原论文链接:https://arxiv.org/abs/1701.07174
Towards End-to-End Face Recognition through Alignment Learning
通过对齐学习实现端到端的人脸识别
YuanyiZhong,JianshengChen,BoHuang,DepartmentofElectronicEngineering,TsinghuaUniversity
摘要
近十年来,人们提出了许多有效的人脸识别方法。虽然这些方法在许多方面是不同的,他们通常的做法是要求在人脸特征提取之前,根据人脸结构的先验知识对人脸区域进行对齐。在大多数系统中,人脸对齐模块是独立实现的。这导致了端到端的人脸识别模型的训练和设计十分困难。在本文中,我们研究了通过对齐学习实现端到端的人脸识别的可能性,既不需要先验知识,也不需要人工定义的几何变换。具体来说,在卷积神经网络(CNN)中将一个空间变换层插入到特征提取层之前的人脸识别。只通过人类的身份线索来驱动神经网络自动学习对于识别任务来说最合适的几何变换和最合适的面部区域。为确保可重复性,我们的模型进行训练只在公开的CASIA webface数据集,测试是在LFW数据集。我们已经实现了99.08%的验证精度,与目前最先进的基于模型的方法相媲美。
1 介绍
在过去的几年中,卷积神经网络(CNN)的引入大大提高了现有计算机视觉任务的性能,包括面部识别和验证[ 25, 23, 24,30, 22, 19,33 ]。代替传统的通过手工标记特征来构建分类模型,深度学习通过数据驱动成功提高了面部特征的鲁棒性。因此,受过良好训练的CNN网络能够较好的处理人脸图像的姿势、遮挡和光照变化[ 22, 19, 8 ]。
然而,现实生活场景中的大姿态变化仍然是人脸识别系统在实际应用中面临的挑战。一般有两种方法来处理这个问题:一种方法是建立姿势感知或基于部分的模型来处理特定姿势的人脸图像[ 17, 15 ]。另一种更常用的方法是在人脸识别的特征提取前引入一个明确的面部对齐过程[ 23, 10, 30,8 ]。以往的研究已经证实,[ 22, 19 ]加入人脸对齐步骤,特别是在测试阶段,能有效地提高识别性能。因此,一个典型的人脸识别过程通常包括四个阶段:(1)从图像中检测人脸,(2)特征点定位和通过二维或三维几何变换对齐检测人脸,(3)特征提取,(4)基于可能的特征模板识别个人身份。最近的研究表明,虽然3D对齐似乎优于2D,但在CNN中对于提取面部特征并没有显示出明显优势[ 1 ]。

Figure 1:在AFW [ 44 ]数据集上结果对比。绿色矩形是人脸检测结果,红色矩形显示模型预测投影变换的对齐面孔。
对于这样一个框架,有两个主要的问题:人脸对齐和面部特征提取是独立执行的。首先,大多数的人脸对齐方法[ 36, 20, 7,40 ]依靠准确的人脸特征点定位、视觉的问题,这可能是比人脸识别更难得任务,考虑到面部特征人工标注比收集个人身份信息更费力、更昂贵。的确,面部标志可以用于其他有趣的应用,如人脸合成和动作单元分析。我们在这里所说的是,可能没有必要将定位面部基点作为人脸识别的一个先决条件。更重要的是,这样一个框架下,面部基点的重新定义和重新标记训练数据对于其他的细粒度的分类任务如动物识别[ 42, 41 ]是不可避免的。第二,几何变换的原则通常在人脸对齐中人为定义。例如,一种广泛使用的策略是通过非反射相似变换将眼睛和嘴巴周围的基点对齐。然而,现在并不清楚基于其他特征点的二维变换,后续的人脸特征提取是否能从中获益尚不清楚。
