1、ChannelHandler源码解析
1.1、ChannelHandler功能说明
ChannelHandler类似servlet的Filter过滤器,其负责对I/O事件或I/O操作进行拦截和处理,可以选择性地拦截和处理自己感兴趣的事件,也可以透传和终止事件传播。其实现原理是基于pipeline构成事件处理责任链,inbound或outbound事件沿着处理责任链中的ChannelHandler传播处理。
基于ChannelHandler接口,可以方便实现业务逻辑的个性定制,如打印日志、统一异常封装、性能统计等。
ChannelHandler支持如下注解:
- @Sharable:表示多个ChannelPipeline可以共享同一个ChannelHandler,否则不允许一个ChannelHandler添加到多个Pipeline中。
- @Skip:被Skip注解的方法不会被调用,直接被忽略。
1.2、Channel的生命周期
Channel有以下状态模型:
- channelUnregistered:Channel已创建,但还未注册的EventLoop中。
- channelRegistered:Channel已经被注册到EventLoop中;
- channelActive:Channel处于活动状态,即其已经连接到远程节点,可以进行数据收发处理;
- channelInactive:Channel还未连接带远程节点;
Channel各状态转换图如下:

你会看到多个channelRegistered和channelUnregistered状态的变化,而永远只有一个channelActive和channelInactive的状态,因为一个通道在其生命周期内只能连接一次,之后就会被回收;重新连接,则是创建一个新的通道。
1.3、ChannelHandler类继承图
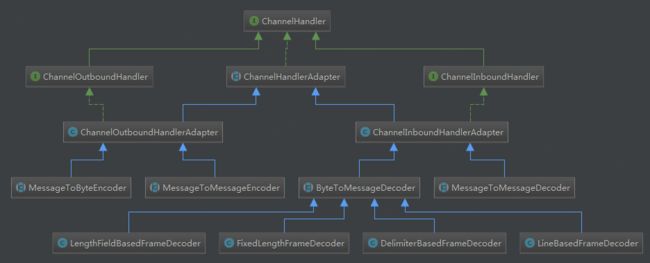
1.4、ChannelHandler接口
此接口定义了ChannelHandler在pipeline中的生命周期操作。在ChannelHandler被添加到ChannelPipeline中或从ChannelPipeline中移除是会调用这些操作。
操作方法如下:
- handlerAdded:当把ChannelHandler 添加到ChannelPipeline 中时被调用,只有调用此方法后,I/O事件的传播才会经由此ChannelHandler处理,否则直接跳过此ChannelHandler;
- handlerRemoved:当从ChannelPipeline 中移除ChannelHandler 时被调用,当被移除后,Channel事件传播将不会经由此ChannelHandler;
- exceptionCaught:当处理过程中在ChannelPipeline 中有错误产生时被调用;
1.5、ChannelInboundHandler接口
此接口定义了Channel的I/O事件接口,这些接口与Channel的生命周期密切相关。
| 方法名称 | 功能说明 |
|---|---|
| channelRegistered | 当Channel 已经注册到它的EventLoop 并且能够处理I/O 时被调用 |
| channelUnregistered | 当Channel 从它的EventLoop 注销并且无法处理任何I/O 时被调用 |
| channelActive | 当Channel 处于活动状态时被调用;Channel 已经连接/绑定并且已经就绪 |
| channelInactive | 当Channel 离开活动状态并且不再连接它的远程节点时被调用 |
| channelReadComplete | 当Channel上的一个读操作完成时被调用 |
| channelRead | 当从Channel 读取数据时被调用 |
| ChannelWritabilityChanged | 当Channel 的可写状态发生改变时被调用。用户可以确保写操作不会完成得太快(以避免发生OutOfMemoryError)或者可以在Channel 变为再次可写时恢复写入。可以通过调用Channel 的isWritable()方法来检测Channel 的可写性。与可写性相关的阈值可以通过Channel.config().setWriteHighWaterMark()和Channel.config().setWriteLowWaterMark()方法来设置 |
| userEventTriggered | 当ChannelnboundHandler.fireUserEventTriggered()方法被调用时被调用,因为一个POJO 被传经了ChannelPipeline |
对于channelRead()方法,当某个子类重写此方法时,其负责显示地释放与池化ByteBuf实例相关的内存。Netty为此提供了ReferenceCountUtil.release()工具方法进行内存释放。同时,Netty也提供了SimpleChannelInboundHandler,其会自动释放ButBuf内存。
实现源码如下:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
boolean release = true;
try {
if (acceptInboundMessage(msg)) {
@SuppressWarnings("unchecked")
I imsg = (I) msg;
channelRead0(ctx, imsg);
} else {
