目前常用的传统RDBMS到HDFS的数据同步工具有三种:Sqoop(Apache),DataX(阿里云开源的离线同步工具),Kettle(pentaho)。
数据同步过程中,需要关注以下规则及技术点[1]:
1. 无论运行多少次,HDFS中的操作都应该产生相同的结果。
2. 在将数据移入HDFS之前,须将其汇总,以便MapReduce程序使用最少量的内存进行转换,特别是在namenode上。
3. 将数据移入HDFS之前,请将其从一种格式转换为另一种适用于目标系统的格式。
4. 实现故障切换,以便在失败时再次尝试操作,例如某个节点不可用。
5. 验证数据在网络传输时是否已损坏。
6. 控制所使用的并行数量,并限制运行的MapReduce程序的数量。 这两个功能都会影响资源消耗和性能。
7. 监控您的操作以确保其成功并产生预期的结果。
数据同步的一般流程如下[2]:
1. 将源数据库数据进行导出,使用Sql或DB原生的导出命令直接导出为txt等文本文件,字段以分隔符进行分隔。
1.1 可以部署多个代理端,对数据库数据启用多个线程进行导出
1.2 支持基于key值或时间戳的增量数据导出
2. 对导出的数据进行压缩后进行传输(特别是在源和目标库不在同一个数据中心时)
3. 在目标库端基于数据库原生的load命令对数据进行bulk批量导入。
Sqoop:

Sqoop的一个特点就是可以通过hadoop的mapreduce把数据从RDBMS导入数据到HDFS。[4]
使用Sqoop进行数据同步的大致流程如下[3,4,5]:
1.读取要导入数据的表结构,生成运行类,默认是QueryResult,打成jar包,然后提交给Hadoop。
2.设置好job,主要也就是设置好各个参数。
3.由Hadoop来执行MapReduce,执行Import命令,
1)首先要对数据进行切分,也就是DataSplit
2)切分好范围后,写入范围,以便读取
3)读取以上2)写入的范围,
4)然后创建RecordReader从数据库中读取数据
5)创建Map
6)RecordReader一行一行从关系型数据库中读取数据,设置好Map的Key和Value,交给Map
7)运行map
Sqoop验证数据同步效果有3个基本接口,通过导入导出数据结果的行数进行验证。[6]
1. ValidationThreshold - 确定源和目标之间的误差容限是否可以接受:绝对值,百分比容差等。默认实现为AbsoluteValidationThreshold,可确保源和目标的行计数相同。
2. ValidationFailureHandler - 负责处理故障:记录错误/警告,中止等。默认实现是LogOnFailureHandler,它向配置的记录器记录一条警告消息。
3. Validator - 通过将决策委托给ValidationThreshold并将故障处理委托给ValidationFailureHandler来驱动验证逻辑。默认实现是RowCountValidator,它验证源和目标的行计数。
DataX:
DataX框架如下:[7]
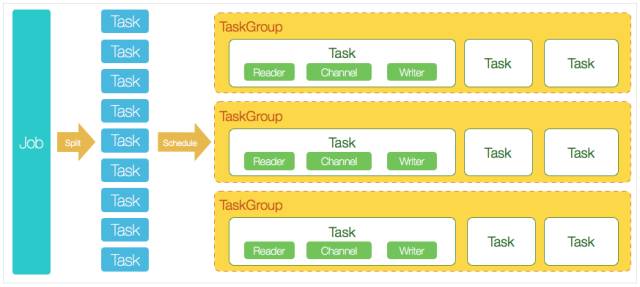
核心模块介绍:
1 DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
2 DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
3 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
4 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
5 DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
1 DataXJob根据分库分表切分成了100个Task。
2 根据20个并发,DataX计算共需要分配4个TaskGroup。
3 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
Kettle[8]:
使用Kettle导入文件到HDFS流程:
启动Kettle,新建Job。
添加Start主键。
添加Hadoop Copy Files主键。
将上面两个主键连接起来。
编辑Copy Files主键。
保存Job。
7. 运行Job。
其它:
Sqoop与DataX的比较:
https://chu888chu888.gitbooks.io/hadoopstudy/content/Content/9/datax/datax.html
参考:
https://www.ibm.com/developerworks/library/ba-hadoop-rdbms/index.html
http://blog.sina.com.cn/s/blog_493a84550102w83v.html
http://宋亚飞.中国/post/145
https://www.zybuluo.com/sasaki/note/272640
https://docs.qingcloud.com/guide/sqoop.html
http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html#_introduction_2
https://github.com/alibaba/DataX/wiki/DataX-Introduction
http://wiki.pentaho.com/display/BAD/Loading+Data+into+HDFS