一个scikit-learn教程,通过将数据建模到KMeans聚类模型和线性回归模型来预测MLB每赛季的胜利。
Python编程语言是数据科学和预测分析的绝佳选择,因为它配备了多个软件包,可满足您的大部分数据分析需求。对于Python中的机器学习,Scikit-learn(sklearn)是一个很好的选择,它建立在NumPy,SciPy和Matplotlib(分别是N维数组,科学计算和数据可视化)之上。
在本教程中,您将了解如何轻松地从数据库加载数据sqlite3,如何使用pandas和探索数据并提高数据质量matplotlib,以及如何使用Scikit-Learn包提取一些有效的见解你的数据。
如果您想参加机器学习课程,请查看DataCamp的带有scikit-learn课程的监督学习。
第1部分:预测每赛季MLB球队的胜利
在这个项目中,你将测试几个机器学习模型sklearn,根据球队的统计数据和那个赛季的其他变量来预测那个赛季大联盟棒球队赢得的比赛数量。如果我是一个赌博的人(我当然是一个赌博的人),我可以使用前几季的历史数据建立一个模型来预测即将到来的那个。考虑到数据的时间序列性质,您可以生成指标,例如过去五年中每年的平均获胜率以及其他此类因素,以制作高度准确的模型。但是,这超出了本教程的范围,您将每行视为独立的。我们的每一行数据都包含一个特定年份的团队。
Sean Lahman在他的网站上编译了这些数据,并在此处转换为sqlite数据库。
导入数据
您将通过使用sqlite3包查询sqlite数据库并使用转换为DataFrame来读入数据pandas。您的数据将被过滤,仅包括当前活跃的现代团队,以及团队仅玩150场或更多游戏的年份。
首先,下载文件“lahman2016.sqlite”(这里)。然后,加载Pandas并重命名以pd提高效率。您可能还记得,这pd是Pandas的常见别名。最后,加载sqlite3并连接到数据库,如下所示:
# import `pandas` and `sqlite3`
import pandas as pd
import sqlite3
# Connecting to SQLite Database
conn = sqlite3.connect('lahman2016.sqlite')
接下来,编写查询,执行查询并获取结果。
# Querying Database for all seasons where a team played 150 or more games and is still active today.
query = '''select * from Teams
inner join TeamsFranchises
on Teams.franchID == TeamsFranchises.franchID
where Teams.G >= 150 and TeamsFranchises.active == 'Y';
'''
# Creating dataframe from query.
Teams = conn.execute(query).fetchall()
提示:如果您想了解有关在Python中使用SQL的更多信息,请考虑使用DataCamp的Python数据库简介
pandas然后使用,然后将结果转换为DataFrame并使用以下head()方法打印前5行:
- script.py
每列包含与特定团队和年份相关的数据。下面列出了一些更重要的变量。可以在此处找到变量的完整列表。
-
yearID- 年 -
teamID- 团队 -
franchID- 特许经营(链接到TeamsFranchise表) -
G- 玩过的游戏 -
W- 胜利 -
LgWin- 联赛冠军(Y或N) -
WSWin- 世界系列赛冠军(Y或N) -
R- 运行得分 -
AB- 在蝙蝠 -
H- 击球击球 -
HR- 击球手的本垒打 -
BB- 击球员 -
SO- 击球手击球 -
SB- 被盗基地 -
CS- 偷了偷 -
HBP- 击球击球的击球手 -
SF- 牺牲苍蝇 -
RA- 对手跑得分 -
ER- 允许获得运行 -
ERA- 获得的平均运行 -
CG- 完整的游戏 -
SHO- 停工 -
SV- 保存 -
IPOuts- Outs Pitchhed(局比投球x 3) -
HA- 允许点击数 -
HRA- 允许Homeruns -
BBA- 允许走路 -
SOA- 投手罢工 -
E- 错误 -
DP- 双人游戏 -
