-
获得训练图片的路径和标签
load_files()
函数读取之后输出的是文本文档
filenames 的输出是文件的路径
target 的输出是子文件夹的名字。在这里子文件夹名字是 c0,c1,c2,c3...c9。但是读取出来的是0,1,2,3,....9。不过不会影响使用,后面要转化成为独热编码。
*特别注意:如果读取的文件夹下面没有子文件夹,命令用不了,也就是没有'target'的值。
def img_load(path):
data = load_files(path)
files = data['filenames']
#targets = np_utils.to_categorical(np.array(data['target']), 10)
targets = data['target']
return files, targets
-
获得文件名&路径
for maindir, subdir, file_name_list in os.walk(dirname):
命令读取文件目录,文件上一级目录,文件名。os.walk()输出的是三个值(列表)。
如果要组成完整的文件目录,需要再加工一步:
apath = os.path.join(maindir, filename)
def path_and_name(dirname):
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
name = file_name_list
return result,name
-
读取图片为array
cv2.imread().astpye(np.uint8)
读取图片的时候,默认格式是np.float64,在这里为了省内存,用np.uint8
矩阵2个常用的命令
np.expand_dims(x,axis=0)
此为增加维度命令。axis值代表的是在什么地方增加维度。0代表在最前面增加
x=x.transpose((2,0,1))
此为转换维度顺序。原本是(0,1,2)的3维矩阵,转换成了(2,0,1)。最常见的情况就是将颜色通道放在最前面/最后面
要查看某个矩形的形状 x.shape
def img_read(path,img_cols=299, img_rows=299):
img = cv2.imread(path).astype(np.uint8)
img_newsize = cv2.resize(img,(img_cols,img_rows))
#img_newsize.transpose((2,0,1))
#np.expand_dims(img_newsize, axis=2)
return img_newsize
-
按司机ID来划分训练集
由于一个司机ID的图像是从视频里面截取出来的,所以如果训练的时候,训练集合验证集都有同一个ID的图像。基本可以说是判断准确率100%了。这样训练的分数高,实际在其他地方很低。
划分ID是读取了CSV的文件。使用的命令包括
pd.read_csv()
读取CSV文件之后,list.index代表了第一列
随后使用set()简单粗暴的去除重复。
list.classname 可以获得分类的名字,其中'classname'是表格中的表头内容
list.img可以获得图片的名字
- 用迁移学习提取特征
这是一次失败的尝试。最开始使用可VGG19来提取特征,然后分类,效果很不理想。推断是VGG19预训练的模型(在ImageNet预训练)和司机的图片契合度太差了。
def found_features(path):
base_model = VGG19(weights = 'imagenet')
x = img_read(path)
x = np.expand_dims(x, axis=0)
base_model = bese_model
model = Model(inputs=base_model.input,
outputs=base_model.get_layer('block4_pool').output)
return model.predict(x)
-
保存model文件
先创建一个文件夹来保存h5文件,判断如果文件夹不存在,则创立新的文件夹'cache'。使用命令:
if not os.path.isdir('cache'): os.mkdir('cache')
保存文件,在这里使用overwrite=True
def save_model(model, index, cross=''):
json_string = model.to_json()
if not os.path.isdir('cache'):
os.mkdir('cache')
json_name = 'architecture' + str(index) + cross + '.json'
weight_name = 'model_weights' + str(index) + cross + '.h5'
#open(os.path.join('cache', json_name), 'w').write(json_string)
model.save_weights(os.path.join('cache', weight_name), overwrite=True)
-按司机ID来创立列表
一级列表有26个子列表(司机ID26个),每个二级列表里包含的是一个司机ID对应的图片路径。
同样的标签也按同样的方法来创立成两级列表,与图片路径一一对应。
来获取一个路径末尾文件名的方法如下:
os.path.basename(X_path[ii])
获得pandas.DataFrame 文件某个index下的值的方法:
img_list.loc['c1'].values
为了方便查看进度,只打印一排内容,在后面加上 , 表示不换行。
def X_and_y(X_path,y_,img_list,ID):
print('按司机ID分类数据')
X = []
y = []
nu = 0
for i in ID:
X_array = []
y_array = []
for ii in range(len(X_path)):
if os.path.basename(X_path[ii]) in img_list.loc[i].values:
#x_ar = found_features(X_path[ii]) #将在ID下图片的提取特征
x_ar = X_path[ii]
X_array.append(x_ar) #形式为 [[特征 ],[特征 ] ...]