release = false;
ctx.fireChannelRead(msg);
}
} finally {
if (autoRelease && release) {
ReferenceCountUtil.release(msg);
}
}
}
1.6、ChannelOutboundHandler接口
出站操作和数据将由ChannelOutboundHandler接口处理。其方法将被Channel、ChannelPipeline及ChannelHandlerContext调用。
| 方法名称 | 功能说明 |
|---|---|
| bind(ChannelHandlerContext,SocketAddress,ChannelPromise) | 当请求将Channel 绑定到本地地址时被调用 |
| connect(ChannelHandlerContext,SocketAddress,SocketAddress,ChannelPromise) | 当请求将Channel 连接到远程节点时被调用 |
| disconnect(ChannelHandlerContext,ChannelPromise) | 当请求将Channel 从远程节点断开时被调用 |
| close(ChannelHandlerContext,ChannelPromise) | 当请求关闭Channel 时被调用 |
| deregister(ChannelHandlerContext,ChannelPromise) | 当请求将Channel 从它的EventLoop 注销时被调用 |
| read(ChannelHandlerContext) | 当请求从Channel 读取更多的数据时被调 |
| flush(ChannelHandlerContext) | 当请求通过Channel 将入队数据冲刷到远程节点时被调用 |
| write(ChannelHandlerContext,Object,ChannelPromise) | 当请求通过Channel 将数据写到远程节点时被调用 |
ChannelPromise与ChannelFuture:ChannelOutboundHandler中的大部分方法都需要一个ChannelPromise参数,以便在操作完成时得到通知。ChannelPromise是ChannelFuture的一个子类,其定义了一些可写的方法,如setSuccess()和setFailure(),从而使ChannelFuture不可变。
1.7、ChannelHandlerAdapter抽象类
ChannelHandlerAdapter是ChannelHandler的抽象实现类,其主要实现了isSharable()方法,此方法判断ChannelHandler是否为多ChannelPipeline共享的。
1.8、ChannelInboundHandlerAdapter类
ChannelInboundHandlerAdapter为ChannelInboundHandler的实现类,其实现非常简单,所有的方法都是调用其对应的ChannelHandlerContext对应的fileXXX进行处理。
源码示例如下:
public void channelRegistered(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelRegistered();
}
1.9、ChannelOutboundHandlerAdapter类
ChannelOutboundHandlerAdapter为ChannelOutboundHandler的实现类,其实现非常简单,直接调用对应的ChannelHandlerContext对应方法。
源码示例如下:
public void bind(ChannelHandlerContext ctx, SocketAddress localAddress,
ChannelPromise promise) throws Exception {
ctx.bind(localAddress, promise);
}
2、Decoder(解码器)
2.1、粘包、拆包
粘包、拆包是Socket编程中最常见的问题,TCP是个流协议,TCP底层并不了解上层业务的具体含义,其会根据TCP缓冲区的实际情况进行包的划分。
在所以业务上:
- 一个完整的包可能会被TCP拆分为多个包进行发送(拆包);
- 多个小的包也有可能被封装成一个大的包进行发送(粘包);
2.1.1、粘包、拆包产生原因
产生原因大致有以下三种:
- 应用程序写入的字节大小大于Socket发送缓冲区大小
- 进行MSS大小的TCP,MSS是最大报文段长度的缩写,是TCP报文段中的数据字段最大长度,MSS=TCP报文段长度-TCP首部长度
- 以太网的Payload大于MTU,进行IP分片,MTU是最大传输单元的缩写,以太网的MTU为1500字节
2.1.1、粘包、拆包解决思路
由于底层的TCP无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重组的,这个问题只能通过上层的应用协议栈设计来解决,根据业界的主流协议的解决方案,可以归纳如下:
- 消息定长,例如每个报文的大小固定为200字节,如果不够空位补空格
- 包尾增加回车换行符进行分割,例如FTP协议
- 将消息分为消息头和消息体,消息头中包含表示长度的字段,通常涉及思路为消息头的第一个字段使用int32来表示消息的总长度
- 更复杂的应用层协议
拆包思路:
当数据满足了 解码条件时,将其拆开。放到数组。然后发送到业务 handler 处理。