FP- 守备百分比 -
name- 团队的全名
对于那些可能不熟悉棒球的人来说,这里有一个关于游戏如何运作的简要说明,其中包括一些变量。
棒球是在两个队伍之间进行的(你可以在数据中找到name或者teamID)每个队伍中有9个队员。这两支球队轮流击球和守备。击球队试图通过轮流击球守备队投手投球,然后围绕一系列四个基地逆时针运行:第一,第二,第三和本垒。守备队试图通过以下几种方式获得击球手或基地跑垒员来阻止跑步,并且R当玩家在基地前进并返回本垒时,跑步()得分。击球队中安全到达基地的球员将在队友轮流打击期间尝试前进到后续基地,例如击中(H),被击中的基地(SB)或其他方式。

当守备队记录三次出局时,球队在击球和守备之间切换。从客队开始,两支球队的一次击球构成一局。游戏由九局组成,在游戏结束时拥有更多游戏的团队获胜。棒球没有比赛时钟,虽然大多数比赛在第九局结束,如果一场比赛在九局后并列,它将进入额外局并将无限期地继续,直到一支球队在额外一局结束时领先。
有关棒球比赛的详细解释,请查看美国职业棒球大联盟的官方规则。
清理和准备数据
如上所示,DataFrame没有列标题。您可以通过将标题列表传递给columns属性来添加标题pandas。
- script.py
该len()函数将告诉您要处理的行数:2,287不是可以使用的大量数据点,因此希望没有太多的空值。
在评估数据质量之前,让我们首先消除不必要的列或从目标列派生的列(Wins)。这就是您正在使用的数据知识开始变得非常有价值的地方。如果您对所使用的数据一无所知,那么您对编码或统计数据的了解程度无关紧要。作为终身棒球迷肯定帮助我完成了这个项目。
- script.py
如上所述,空值会影响数据质量,进而可能导致机器学习算法出现问题。
这就是为什么你会删除下一个。有几种方法可以消除空值,但最好先显示每列的空值计数,以便决定如何最好地处理它们。
- script.py
在这里你会看到一个权衡:你需要干净的数据,但你也没有大量的数据。其中两列具有相对少量的空值。SO(Strike Outs)列中有110个空值,DP(Double Play)列中有22个空值。其中两列的数量相对较多。CS(Caught Stealing)列中有419个空值,而(HBPPitch by Pitch)列中有1777个空值。
如果消除列中具有少量空值的行,则会丢失超过百分之五的数据。由于您正在尝试预测胜利,因此得分和允许的运行与目标高度相关。您希望这些列中的数据非常准确。
Strike outs(SO)和double plays(DP)并不重要。
我认为你最好保留行并使用该fillna()方法用每个列的中值填充空值。偷窃(CS)和俯仰(HBP)击中也不是非常重要的变量。在这些列中有如此多的空值,最好一起消除列。
- script.py
探索和可视化数据
既然您已经清理了数据,那么您可以进行一些探索。通过一些简单的可视化,您可以更好地感受数据集。matplotlib是一个优秀的数据可视化库。
您导入matplotlib.pyplot并重命名plt为效率。如果你正在使用Jupyter笔记本,你需要使用%matplotlib inline魔法。
您将首先绘制目标列的直方图,以便查看胜利的分布。
# import the pyplot module from matplotlib
import matplotlib.pyplot as plt
# matplotlib plots inline
%matplotlib inline
# Plotting distribution of wins
plt.hist(df['W'])
plt.xlabel('Wins')
plt.title('Distribution of Wins')
plt.show()
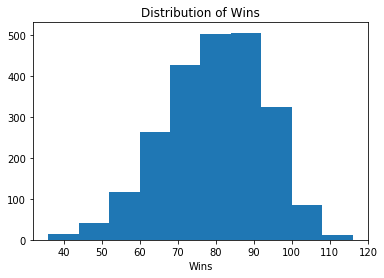
请注意,如果您不使用Jupyter笔记本,则必须使用它plt.show()来显示图表。
打印出每年的平均胜利(W)。您可以使用此mean()方法。
- script.py
在浏览数据时为目标列创建分档非常有用,但您需要确保在训练模型时不包括从目标列生成的任何功能。在训练集中包含从目标列生成的一列标签,就像为模型提供测试的答案一样。
要创建win标签,您将创建一个函数assign_win_bins,该函数将接受一个整数值(wins)并返回1-5的整数,具体取决于输入值。