y_array.append(y_[ii])
print("{}/{} Data named {}.........{}files\r".
format(nu+1,len(ID),i,len(img_list.loc[i]))),
X.append(X_array) #形式为 [ [[ID1_特征 ],[ID1_特征 ] ...] ,[[ID2_特征 ] [ID2_特征 ] ...] ,...]
y.append(y_array)
nu += 1
return X,y
-
执行函数,分别获得训练图片路径以及标签的双层列表
ID,classname,list_img_name,img_list = driver_id('driver_imgs_list.csv',index_col = 'subject')
X_path,y_ = img_load('train')
X_data,y_data = X_and_y(X_path,y_,img_list,ID)
-
自己先做一个测试集出来检查算法
从训练集中拿出两个ID下的子列表出来,做成自己的训练集。这个时候就要把原来的训练集和测试集##减去##两个ID,使用的是:del X_data[:2]。 这个命令只能执行一次,执行1次就会扣除两个子列表。
既然是做测试集,这里就不需要再按ID分类了,在这一步就把两层列表变为一层:
test_fe,test_la = X_data[:2],y_data[:2]
del X_data[:2]
del y_data[:2]
#制作自己的test先自己测试一次
test_feature = []
test_label = []
for a in test_fe:
for i in a:
test_feature.append(i)
for b in test_la:
for ii in b:
test_label.append(ii)
print(type(test_feature),len(test_label))
print(len(X_data))
print(len(y_data))
-
模型搭建的种种过程
-
使用迁移学习直接训练模型
首先使用了VGG19的预训练模型。
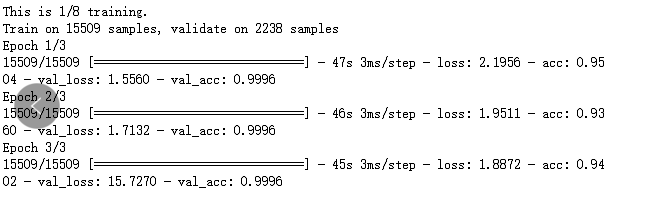
loss函数~2.0,而准确率还可以接近1。一定是哪里出了问题。
在第一时间想到的是模型上的问题(其实不是)。
-
使用迁移学习提取特征
采用了VGG19/Xception 来提取特征。在这里遇到的麻烦是:
(1) VGG输入图片格式为(244,244,3),而Xception输入图片格式为(299,299,3)。因此在前面定义的def img_read()函数中,需要更改一下图片的reshape。
(2)提取出来的特征展平做全连接层的时候出现了内存错误。
-
从头搭建网络
从头搭建VGG16网络,采用的是序贯模型。搭建好网络之后载入下载的VGG16权重。
然后使用model.layers.pop() 去除最后一个输出层(1000个分类)继续添加全连接层和softmax分类层。
训练几次之后发现效果仍然不佳。采用了如下方法:
(1)添加dropout,估计是过拟合。添加之后训练过程的分数与之前无大的进步。
(2)仔细检查特征和标签。发现是在写入时有误(下一节仔细分析)
(3)对模型使用正则。
model.add(Dense(64, input_dim=64,kernel_regularizer=regularizers.l2(0.001), activity_regularizer=regularizers.l1(0.001)))
(4)调整学习率 lr=le-1/ -2/ -3/ -4 /-5
(5)不载入权重,从头训练
-
从头搭建Xception网络
Xception搭建需要使用函数式模型。函数式模型可以有多个输入以及多个输出。
载入Xception 没有top的权重,然后继续分类。在这里我犯了一个观念上的错误,在添加后面的层的时候还使用序贯模型的做法,报错。
为了使模型可视化,有两中办法:
(1)采用 model.summary() 输出简单的模型内容。可以看到Output Shape,Param, Connected to 这三个内容。
(2)将模型打印成PNG图片保存:
from keras.utils import plot_model