半包思路:
当读取的数据不够时,先存起来,直到满足解码条件后,放进数组。送到业务 handler 处理。
2.2、ByteToMessageDecoder
ByteToMessageDecoder解码器主要功能为将ByteBuf缓冲区中的数据转换为对象,用户的解码器基础ByteToMessageDecoder,只需实现decode(ChannelHandlerContext ctx, ByteBuf in, List
由于ByteToMessageDecoder并未考虑TCP粘包和组包等场景,读半包需要用户解码器自己负责处理。因此,大多数场景不会直接继承ByteToMessageDecoder进行数据解码处理,而是继承一些更高级的解码器来屏蔽半包的处理。
2.2.1、成员变量
ByteToMessageDecoder成员变量如下:
private static final byte STATE_INIT = 0;
private static final byte STATE_CALLING_CHILD_DECODE = 1;
private static final byte STATE_HANDLER_REMOVED_PENDING = 2;
ByteBuf cumulation;
private Cumulator cumulator = MERGE_CUMULATOR;
private boolean singleDecode;
private boolean decodeWasNull;
private boolean first;
/**
* A bitmask where the bits are defined as
*
* - {@link #STATE_INIT}
* - {@link #STATE_CALLING_CHILD_DECODE}
* - {@link #STATE_HANDLER_REMOVED_PENDING}
*
*/
private byte decodeState = STATE_INIT;
private int discardAfterReads = 16;
private int numReads;
成员变量说明:
cumulation:累计器缓存
cumulator:累计器,对从ByteBuf读取的数据进行累积处理;
singleDecode:是否为单消息解码器;
decodeWasNull:解码的数据为空;
first:第一次读取数据;
decodeState :解码器状态;
discardAfterReads :读取多少次后对累计器缓冲区进行discardSomeReadBytes()处理。
numReads:记录读取次数;
2.2.2、累计器解读
成员变量cumulator为ByteToMessageDecoder的累计器,其有两种实现:
MERGE_CUMULATOR:合并累计器
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
final ByteBuf buffer;
if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()
|| cumulation.refCnt() > 1 || cumulation.isReadOnly()) {
// Expand cumulation (by replace it) when either there is not more room in the buffer
// or if the refCnt is greater then 1 which may happen when the user use slice().retain() or
// duplicate().retain() or if its read-only.
//
// See:
// - https://github.com/netty/netty/issues/2327
// - https://github.com/netty/netty/issues/1764
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
} else {
buffer = cumulation;
}
buffer.writeBytes(in);
in.release();
return buffer;
}
};
从cumulate方法可知,其主要是将 unsafe.read 传递过来的 ByteBuf 的内容写入到 cumulation 累积区中,然后释放掉旧的内容,由于这个变量是成员变量,因此可以多次调用 channelRead 方法写入。同时这个方法也考虑到了扩容的问题,当容量 不够时会先进行扩容处理。
COMPOSITE_CUMULATOR:混合累计器
/**
* Cumulate {@link ByteBuf}s by add them to a {@link CompositeByteBuf} and so do no memory copy whenever possible.
* Be aware that {@link CompositeByteBuf} use a more complex indexing implementation so depending on your use-case
* and the decoder implementation this may be slower then just use the {@link #MERGE_CUMULATOR}.
