1 前言
今天开始来和大家一起学习一下Redis实际应用篇,会写几个Redis的常见应用。
在我看来Redis最为典型的应用就是作为分布式缓存系统,其他的一些应用本质上并不是杀手锏功能,是基于Redis支持的数据类型和分布式架构来实现的,属于小而美的应用。
结合笔者的日常工作,今天和大家一起研究下基于Redis的分布式锁和Redlock算法的一些事情。

2.初识锁
1. 锁的双面性
现在我们写的程序基本上都有一定的并发性,要么单台多进线程、要么多台机器集群化,在仅读的场景下是不需要加锁的,因为数据是一致的,在读写混合或者写场景下如果不加以限制和约束就会造成写混乱数据不一致的情况。
如果业务安全和正确性无法保证,再多的并发也是无意义的。
这个不由得让我想起一个趣图:
高并发多半是考验你们公司的基础架构是否强悍,合理正确地使用锁才是个人能力的体现。
凡事基本上都是双面的,锁可以在一定程度上保证数据的一致性,但是锁也意味着维护和使用的复杂性,当然也伴随着性能的损耗,我见过的最大的锁可能就是CPython解释器的全局解释器锁GIL了。
没办法 好可怕 那个锁 不像话--《说锁就锁》
锁使用不当不但解决不了数据混乱问题,甚至会带来诸如死锁等更多问题,通俗地说死锁现象:
几年前会出现这样的场景:在异地需要买火车票回老家,但是身份证丢了无法购票,补办身份证又需要本人坐火车回老家户籍管理处,就这样生活太难。
2. 无锁化编程
既然锁这么难以把控,那不得不思考有没有无锁的高并发。
无锁编程也是一个非常有意思的话题,后续可以写一篇聊聊这个话题,本次就只提一下,要打开思路,不要被困在凡是并发必须加锁的思维定势。
在某些特定场景下会选择一种并行转串行的思路,从而尽量避免锁的使用,举个栗子:
Post请求:http://abc.def/setdata?reqid=abc123789def&dbname=bighero
假如有一个上述的post请求的URI部分是个覆盖写操作,reqid=abc123789def,服务部署在多台机器,在大前端将流量转发到Nginx之后根据reqid进行哈希,Nginx的配置大概是这样的:
upstream myservice{ #根据参数进行Hash分配 hash $urlkey; server localhost:5000; server localhost:5001; server localhost:5002;}
经过Nginx负载均衡相同reqid的请求将被转发到一台机器上,当然你可能会说如果集群的机器动态调整呢?我只能说不要考虑那么多那么充分,工程化去设计即可。
然而转发到一台机器仍然无法保证串行处理,因为单机仍然是多线程的,我们仍然需要将所有的reqid数据放到同一个线程处理,最终保证线程内串行,这个就需要借助于线程池的管理者Disper按照reqid哈希取模来进行多线程的负载均衡。
经过Nginx和线程内负载均衡,最终相同的reqid都将在线程内串行处理,有效避免了锁的使用,当然这种设计可能在reqid不均衡时造成线程饥饿,不过高并发大量请求的情况下还是可以的。
只描述不画图 就等于没说:

3. 单机锁和分布式锁
锁依据使用范围可简单分为:单机锁和分布式锁。
Linux提供系统级单机锁,这类锁可以实现线程同步和互斥资源的共享,单机锁实现了机器内部线程之间对共享资源的并发控制。
在分布式部署高并发场景下,经常会遇到资源的互斥访问的问题,最有效最普遍的方法是给共享资源或者对共享资源的操作加一把锁。
分布式锁是控制分布式系统之间同步访问共享资源的一种方式,用于在分布式系统中协调他们之间的动作。
3.分布式锁
1. 分布式锁的实现简介
分布式CAP理论告诉我们需要做取舍:
任何一个分布式系统都无法同时满足一致性Consistency、可用性Availability和分区容错性Partition Tolerance三个方面,最多只能同时满足两项。
在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只保证最终一致性。在很多场景中为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。
分布式锁一般有三种实现方式:
- 基于数据库在数据库中创建一张表,表里包含方法名等字段,并且在方法名字段上面创建唯一索引,执行某个方法需要使用此方法名向表中插入数据,成功插入则获取锁,执行结束则删除对应的行数据释放锁
- 基于缓存数据库RedisRedis性能好并且实现方便,但是单节点的分布式锁在故障迁移时产生安全问题,Redlock是Redis的作者 Antirez 提出的集群模式分布式锁,基于N个完全独立的Redis节点实现分布式锁的高可用
- 基于ZooKeeperZooKeeper 是以 Paxos 算法为基础的分布式应用程序协调服务,为分布式应用提供一致性服务的开源组件
2. 分布式锁需要具备的条件
分布式锁在应用于分布式系统环境相比单机锁更为复杂,本文讲述基于Redis的分布式锁实现,该锁需要具备一些特性:
- 互斥性在任意时刻,只有一个客户端能持有锁 其他尝试获取锁的客户端都将失败而返回或阻塞等待
- 健壮性一个客户端持有锁的期间崩溃而没有主动释放锁,也需要保证后续其他客户端能够加锁成功,就像C++的智能指针来避免内存泄漏一样
- 唯一性加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给释放了,自己持有的锁也不能被其他客户端释放
- 高可用不必依赖于全部Redis节点正常工作,只要大部分的Redis节点正常运行,客户端就可以进行加锁和解锁操作
3. 基于单Redis节点的分布式锁
本文的重点是基于多Redis节点的Redlock算法,不过在展开这个算法之前,有必要提一下单Redis节点分布式锁原理以及演进,因为Redlock算法是基于此改进的。
最初分布式锁借助于setnx和expire命令,但是这两个命令不是原子操作,如果执行setnx之后获取锁但是此时客户端挂掉,这样无法执行expire设置过期时间就导致锁一直无法被释放,因此在2.8版本中Antirez为setnx增加了参数扩展,使得setnx和expire具备原子操作性。

