.channels = c1
#TaildirSource 监控 nio 和 文件元数据信息 放到position.json 通过position去维护map
a1.sources.r1.positionFile = /opt/modules/flume/checkpoint/behavior/taildir_position.json
a1.sources.r1.filegroups = f1
##监控目录
a1.sources.r1.filegroups.f1 = /opt/modules/apache-tomcat-7.0.72-1/logs/OnlineStatistic/victor.log
a1.sources.r1.fileHeader = true
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/modules/flume/checkpoint/behavior
a1.channels.c1.dataDirs = /opt/modules/flume/data/behavior/
a1.channels.c1.maxFileSize = 104857600
a1.channels.c1.capacity = 90000000
a1.channels.c1.keep-alive = 60
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.batchSize = 1
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 1234
a1.sinks.k2.type = avro
a1.sinks.k2.channel = c1
a1.sinks.k2.batchSize = 1
a1.sinks.k2.hostname = hadoop103
a1.sinks.k2.port = 1234
14、Flume 应用案例 日志聚合
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 1234
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/modules/flume/checkpoint/behavior_collect
a1.channels.c1.dataDirs = /opt/modules/flume/data/behavior_collect
a1.channels.c1.maxFileSize = 104857600
a1.channels.c1.capacity = 90000000
a1.channels.c1.keep-alive = 60
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = t-behavior
a1.sinks.k1.brokerList = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.kafka.producer.type = sync
a1.sinks.k1.batchSize = 1
a1.sinks.k1.channel = c1