因此,一个重要的问题是面部特征识别可以成功地用数据驱动的方式来学习,那么为什么不能数据驱动面部对齐呢?毕竟,其他阶段都可以通过数据驱动训练的时候,在校准过程中仍然要依靠人工先验知识会显得格格不入。因此,在本文中,我们提出一个深度学习的人脸识别模型,用一个空间变换模块[ 12 ]来完成人脸对齐的过程,使人脸的对齐和识别可以统一到同一个类型的框架。该模型具有端到端的可训练性该模型是端到端的可训练性,它不需要任何明确的关于人脸特征的知识和人为定义的对齐规则。在训练过程中,该模型通过自动学习一致地对齐每个人脸图像,从而更适合进行下一步的面部识别,而且只利用基于身份的线索。
我们通过实验观察到该模型一般倾向于将人脸矫正到一个正面垂直的标准位置,就像人们现有的试探过方法[ 23, 38 ]。这并不奇怪,因为大多数人脸在现实生活中的形象几乎是垂直的。图1显示了我们的模型预测的人脸大姿态变化下的投影变换。有趣的是在模型训练中从未使用过底层真值转换的监督信号的情况下。模型预测与底层的真值转换符合度很高。
本文所提出的方法有很多优点。通过一个端到端的学习,人脸对齐和面部特征提取可以相互作用,从而在识别任务中实现联合优化。增强了人脸识别对环境的适应能力和捕捉设备的变化能力。更重要的是,学习转化以及中间过程的面部图像可以很容易地用于其他目的。例如,垂直归一化人脸图像可能有助于更精确的人脸属性预测和基点定位。此外,该模型可以很容易地扩展到其他细粒度的图像分类问题。这项工作的主要贡献可概括如下:
(1)提出了一个既不需要独立的人脸对齐过程,也不需要先验知识的人脸识别系统。
(2)我们表明,本文提出的端到端的人脸识别模型可通过标准的SGD训练。
(3)我们揭示了人脸识别不需要先验知识!这表明尽管神经科学证实的功人的面部感知是由许多功能构成的[ 14 ],但是关于人脸是否以及如何感知不同于一般细粒度的物体仍然是一个悬而未决的问题。
论文的组织如下:在第2节我们简要地介绍了几个现有的相关的工作。在第3节中,我们将描述我们的模型体系结构的细节。在在第4节描述在LFW [ 11 ]数据集和YTF [ 34 ]数据集上的实验结果。第5节总结本文的工作。
2相关的工作
近年来,深度学习模型的引入极大地促进了人脸识别技术的发展。自Facebook的DeepFace系统[ 30 ]显示数据驱动的人脸识别的深度学习范式更有效,基于主流的人脸识别基准的识别率频繁被刷新。大量的深度模型被提出用于人脸识别,尤其是CNNs。例如DeepID [ 23, 27, 24 ],FaceNet [ 22。相比于传统的手工标注特征点也已被广泛接受,如高维LBP特征[ 5 ]、通过人工设计的约束进行特征学习例如Bayesian face以及Gaussian-Face,基于个人身份进行自动学习无论是在识别能力还是鲁棒性方面都更具优势。