接下来,您将win_bins使用apply()wins列上的方法并传入assign_win_bins()函数来创建新列。
- script.py
现在让我们在x轴上创建年份的散点图,并在y轴上获胜,并win_bins用颜色突出显示列。
# Plotting scatter graph of Year vs. Wins
plt.scatter(df['yearID'], df['W'], c=df['win_bins'])
plt.title('Wins Scatter Plot')
plt.xlabel('Year')
plt.ylabel('Wins')
plt.show()
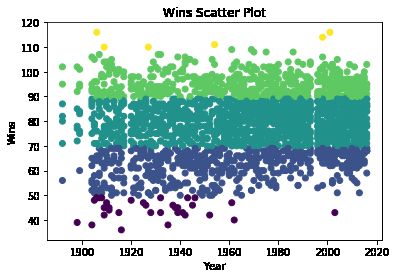
正如你在上面的散点图中看到的那样,从1900年之前的季节很少,那时的游戏就大不相同了。因此,从数据集中消除这些行是有意义的。
- script.py
处理连续数据和创建线性模型时,整数值(例如一年)可能会导致问题。1950的数字不太可能与模型推断的其他数据具有相同的关系。
您可以通过创建基于yearID值标记数据的新变量来避免这些问题。
任何跟随棒球比赛的人都知道,随着美国职业棒球大联盟(MLB)的进步,出现了不同的时代,每场比赛的跑动量显着增加或减少。20世纪初的死球时代是低得分时代的一个例子,21世纪之交的类固化时代是高得分时代的一个例子。
让我们在下面制作一个图表,表明每年有多少得分。
您将通过创建字典开始runs_per_year和games_per_year。使用该iterrows()方法遍历数据框。runs_per_year使用年份作为关键字填充字典,并将该年份的评分数作为值进行填充。games_per_year使用年份作为关键字填充字典,并将当年播放的游戏数量作为值。
- script.py
接下来,创建一个名为的字典mlb_runs_per_game。games_per_year用items()方法迭代字典。mlb_runs_per_game使用年份作为关键字填充字典,并将每个游戏的得分数(联盟范围)作为值进行填充。
- script.py
最后,mlb_runs_per_game通过将年份放在x轴上并在y轴上按游戏运行,从字典创建绘图。
# Create lists from mlb_runs_per_game dictionary
lists = sorted(mlb_runs_per_game.items())
x, y = zip(*lists)
# Create line plot of Year vs. MLB runs per Game
plt.plot(x, y)
plt.title('MLB Yearly Runs per Game')
plt.xlabel('Year')
plt.ylabel('MLB Runs per Game')
plt.show()
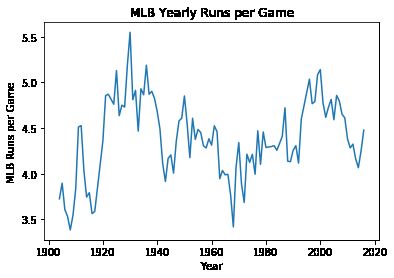
添加新功能
现在您已经对分数趋势有了更好的了解,您可以创建新的变量来指示每行数据所基于的特定时代yearID。您将按照与创建win_bins列时相同的过程进行操作。
但是,这次你将创建虚拟列; 每个时代的新专栏。您可以使用此get_dummies()方法。
- script.py
现在,您可以通过为每个十年创建虚拟列来将年份转换为数十年。然后,您可以删除不再需要的列。
- script.py
棒球比赛的底线是你得分的次数以及你允许的次数。通过创建与其他数据列的比率相对应的列,可以显着提高模型的准确性。每场比赛的运行和每场比赛允许的运行将是添加到我们的数据集的强大功能。
Pandas通过将R列除以G列来创建新列来创建新列时,这非常简单R_per_game。
- script.py
现在通过制作几个散点图来查看两个新变量中的每一个如何与目标获胜列相关联。在一个图的x轴上绘制每场比赛的运行,并在另一个图的x轴上运行。W在每个y轴上绘制列。
# Create scatter plots for runs per game vs. wins and runs allowed per game vs. wins
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.scatter(df['R_per_game'], df['W'], c='blue')
ax1.set_title('Runs per Game vs. Wins')