*/
public static final Cumulator COMPOSITE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
if (cumulation.refCnt() > 1) {
// Expand cumulation (by replace it) when the refCnt is greater then 1 which may happen when the user
// use slice().retain() or duplicate().retain().
//
// See:
// - https://github.com/netty/netty/issues/2327
// - https://github.com/netty/netty/issues/1764
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
buffer.writeBytes(in);
in.release();
} else {
CompositeByteBuf composite;
if (cumulation instanceof CompositeByteBuf) {
composite = (CompositeByteBuf) cumulation;
} else {
composite = alloc.compositeBuffer(Integer.MAX_VALUE);
composite.addComponent(true, cumulation);
}
composite.addComponent(true, in);
buffer = composite;
}
return buffer;
}
};
由以上源码可知,此累计器利用CompositeByteBuf类型的ByteBuf,将读取到的数据直接作为一个Component放到CompositeByteBuf中,相较于拷贝,此种累计器性能会更好,但同时也更复杂。
2.2.3、读取数据处理
channelRead()实现源码:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
cumulation = data;
} else {
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= callDecode) {
// We did enough reads already try to discard some bytes so we not risk to see a OOME.
// See https://github.com/netty/netty/issues/4275
numReads = 0;
discardSomeReadBytes();
}
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
fireChannelRead(ctx, out, size);
out.recycle();
}
} else {
ctx.fireChannelRead(msg);
}
}
static void fireChannelRead(ChannelHandlerContext ctx, CodecOutputList msgs, int numElements) {
for (int i = 0; i < numElements; i ++) {
ctx.fireChannelRead(msgs.getUnsafe(i));
}
}
主要处理流程:
- 从对象池中取出一个空的数组。
- 判断成员变量是否是第一次使用,(注意,既然使用了成员变量,所以这个 handler 不能是 handler 的。)将 unsafe 中传递来的数据写入到这个 cumulation 累积区中。
- 写到累积区后,调用子类的 callDecode方法,尝试将累积区的内容解码。
- 解码完成后,若累计器无可读的数据,则清除读计数和累计器缓冲区,如果读次数大于callDecode(默认为16次),则调用discardSomeReadBytes对累计器的缓冲区进行压缩处理。
- 如果解码的对象为空,则设置decodeWasNull 为true;
- 调用fireChannelRead()将解码的对象list遍历交由fireChannelRead()进行处理。
- 将数组清空。并还给对象池。
2.2.3、解码处理
解码实现源码:
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List主要处理流程:
- 循环读取缓冲区数据,如果有上次解码成功而未传播给下个ChannelHandler进行处理的对象,则交由下个Handler进行处理,并清除缓存的对象列表;
- 读取数据并调用 decodeRemovalReentryProtection 方法,内部调用了子类重写的 decode 方法,很明显,这里是个模板模式。decode 方法的逻辑就是将累积区的内容按照约定进行解码,如果成功解码,就添加到数组中。同时该方法也会检查该 handler 的状态,如果被移除出 pipeline 了,就将累积区的内容直接刷新到后面的 handler 中。
- 如果 Context 节点被移除了,直接结束循环。如果解码前的数组大小和解码后的数组大小相等,且累积区的可读字节数没有变化,说明此次读取什么都没做,就直接结束。如果字节数变化了,说明虽然数组没有增加,但确实在读取字节,就再继续读取。
- 如果上面的判断过了,说明数组读到数据了,但如果累积区的 readIndex 没有变化,则抛出异常,说明没有读取数据,但数组却增加了,子类的操作是不对的。
- 如果是个单次解码器,解码一次就直接结束了。
2.3、MessageToMessageDecoder
MessageToMessageDecoder负责将一个POJO对象解码为另一个POJO对象。
2.3.1、数据读取解析
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
CodecOutputList out = CodecOutputList.newInstance();
try {
if (acceptInboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
try {
decode(ctx, cast, out);
} finally {
ReferenceCountUtil.release(cast);
}
} else {
out.add(msg);
}
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
int size = out.size();
for (int i = 0; i < size; i ++) {
ctx.fireChannelRead(out.getUnsafe(i));
}
out.recycle();
}
}
主要处理流程:
- 通过RecyclableArrayList创建新的可循环利用的list对象;