在大多数基于学习的人脸识别方法中,在训练和测试过程中,深度模型的输入都是对齐的人脸图像。通常,通过在检测到的面部标志和特定预定义面部基准点之间进行二维或三维[ 10, 30 ]几何变换来进行对齐。研究表明,正确的对齐方式对识别性能至关重要。Parkhi et. Al.证实了在LFW数据集上测试,对人脸进行对齐后提高了1%的识别精度时。同时表明,在识别率方面,3D对准与简单的2D对齐并没有明显优势。因此,本文只关注二维图像对齐问题。
……
事实上,其他计算机视觉任务中已经对学习几何变换进行了研究,例如手写数字识别和鸟类分类[ 12 ]。更具体地说,Jaderberg et. Al.引入一个可导的叫做空间转换的CNN组件,其目的是提高CNN对变换、缩放、旋转甚至更一般的图像扭曲结构的鲁棒性[ 12 ]。由于其可微性,空间转换器可以通过反向传播针对特定的任务基于具体的feature map进行训练,学习最优的变换参数。最近,Chen et. Al.成功地利用空间转换器以监督的方式提高了人脸检测的性能[ 6 ]。在这项工作的启发下,我们建议使用空间转换器,同时进行最佳人脸对齐与面部特征提取的人脸识别学习。以前的工作类似于我们的建议是[ 29 ],其中一个神经网络被用来预测转换参数,以方便在嵌入式平台上进行人脸识别。然而,这种神经网络在监督方式采用人工定义转换参数作为真值训练。虽然我们的目标是使自动学习的最佳几何变换的人脸识别只通过个人身份线索驱动。因此,将不再需要人工定义转换形式,并且可以方便地进行面部识别模型的端到端训练。
3方法
本节介绍了拟议的端到端人脸识别系统的总体设计。首先描述了我们的系统的总体架构。重点讨论了用于预测几何变换参数的定位网络的设计方案。为了确保本文的完整性和可重复性,我们详细阐述了不同变换类型的空间转换层[12]的细节。还考察了变换类型的选择对人脸识别性能的影响。
3.1系统的体系结构
一般来说,一个典型的人脸识别系统是以摄像机捕获的图像或视频序列作为输入,并将定位到的人脸身份作为输出。目前,人脸识别系统一般分为三个主要组成部分:检测、对准和识别。这三个组件通常是分开设计和训练的。这种情况的一个可能的历史原因是,在传统的技术框架下,不同的结构的数学模型适合于这三个不同的计算机视觉任务。将这些模型结合与统一是比较困难的。
然而,最近的研究结果已经证实,CNN在人脸检测[ 40 ]、面部基点标记[ 43 ] [ 23, 30 ]和识别有很好的效果。更有趣的是,这些不同的任务中使用的CNN网络结构可以彼此相似。这实际上使得端到端人脸识别模型的设计和实现在技术上成为可能。理想情况下,应该使用输入图像中的标识线索作为监督信息,以完全的端到端方式对模型进行训练。因此将最佳的图像区域以及对它们的最佳变换同时学习,将有利于个人身份识别。但这种模式的培训也非常困难。为了简化这一问题,我们将人脸检测作为一项独立的任务,只关注于端对端的设计和实现,如图2所示。这样的设计与认知神经科学的假设相一致,即人脸检测和识别可能在人脑中使用独立的专用资源和机制[ 31 ]。
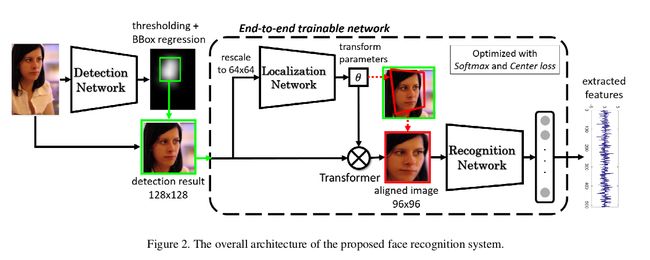