plot_model(model, to_file='model.png')
可以接收两个参数:
show_shapes:指定是否显示输出数据的形状,默认为False
show_layer_names:指定是否显示层名称,默认为True
-
采用迁移学习,融合多个模型
融合了Xception以及InceptionV3模型,将两个模型的倒数第二层作为输出。没有在各自迁移学习模型里用池化层。
使用函数模型将两个结合在一起,结合之前由于输入的形状不一致,((None,10,10,2048)(None,8,8,2048)),因此采用GAP将输出转为一维,然后再进行联合。
在这里有几个注意的地方:
(1)在这里使用的是tensor
(2)在输入数据前需要使用Input()函数
第一次完全在训练之后发现分数只达到了0.4,第二次采用方法为InceptionV3不载入预训练权重。
两次训练的分数为0.4和0.6
-
准备训练数据
在训练的时候才读入图片为(299,299,3)的格式。在这里有几个注意点:
(1)根据训练集的大小先创建好空的矩阵,再逐个写入。train_feature_A = np.zeros(shape=[number_of_train_A,input_l,input_w, input_c])
(2)标签要转换成为独热编码:np_utils.to_categorical(np.array(y_data_A[i][N]),10))
(3)在训练时候前几次使用了keras自带的数据预处理命令preprocess_input(train_feature_A)。经过测验,这样的预处理出来预测值非常极端。后来直接采用的是不预处理的 np.uint8 格式数据。
(4)训练过程中最常常遇到的问题是内存不足的问题。最终的解决办法是每一折训练都保存权重文件。如果内存不足,重新载入权重继续训练。在这里的训练时长就比较长了:
 image.png
image.png 使用模型融合
使用整合训练,普通堆叠。堆叠方法由上一篇翻译文得出:kaggle 模型融合指导
-
预测测试集,制作提交文件
预测的时候的几个细节:
- 仍然是内存问题。由于预测文件高达有79726个,在准备测试集的时候。采用创建空矩阵再逐个写入的办法,发现内存又不够了。所以每次预测都先退出清空内存之后,只运行载入模型和训练好权重再预测,没有办法接上一歩训练模型后继续预测。
- 由于测试集没有子目录,所以不能使用第一步的方法取得文件路径。这里使用的命令是:
for maindir, subdir, file_name in os.walk('test'):必须要取得文件名的原因是在提交文件CSV里面index为img名称。 - 在准备提交文件的时候,由于后面采用了两个模型整合预测,占用内存增大,无论如何都无法创建测试集数目大小的空矩阵。
于是采用了逐行写入CSV的办法,每一个图片单独预测,得到10个分类的概率之后写入文件:
def write_csv(path):
path = all_path(path)
header = ['img', 'c0', 'c1', 'c2', 'c3', 'c4', 'c5', 'c6', 'c7','c8', 'c9']
number_all = len(path)
with open('subm/kjkj.csv', 'wb')as f:
f_csv = csv.DictWriter(f,header)
f_csv.writeheader()
path = path
n =1
for i in path:
img_name = os.path.basename(i)
img_arr = img_read(i)
img_arr = np.expand_dims(img_arr, axis=0)
p = model.predict(img_arr)
row = [{'img':img_name,
'c0':p[0][0],
'c1':p[0][1],
'c2':p[0][2],
'c3':p[0][3],
'c4':p[0][4],
'c5':p[0][5],
'c6':p[0][6],
'c7':p[0][7],
'c8':p[0][8],
'c9':p[0][9] }]
f_csv.writerows(row)
print('pre {} complete!.........{}/{}\r'.format(n,n,number_all)),
n+=1
-
使用CMA查看模型关注的地方