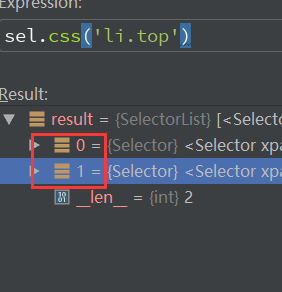
scrapy至少有三种选择器,很大很多。理论上学会两种就够用了。
项目组都用一个选择器最好了。
一定要学会正则表达式。


第一种介绍CSS选择器



标签成对出现。
div,p不管div和p有什么关系,都搜索出来
div p 选择div下的所有p元素可以是父子关系也可以是爷孙关系等。
div>p 这个只能是父子关系。
还有一个函数 extract_first()切片,extract()切片脱壳

脱壳后
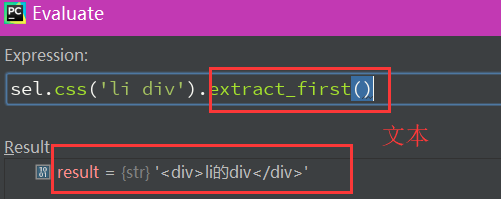
选择器返回的一般都是一个list,要记住,我们想要的都是结果文本
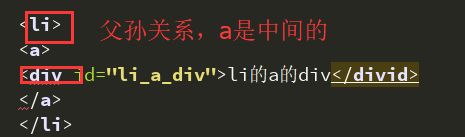
而li和a是父子关系。
示例:
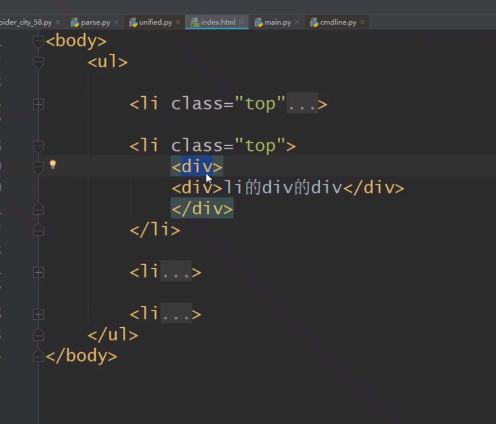
p标签,li标签,a标签
单独抽离scrapy选择器
都是借用什么找到什么。如:借用class=‘top’这个属性找到li标签
此时做断点调试最合适。
辅助断点测试参考文章:
http://blog.csdn.net/lanchunhui/article/details/49514297

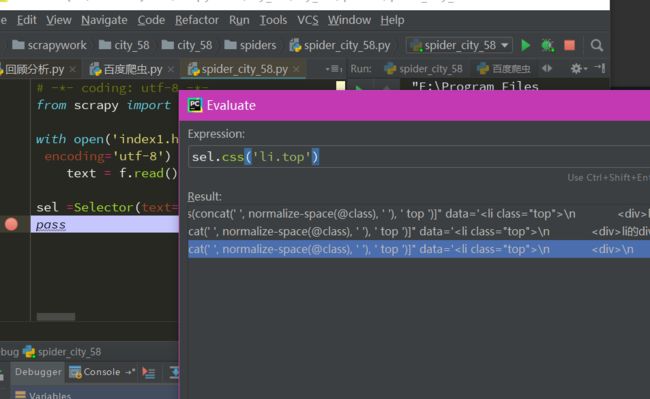
id唯一,class不唯一
012代表几个标签。
xpath写法
跟文件路径很像,默认第一层/html,单斜杠就是一层
双斜杠是搜索的意思,跟css什么都不带一样
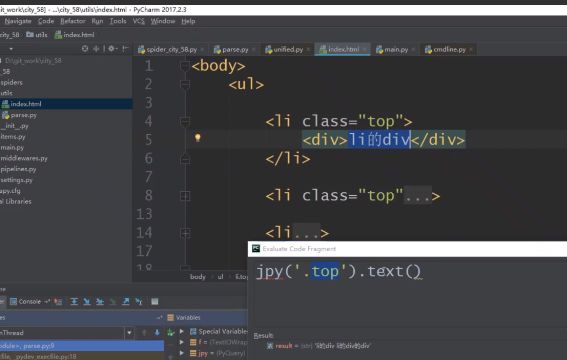
文本和属性,属性是class=‘top’,文本是li的div用text()
下图是属性写法