对人脸检测的任务,我们在googlenet[ 28 ]第二个模块后加了两个额外的层来做人脸的显著性图预测和面部边框回归,在公开的WIDER数据集[ 37 ]上微调googlenet模型的初始化权值。类似的方法已在Unitbox方法[ 39 ]中采用,微调VGG网代替的googlenet。这种简单明了的方法的性能相当令人满意。在FDDB [ 13 ]数据集上达到200误报83%的召回率。示例人脸检测结果也如图1所示。实际上,任何现成的人脸检测系统,如经典的多层前馈神经网络(MTCNN)[ 40 ]都可以用在我们的系统中。我们已经通过实验证明,人脸检测精度对最终的识别结果的影响的是微乎其微的。这主要是因为定位网络可以成功地学习合适的方法来提高检测框的精确度和稳定性。
对于定位和识别任务,我们设计了一个端到端的网络主要包括三部分:基于下采样的输入人脸图像预测的二维转换参数的定位网络;一个采样器,扭曲的人脸图像根据预测的转换参数和深刻的面部特征提取网络识别。该网络的数据流和中间结果如图2所示。
在训练阶段,检测到的人脸边框和个人身份信息用于监督。更具体地说,根据检测的边界框初次裁剪面部区域,然后这些crops作为输入传到网络上后被重新调整为128*128像素。对于定位网络,我们采用了3个卷积层的神经网络,它们的内核大小分别为5*5, 3*3和3*3。在每个卷基层之后使用PReLU和2*2的池化层。之后将一个64全连接层放在几何变换参数回归层(投影变换的是8个参数,仿射变换是6个,相似变换是4个)之前。输入的crops在被送入定位网络之前经过下采样到64*64像素,因为我们观察到在计算变换参数时通常没必要使用高分辨率图像。受到[ 33 ]的启发,ResNet针对视觉识别的各种问题都具有较高的泛化能力,我们使用深度残差网络(ResNet)[ 9 ]来识别特征提取和表示学习。残差网络由9个残差模块,24个卷积层组成,输出512维特征向量,来捕捉内在变化。在[ 33 ]中提出的CenterLoss函数和SoftMax一起使用,用与识别过程学习判别特征。
3.2、定位网络
定位网络的设计实质上是对结构复杂度与预测精度之间的权衡。为了方便端到端的训练,只要保证足够的预测精度,结构越简单越有利。因此,我们进行了实验,以确定最佳的定位网络体系结构。我们首先通过适应在CASIA webface [ 38 ]图像集和LFW图像集上以传统方式预定义的面部基点位置来计算仿射变换参数。然后在结构的复杂性增加的同时保持参数的总数是大致相同的情况下,用webface图像集来训练一系列的转换网络。我们在LFW图像集上测试了所训练的网络结构的泛化能力。最终采用较小的拟合误差和复杂度适当的网络体系结构。网络的细节设计以及拟合误差如表1所示。通过对比结果,我们选择了网络组成方式为:3个卷基层和1个全连接层,并在每层后加入一个PReLU层。
3.3空间变换网络
根据原DeepMind文章[ 12 ],空间变换网络可通过参数的变换用于执行任何包括平移、缩放、仿射变换、投影,甚至薄板样条变换。在传统的人脸对齐中一般采用相似变换。然而Wagner et.al.证明了在人脸识别中处理大姿态变化采用投影变换的稳健性和有效性[ 32 ]。为了保证严谨性,我们研究了三种齐次变换,即相似、仿射、和投射。考虑到Jaderberg et. Al在[12]中仅详细介绍了仿射变换的具体实现,我们只简要的回顾了空间转换网络的结构,并以投影
变换和相似变换为例具体阐述它们的前后向计算。
…….