- 对解码的消息类型进行判断,通过则调用decode()方法进行解码处理,处理完成释放缓存对象;
- 类型匹配失败,则直接将对象放到out的list中;
- 最终遍历解码后的POJOlist,将各个解码对象发给下个Handler处理;
- 对象池释放;
2.4、LineBasedFrameDecoder
LineBasedFrameDecoder是Netty提供的一种解码器,专门用于以换行符为分割的消息的解码,能够处理\n和\r\n的换行符,其实现了对粘包、半包等的处理。LineBasedFrameDecoder继承ByteToMessageDecoder,这样对于转换字节为POJO对象的底层工作就交给ByteToMessageDecoder类来实现了,LineBasedFrameDecoder类只需要负责对消息的字节流进行解包即可。
处理大体思路:
- 没有需要忽略的数据:
(1)、若找到换行符,若长度超过最大长度,则直接失败处理;否则读取数据,并返回数据;
(2)、若未找到换行符,若长度超过最大长度,则进行需要忽略的数据的相关参数设置,并等待底层继续读取数据;
- 有需要忽略的数据:
(1)、若找到换行符,则直接忽略掉上次的半包数据及本次读取的数据,并设置无忽略相关的参数;
(2)、若未找到换行符。则直接设置忽略相关的参数,等待底层继续读取数据;
解码实现源码:
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {
final int eol = findEndOfLine(buffer);
if (!discarding) {
if (eol >= 0) {
final ByteBuf frame;
final int length = eol - buffer.readerIndex();
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
if (length > maxLength) {
buffer.readerIndex(eol + delimLength);
fail(ctx, length);
return null;
}
if (stripDelimiter) {
frame = buffer.readRetainedSlice(length);
buffer.skipBytes(delimLength);
} else {
frame = buffer.readRetainedSlice(length + delimLength);
}
return frame;
} else {
final int length = buffer.readableBytes();
if (length > maxLength) {
discardedBytes = length;
buffer.readerIndex(buffer.writerIndex());
discarding = true;
offset = 0;
if (failFast) {
fail(ctx, "over " + discardedBytes);
}
}
return null;
}
} else {
if (eol >= 0) {
final int length = discardedBytes + eol - buffer.readerIndex();
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
buffer.readerIndex(eol + delimLength);
discardedBytes = 0;
discarding = false;
if (!failFast) {
fail(ctx, length);
}
} else {
discardedBytes += buffer.readableBytes();
buffer.readerIndex(buffer.writerIndex());
}
return null;
}
}
private int findEndOfLine(final ByteBuf buffer) {
int totalLength = buffer.readableBytes();
int i = buffer.forEachByte(buffer.readerIndex() + offset, totalLength - offset, ByteProcessor.FIND_LF);
if (i >= 0) {
offset = 0;
if (i > 0 && buffer.getByte(i - 1) == '\r') {
i--;
}
} else {
offset = totalLength;
}
return i;
}
主要处理流程:
- 查找行尾,findEndOfLine()中主要查找字符'\n',找到并检查其其前一个字符是否为’\r‘;
- 如果不能忽略数据且找到换行符,则一行数据进行处理;如果数据长度大于maxLength,则设置读索引readerIndex并进行异常处理;如果返回的数据需要忽略换行符,则只读取数据并跳过换行符,否则读取数据及换行符;
- 如果不能忽略但未找到换行符,若可读数据长度大于maxLength,则设置discardedBytes为缓冲区可读数据的长度,设置读索引readerIndex为写索引writterIndex,设置discarding为true表示有忽略的数据;偏移量设置为0;若设置了快速失败则直接报异常;若可读数据长度小于等于maxLength则不对数据进行处理;
- 当有忽略的数据时,若找到换行符,则设置读索引readerIndex为换行符之后,设置discardedBytes为0,设置discarding为false,并做快速失败处理;
- 当有忽略的数据时,若未找到换行符,则这是discardedBytes为可读字节数并设置读索引readerIndex为写索引writterIndex;
2.5、DelimiterBasedFrameDecoder
DelimiterBasedFrameDecoder实现了根据一个或多个分隔符对ByteBuf进行解码处理;其处理流程大体和LineBasedFrameDecoder类似。
处理大体思路:
- 根据分隔符列表遍历缓冲区数据,找到匹配某个分隔符的最短的索引位置及其对应的分隔符;
- 分隔符找到,并且有需要忽略的数据,则对数据做忽略及异常处理;否则处理数据并返回数据;
- 分隔符未找到,若无需要忽略的数据,若可读数据长度大于最大长度,则进行忽略数据的相关处理;
- 分隔符为找到,若哟需要忽略的数据,则直接进行忽略数据的处理。
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {
if (lineBasedDecoder != null) {
return lineBasedDecoder.decode(ctx, buffer);
}
// Try all delimiters and choose the delimiter which yields the shortest frame.