Xpath的使用方法
寻找可以匹配 xpath query 的节点,并返回 SelectorList 的一个实例结果,单一化其所有 元素。列表元素也实现了 Selector 的接口。query 是包含XPATH查询请求的字符串
该方法可以通过 response.xpath() 调用
选取节点
Xpath 使用路径表达式在 XML文档中选取节点。节点是通过沿着路径或者step来选取的。
下面列出了最有用的路径表达式:
[图片上传失败...(image-91e392-1517579430475)]
Xpath选择器使用示例:
Xpath选择方法之前在入门课程第四课已学习过了,仍然使用上面的例子:
查找ul标签下的li元素:
sel.xpath(‘/html/body/ul/li’)
可见其返回了一个SelectorList实例
查找所有的li标签:
sel.xpath(‘//li’)
可见其返回了一个SelectorList实例
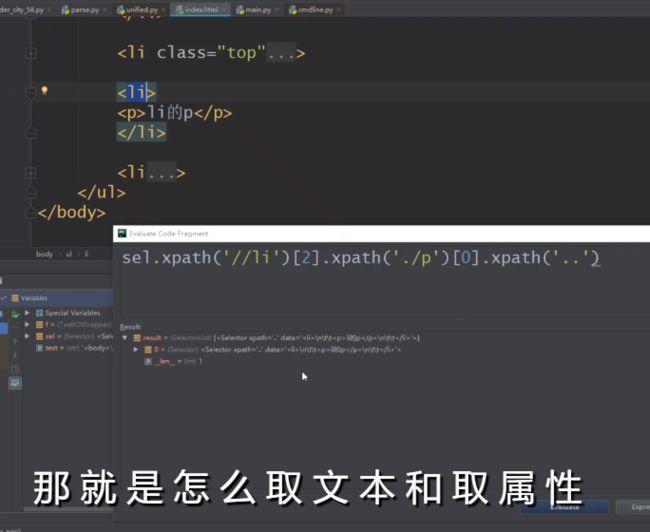
查找第三个li标签下的第一个p标签:
sel.xpath(‘//li’)[2].xpath(‘./p’)[0]
可见其返回了一个SelectorList实例
同样可以调用.extract()方法提取数据:
查找a标签下的div标签的文本:
sel.xpath(‘/html/body/ul/li/a/div/text()’).extract_first()
RE的使用方法
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE)它通常被用来检索、替换那些符合某个模式(规则)的文本。
常用元字符:
[图片上传失败...(image-df6557-1517579430475)]
[图片上传失败...(image-be1293-1517579430475)]
[图片上传失败...(image-a908c-1517579430475)]
匹配神器:
- (.*)具有贪婪的性质,首先匹配到不能匹配为止,根据后面的正则表达式,会进行回溯。
- (.*?)则相反,一个匹配以后,就往下进行,所以不会进行回溯,具有最小匹配的性质。
pyquery的使用方法
pyquery可以让你使用类似jQuery语法来对xml进行操作,pyquery语法尽可能跟jQuery语法相似 ,类似于css
pyquery使用lxml库对xml和html进行快速的处理
pyquery这个库目前还不是一个可以跟JavaScript代码交互的库
兼容性好,不用各种脱壳
建议平时用pyquery
提文本,提属性
pyquery选择器使用示例:
打开同级目录下的HTML文件,所获取的jpy变量是PyQuery,可以直接使用jpy对其进行选择:
from pyquery import PyQuery
with open('test.html' , encoding='utf-8') as f:
text = f.read()
jpy = PyQuery(text)
pass
查找class=‘top’的元素的文本:
jpy(‘.top’).text()
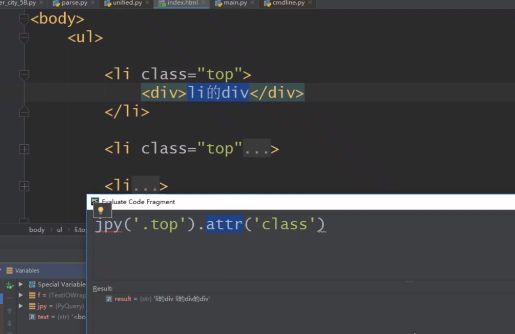
查找class=‘top’的元素的class属性:
jpy(‘.top’).attr(‘class’)
查找li标签下所有的文本,遍历时候必须加items函数
items = jpy(‘li’)
for i in items.items():
···· print(i.text())
li的div
li的div的div
li的p
li的a的div
查找li标签下所有的class属性
items = jpy(‘li’)
for i in items.items():
···· print(i.attr(‘class’))
top
top
None
None