正如引言部分所提到的,被广泛使用在人脸识别对齐方案是非反射相似变换。然而,目前还不清楚不同类型的2D转换会如何影响人脸识别性能。为了探索最适合人脸识别的变换类型,我们将训练四个模型,它们分别是全等、相似、仿射和投影四种不同的变换,同时保持训练集和其余网络结构不变。对于同一变换,将检测到的人脸区域直接裁剪在中心进行识别,不进行实质性变换。在LFW和YTF的相应结果和人脸准确度将在第4.1节呈现。
3.4讨论
事实上,基于我们提出的框架实现一个完全的端到端人脸识别系统是可行的。面部检测阶段实际上可以作为区域建议网络[ 21 ]或一个注意力模型]来预测候选面部区域,以便能够容易地与前面提到的对齐和识别网络结合起来。此外,虽然空间转换网络是可导的,但梯度下降法并不是训练它们的唯一方法。强化学习[ 3 ]为基础的方法用来训练网络可能更加高效。
4实验结果
这一节描述了两组实验来证明该方法的有效性。首先,识别实验,在LFW和YTF的数据集进行。以前的工作已经证实,可以通过增加训练集的大小[ 22 ]或通过多个深层模型的集成来有效地提高人脸识别的准确性[ 24 ]。然而,在这项工作中,我们主要研究端到端架构的可行性,以及不同的转换类型进行人脸对齐对识别结果的影响。因此我们使用不同的转换
参数类型在CASIA webface图像集来训练对齐网络,并且只使用单一的深度模型进行识别。这也确保了这项工作的可重复性。第二,我们测试了使用该型预测变换来提高现有算法面部基点定位精度的有效性。
4.1识别实验
我们训练我们提出的端到端的网络在纯净版的CISIA-WebFace数据集,它包含10K个人的460K图像。水平翻转图像用于训练过程中的数据增强。对于每个WebFace图像,都使用在第三节描述的人脸检测器来定位面部区域。然后使用检测边框的略微放大的版本裁剪原始图像。裁剪后的图像被用作端到端对齐和识别网络的训练输入。若未能检测到人脸我们裁剪固定大小中心的原始图像。
我们将设置每个训练迭代为100个图像。同时使用cenrerloss和softmax损失函数。这相对于Softmax损失中心损失系数设置为0.008,如[ 33 ]推荐。识别网络的学习率设置为0.01,每10000次迭代后衰减。我们在实验中观察到,当定位网络的学习率比识别网络小10到100倍时,达到最好的训练结果。这可以理解为考虑到识别网络的损失值在实际中比变换参数的值大近1到2个数量级。训练过程花了大约8小时在NVIDIA titanx GPU,100000次迭代之后。
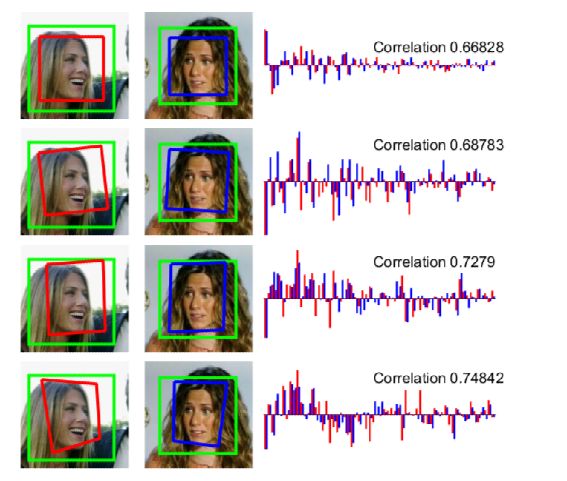
Figure 3对不同转换类型的模型预测变化和提取Jennifer
Aniston的脸部特征进行比较。自上而下分别是恒等的、相似的、仿射的和投影的变化。绿色的矩形是人脸检测结果、红色的四边形显示预测的转换。右边显示所提取的特征向量的前64个主成分及其相应的相关系数(余弦相似性)。
虽然提出的网络以端到端方式的训练,我们发现在识别网络的训练过程中它有助于随机重新
初始化网络参数。这可能是由于定位网络与识别网络结构复杂度的巨大差异所造成的。由于其相对简单的结构,在训练的初期,通常很容易使定位网络在其全局最优值附近稳定下来。相反,由于识别网络结构复杂,在定位网络稳定之前识别陷入局部最优的机会很高。因此,重新初始化的为网络识别提供了一个机会,让它跳出局部最优。?