在单Matster-Slave的Redis系统中,正常情况下Client向Master获取锁之后同步给Slave,如果Client获取锁成功之后Master节点挂掉,并且未将该锁同步到Slave,之后在Sentinel的帮助下Slave升级为Master但是并没有之前未同步的锁的信息,此时如果有新的Client要在新Master获取锁,那么将可能出现两个Client持有同一把锁的问题,来看个图来想下这个过程:
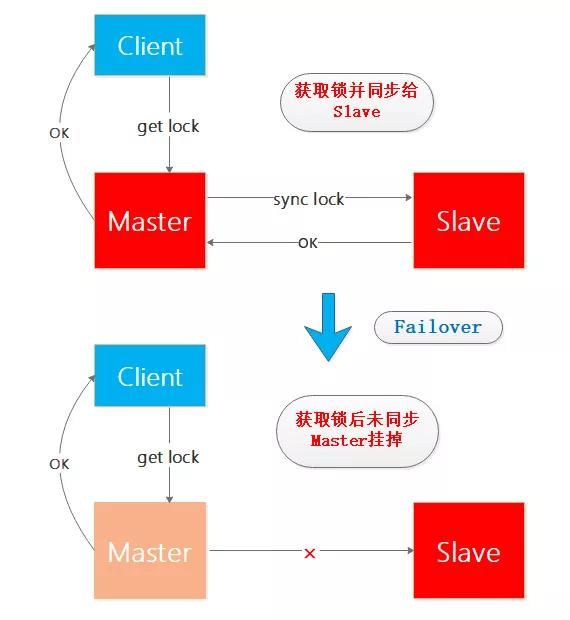
为了保证自己的锁只能自己释放需要增加唯一性的校验,综上基于单Redis节点的获取锁和释放锁的简单过程如下:
// 获取锁 unique_value作为唯一性的校验
SET resource_name unique_value NX PX 30000
// 释放锁 比较unique_value是否相等 避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这就是基于单Redis的分布式锁的几个要点。
4.Redlock算法过程
Redlock算法是Antirez在单Redis节点基础上引入的高可用模式。
在Redis的分布式环境中,我们假设有N个完全互相独立的Redis节点,在N个Redis实例上使用与在Redis单实例下相同方法获取锁和释放锁。
现在假设有5个Redis主节点(大于3的奇数个),这样基本保证他们不会同时都宕掉,获取锁和释放锁的过程中,客户端会执行以下操作:
- 1.获取当前Unix时间,以毫秒为单位
- 2.依次尝试从5个实例,使用相同的key和具有唯一性的value获取锁当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间,这样可以避免客户端死等
- 3.客户端使用当前时间减去开始获取锁时间就得到获取锁使用的时间。当且仅当从半数以上的Redis节点取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功
- 4.如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间,这个很重要
- 5.如果因为某些原因,获取锁失败(没有在半数以上实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁,无论Redis实例是否加锁成功,因为可能服务端响应消息丢失了但是实际成功了,毕竟多释放一次也不会有问题
上述的5个步骤是Redlock算法的重要过程,也是面试的热点,有心的读者还是记录一下吧!
5.Redlock算法是否安全的争论