ax1.set_ylabel('Wins')
ax1.set_xlabel('Runs per Game')
ax2.scatter(df['RA_per_game'], df['W'], c='red')
ax2.set_title('Runs Allowed per Game vs. Wins')
ax2.set_xlabel('Runs Allowed per Game')
plt.show()
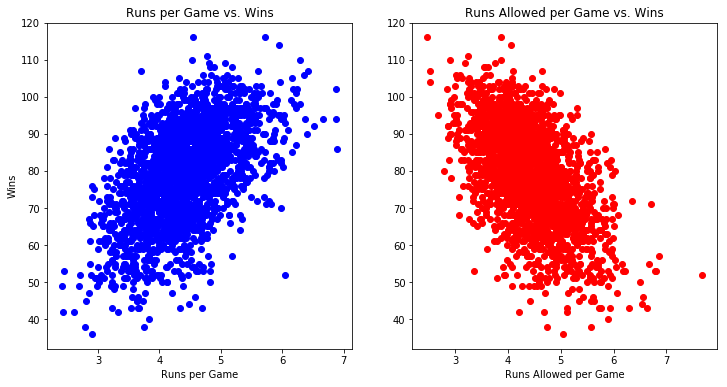
在进入任何机器学习模型之前,了解每个变量如何与目标变量相关联可能很有用。Pandas用这种corr()方法使这很容易。
- script.py
您可以添加到数据集的另一个功能是从提供的K-means聚类算法派生的标签sklearn。K-means是一种简单的聚类算法,可根据您指定的k个质心数对数据进行分区。基于哪个质心与数据点具有最低欧几里德距离,将每个数据点分配给聚类。
您可以在此处了解有关K-means聚类的更多信息。
首先,创建一个不包含目标变量的DataFrame:
- script.py
现在您可以初始化模型。将您的群集数量设置为6,将随机状态设置为1。使用该fit_transform()方法确定每个数据点的欧几里德距离,然后使用散点图可视化聚类。
# Create K-means model and determine euclidian distances for each data point
kmeans_model = KMeans(n_clusters=6, random_state=1)
distances = kmeans_model.fit_transform(data_attributes)
# Create scatter plot using labels from K-means model as color
labels = kmeans_model.labels_
plt.scatter(distances[:,0], distances[:,1], c=labels)
plt.title('Kmeans Clusters')
plt.show()
现在,将群集中的标签作为新列添加到数据集中。还要将字符串“labels”添加到attributes列表中,以供日后使用。
- script.py
在构建模型之前,需要将数据拆分为训练集和测试集。这样做是因为如果您决定在测试模型的相同数据上训练模型,您的模型可以轻松地过度拟合数据:模型将更多地记住数据而不是从中学习,这导致过于复杂的模型你的数据。这也解释了为什么当您尝试使用新数据进行预测时,过度拟合模型的性能会非常差。
但是不要担心,有许多方法可以交叉验证您的模型。
这一次,您只需随机抽取75%的数据用于train数据集,另外25%用于test数据集。创建一个列表,numeric_cols其中包含您将在模型中使用的所有列。接下来,使用列表中的列data从dfDataFrame 创建一个新的DataFrame numeric_cols。然后,还可以通过对DataFrame进行采样来创建数据集train和test数据集data。
- script.py
如果你从上面回忆起,平均获胜次数大约是79胜。平均而言,该模型仅获得2.687胜。
现在尝试一个Ridge回归模型。RidgeCV从中导入sklearn.linear_model并创建模型rrm。该RidgeCV模型允许您设置alpha参数,这是一个控制收缩量的复杂性参数(在此处阅读更多内容)。该模型将使用交叉验证来确定您提供的哪个alpha参数是理想的。
再次,适合您的模型,进行预测并确定平均绝对误差。
- script.py
这个模型的表现略好一些,平均下降了2.673。
体育分析和Scikit-Learn
本教程系列的第一部分到此结束,您已经了解了如何使用scikit-Learn来分析体育数据。您从SQLite数据库导入数据,清理它,在视觉上探索它的各个方面,并设计了几个新功能。您学习了如何创建K-means聚类模型,几个不同的线性回归模型,以及如何使用平均绝对误差度量来测试预测。
在第二部分中,您将看到如何使用分类模型来预测哪些球员进入MLB名人堂。
原文:https://www.datacamp.com/community/tutorials/scikit-learn-tutorial-baseball-1
作者: Daniel Poston