我们在两种广泛使用的无约束人脸识别基准数据集上测试我们的模型,即LFW和YTF。LFW集包含5749人的13233幅人像,需要验证6000对人脸;YTF包含1595人的3425个视频
,要求验证5000视频对。这两个数据集都允许10次交叉验证,根据unrestricted with labeled outside data协议标准。我们将计算的每个测试图像两个特征向量的均值及其镜像版本作为深度特征表示。利用PCA降维后,利用特征向量之间的余弦距离计算一对图像之间的相似度。我们训练PCA并根据9个训练组选择最佳分类阈值,然后对剩下的测试组进行测试。
表2显示了验证性能的数值结果。为了公平的比较,我们也独立训练ResNet识别网络上的预对齐(标准化)的webface数据集提供的图像。可以根据验证精度进行若干观察。首先,在四种类型的变换中,恒等变换导致最低的验证精度(97.68%和92.9%)。这与以前的研究结果一致,即人脸图像的显式对齐可以显著地提高人脸识别的效率。第二,虽然共享相同的底层识别网络结构,但在人工标注的对齐(98.35%)上训练的模型在验证精度方面不如经
过对齐学习的网络。这表明了对齐和识别的端到端联合训练的优点。第三,与相似变换(98.65%)和仿射变换(98.71%)相比,投影变换(99.08%)更适合于人脸识别。这并不奇怪,因为投影变换能更准确地描述大多数人脸图像的摄像机成像过程。
图3直观地说明了不同的变换模式对人脸特征提取的影响。直观地说,可以观察到一种趋势,即更复杂的变换类型通常会导致提取的人脸特征更高的鲁棒性,特别是对于具有大姿态变化的图像。图4和图5显示了相应的ROC曲线。可以看出,相对于LFW数据集,不同的转换类型的验证精度的影响在YTF数据集并不显著。相似变换和仿射变换的曲线几乎相互重合。这是预料之中的,人脸姿势变换问题很大程度上被从YTF在视频一系列的帧序列图像中提取面部特征均值缓解。尽管如此,明确的面部对对齐仍然有帮助。
4.2基点定位实验
我们的模型预测的变换可以用来将脸部区域标准化为接近正面的标准视图。除了识别,归一化的人脸图像可以用来提高其他任务的准确性,如性别识别,表达分类和基点定位。在大多数现有的人脸识别系统中,基点定位通常是人脸对齐的基础。然而,我们将在这里演示,面部对齐可以反过来用于提高面部基点定位的准确性,特别是相对容易产生姿势变化的方法。
基本思想很简单,如图6所示。人脸对齐后,在归一化的人脸图像上代替原始图像进行地标定位。然后使用几何变换将点的坐标映射到原始图像以进行对齐。我们选择了基于主动形状模型(ASM)方法的一个典型实现[ 18 ]作为例子。从图6中我们可以看到由于面部姿态变化引起的原始地标的明显不准确,并且在脸部对齐的帮助下可以得到显著的改进。我们在LFPW[2]数据集上测试的地标位置精度。位置误差被测量为16个标记和所在地标之间的平均距离。这样的错误是由两眼间距离归一化。图7比较了累积误差分布(CED)和校准曲线。通过对准获得了明显的改进。

Figure 6:利用预测变换改进面部基点位置。第一列:ASM结果(青色点)对原始图像和预测的投影变换(红色四边形)。第二列:使用预测变换和重新定位基点的标准化人脸图像。第三列:重新定位的基点投射到原始图像上。

对于更强大的现代方法,如监督下降法(SDM)[ 36 ],所提出的方法也可以应用于改善他们的困难情况下的表现。图8显示了如何在一个包含非常大的姿态变化的人脸图像上进行人脸对齐。周围的标志物的准确度有了显著的提高。
5结论
我们提出的人脸定位和人脸特征提取可以共同训练,仅使用个人身份作为监控信号的端到端的训练框架。因此,人脸识别中不再需要人脸特征和人工定义的几何变换原理的明确知识。我们的建议实际上为将来实现一个完全的端到端人脸识别系统奠定了基础,该系统实际上可以很容易地扩展到其他细粒度的对象识别任务。未来的工作是利用更多的训练数据和更精心设计的数据增强策略,提高变换预测对极端姿态变化和夸张面部表情的鲁棒性。