int minFrameLength = Integer.MAX_VALUE;
ByteBuf minDelim = null;
for (ByteBuf delim: delimiters) {
int frameLength = indexOf(buffer, delim);
if (frameLength >= 0 && frameLength < minFrameLength) {
minFrameLength = frameLength;
minDelim = delim;
}
}
if (minDelim != null) {
int minDelimLength = minDelim.capacity();
ByteBuf frame;
if (discardingTooLongFrame) {
// We've just finished discarding a very large frame.
// Go back to the initial state.
discardingTooLongFrame = false;
buffer.skipBytes(minFrameLength + minDelimLength);
int tooLongFrameLength = this.tooLongFrameLength;
this.tooLongFrameLength = 0;
if (!failFast) {
fail(tooLongFrameLength);
}
return null;
}
if (minFrameLength > maxFrameLength) {
// Discard read frame.
buffer.skipBytes(minFrameLength + minDelimLength);
fail(minFrameLength);
return null;
}
if (stripDelimiter) {
frame = buffer.readRetainedSlice(minFrameLength);
buffer.skipBytes(minDelimLength);
} else {
frame = buffer.readRetainedSlice(minFrameLength + minDelimLength);
}
return frame;
} else {
if (!discardingTooLongFrame) {
if (buffer.readableBytes() > maxFrameLength) {
// Discard the content of the buffer until a delimiter is found.
tooLongFrameLength = buffer.readableBytes();
buffer.skipBytes(buffer.readableBytes());
discardingTooLongFrame = true;
if (failFast) {
fail(tooLongFrameLength);
}
}
} else {
// Still discarding the buffer since a delimiter is not found.
tooLongFrameLength += buffer.readableBytes();
buffer.skipBytes(buffer.readableBytes());
}
return null;
}
}
处理流程:
- 若分隔符为换行分隔符,则直接调用换行分隔符的解码器进行处理;
- 遍历所有分隔符,查找到索引最小的分隔符及其对应的索引;
- 若分隔符找到,若上次有需要忽略的数据,则直接进行数据跳过处理;否则读取数据并返回数;
- 若未找到分隔符,若无需要忽略的数据,则判断数据长度是否大于最大长度,是则进行忽略数据处理,否则不进行处理;
2.6、LengthFieldBasedFrameDecoder
LengthFieldBasedFrameDecoder是基于自定义数据长度进行解码的解码器;
2.6.1、基本属性
private final ByteOrder byteOrder;
private final int maxFrameLength;
private final int lengthFieldOffset;
private final int lengthFieldLength;
private final int lengthFieldEndOffset;
private final int lengthAdjustment;
private final int initialBytesToStrip;
private final boolean failFast;
private boolean discardingTooLongFrame;
private long tooLongFrameLength;
private long bytesToDiscard;
byteOrder:字节序,大端或小端;
maxFrameLength:最大数据长度,超过此长度说明数据包错误;
lengthFieldOffset:length字段相对于读索引readerIndex的偏移量;
lengthFieldLength:length字段的字节长度,其长度只能为1、2、3、4、8中的一个,其他长度错误;
lengthFieldEndOffset:表示紧跟长度域字段后面的第一个字节的在整个数据包中的偏移量
lengthAdjustment:计算调整后的长度字段的偏移量;
initialBytesToStrip:初始需要跳过的长度;
failFast:快速失败标志;
discardingTooLongFrame:忽略过长数据包标志;
tooLongFrameLength:过长数据的当前长度;
bytesToDiscard:需要忽略的字节数;
2.6.1、解码实现流程
decode()实现源码:
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
if (discardingTooLongFrame) {
discardingTooLongFrame(in);
}
if (in.readableBytes() < lengthFieldEndOffset) {
return null;
}
int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);
if (frameLength < 0) {
failOnNegativeLengthField(in, frameLength, lengthFieldEndOffset);
}
frameLength += lengthAdjustment + lengthFieldEndOffset;
if (frameLength < lengthFieldEndOffset) {
failOnFrameLengthLessThanLengthFieldEndOffset(in, frameLength, lengthFieldEndOffset);
}
if (frameLength > maxFrameLength) {
exceededFrameLength(in, frameLength);
return null;
}
// never overflows because it's less than maxFrameLength
int frameLengthInt = (int) frameLength;
if (in.readableBytes() < frameLengthInt) {
return null;
}
if (initialBytesToStrip > frameLengthInt) {
failOnFrameLengthLessThanInitialBytesToStrip(in, frameLength, initialBytesToStrip);
}
in.skipBytes(initialBytesToStrip);
// extract frame
int readerIndex = in.readerIndex();
int actualFrameLength = frameLengthInt - initialBytesToStrip;
ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);
in.readerIndex(readerIndex + actualFrameLength);
return frame;
}
private void exceededFrameLength(ByteBuf in, long frameLength) {
long discard = frameLength - in.readableBytes();
tooLongFrameLength = frameLength;
if (discard < 0) {
// buffer contains more bytes then the frameLength so we can discard all now
in.skipBytes((int) frameLength);
} else {
// Enter the discard mode and discard everything received so far.
discardingTooLongFrame = true;
bytesToDiscard = discard;
in.skipBytes(in.readableBytes());
}
failIfNecessary(true);
}
处理流程:
- 上一次数据包过长,并且有未读取完的需要跳过的数据,则进行跳过处理;
- 如果可读数据长度小于长度字段的下个字节偏移量,表示数据长度不够,不做处理;
- 获取长度字段并对长度字段进行处理,当长度小于0或小于长度字段下个字节偏移量,则进行失败处理;
- 当包长度大于最大长度时,调用exceededFrameLength()进行数据跳过处理;
- 当可读长度小于包中标识的长度,表示数据为读完,不做处理;
- 当包长度小于需要跳过的长度,进行失败处理;
- 读取缓冲区中的数据;
2.7、其他解码器
Netty内置了丰富的ChannelHandler,例如处理Http协议的Handler、处理Websocket协议的Handler、处理SSL安全套接字连接的Handler等等,此处不做进一步分析。
相关阅读:
Netty源码愫读(一)ByteBuf相关源码学习 【https://www.jianshu.com/p/016daa404957】
Netty源码愫读(二)Channel相关源码学习【https://www.jianshu.com/p/02eac974258e】
Netty源码愫读(三)ChannelPipeline、ChannelHandlerContext相关源码学习【https://www.jianshu.com/p/be82d0fcdbcc】
Netty源码愫读(五)EventLoop与EventLoopGroup相关源码学习【https://www.jianshu.com/p/05096995d296】
Netty源码愫读(六)ServerBootstrap相关源码学习【https://www.jianshu.com/p/a71a9a0291f3】
参考书籍:
《Netty实战》
《Netty权威指南》
参考博客:
https://www.jianshu.com/p/4c35541eec10
https://www.jianshu.com/p/0b79872eb515
https://www.jianshu.com/p/a0a51fd79f62
http://www.wolfbe.com/detail/201609/379.html