1 日志采集概述
1 日志采集流程
生产过程中会产生大量的系统日志,应用程序日志,安全日志等等日志,通过对日志的分析可以了解服务器的负载,健康状况,可以分析客户的分布情况,客户的行为,甚至于这些分析可以做出预测
一般采集流程
日志产出---采集 (logstash,flume,scribe) --- 存储---分析---存储(数据库、NoSQL)---可视化
2 半结构化数据
日志是半结构化数据,是有组织的,有格式的数据,可以分割成行和列,就可以当做表理解和处理了,当然也可以分析里面的数据
文本分析
日志是文本文件,需要依赖文件IO,字符串操作,正则表达式等技术,通经这些技术就能够把日志中需要的数据提取出来。
2 一般字符串格式处理日志
1 一般匹配模式处理web日志
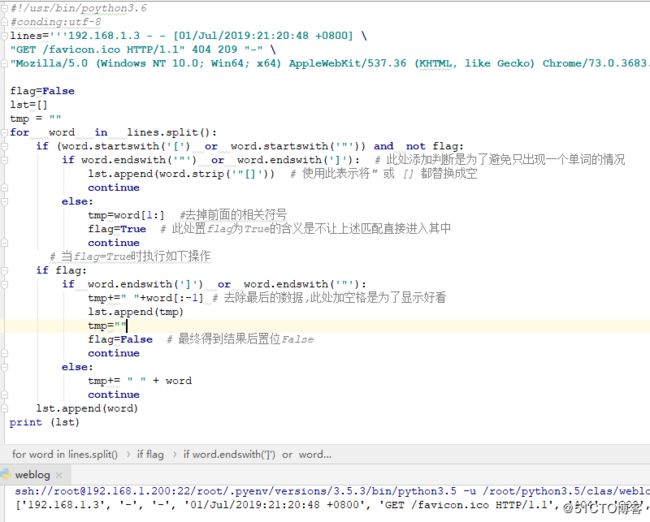
#!/usr/bin/poython3.6
#conding:utf-8
lines='''192.168.1.3 - - [01/Jul/2019:21:20:48 +0800] \
"GET /favicon.ico HTTP/1.1" 404 209 "-" \
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"'''
flag=False
lst=[]
tmp = ""
for word in lines.split():
if (word.startswith('[') or word.startswith('"')) and not flag:
if word.endswith('"') or word.endswith(']'): # 此处添加判断是为了避免只出现一个单词的情况
lst.append(word.strip('"[]')) # 使用此表示将" 或 [] 都替换成空
continue
else:
tmp=word[1:] #去掉前面的相关符号
flag=True # 此处置flag为True的含义是不让上述匹配直接进入其中
continue
# 当flag=True时执行如下操作
if flag:
if word.endswith(']') or word.endswith('"'):
tmp+=" "+word[:-1] # 去除最后的数据,此处加空格是为了显示好看
lst.append(tmp)
tmp=""
flag=False # 最终得到结果后置位False
continue
else:
tmp+= " " + word
continue
lst.append(word)
print (lst)结果如下
2 显示结果为字典
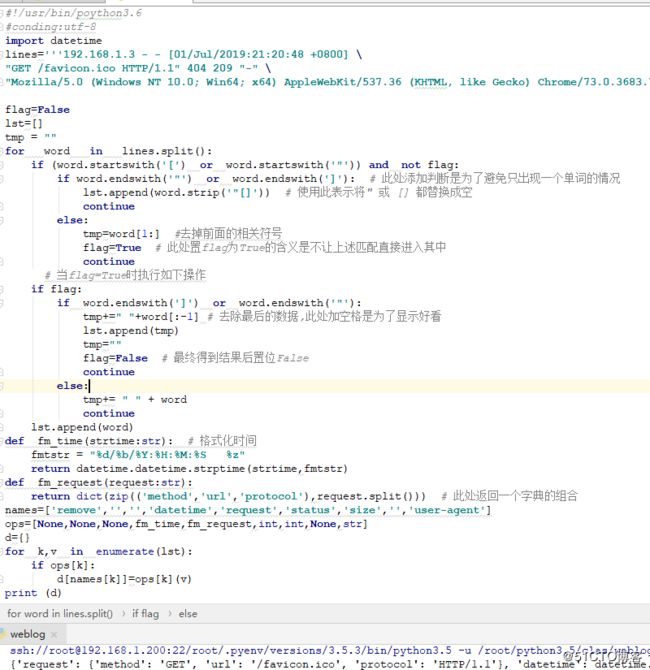
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
lines='''192.168.1.3 - - [01/Jul/2019:21:20:48 +0800] \
"GET /favicon.ico HTTP/1.1" 404 209 "-" \
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"'''
flag=False
lst=[]
tmp = ""
for word in lines.split():
if (word.startswith('[') or word.startswith('"')) and not flag:
if word.endswith('"') or word.endswith(']'): # 此处添加判断是为了避免只出现一个单词的情况
lst.append(word.strip('"[]')) # 使用此表示将" 或 [] 都替换成空
continue
else:
tmp=word[1:] #去掉前面的相关符号
flag=True # 此处置flag为True的含义是不让上述匹配直接进入其中
continue
# 当flag=True时执行如下操作
if flag:
if word.endswith(']') or word.endswith('"'):
tmp+=" "+word[:-1] # 去除最后的数据,此处加空格是为了显示好看
lst.append(tmp)
tmp=""
flag=False # 最终得到结果后置位False
continue
else:
tmp+= " " + word
continue
lst.append(word)
def fm_time(strtime:str): # 格式化时间
fmtstr = "%d/%b/%Y:%H:%M:%S %z"
return datetime.datetime.strptime(strtime,fmtstr)
def fm_request(request:str):
return dict(zip(('method','url','protocol'),request.split())) # 此处返回一个字典的组合
names=['remove','','','datetime','request','status','size','','user-agent']
ops=[None,None,None,fm_time,fm_request,int,int,None,str]
d={}
for k,v in enumerate(lst):
if ops[k]:
d[names[k]]=ops[k](v)
print (d)结果如下
3 正则表达式处理日志
1 基本显示
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
lines='''192.168.1.3 - - [01/Jul/2019:21:20:48 +0800] \
"GET /favicon.ico HTTP/1.1" 404 209 "-" \
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"'''
pattern='''(?P[\d\.]{7,}) - - \[(?P[^\[\]]+)\] "(?P[^"]+)" (?P\d+) (?P\d+) "-" "(?P[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
return regex.match(line).groupdict()
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
d={}
for k,v in extract(lines).items():
v1=ops.get(k,lambda x:x)(v)
d[k]=v1
print (d)
2 使用lamba 表达式结果如下
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
lines='''192.168.1.3 - - [01/Jul/2019:21:20:48 +0800] \
"GET /favicon.ico HTTP/1.1" 404 209 "-" \
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"'''
pattern='''(?P[\d\.]{7,}) - - \[(?P[^\[\]]+)\] "(?P[^"]+)" (?P\d+) (?P\d+) "-" "(?P[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
return regex.match(line).groupdict()
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
d={ k:ops.get(k,lambda x:x)(v) for k,v in extract(lines).items() }
print (d) 结果和上述相同
4 时间窗口分析
1 概念
很多数据,如日志,都是和时间相关的,都是按照时间顺序产生的,产生的数据分析的时候,按照时间求值,其中interval 表示每一次求值的时间间隔,width 表示时间窗口宽度,指的是每一次求值的时间窗口宽度
2 模式
1 当width > interval 时,其会有重叠部分
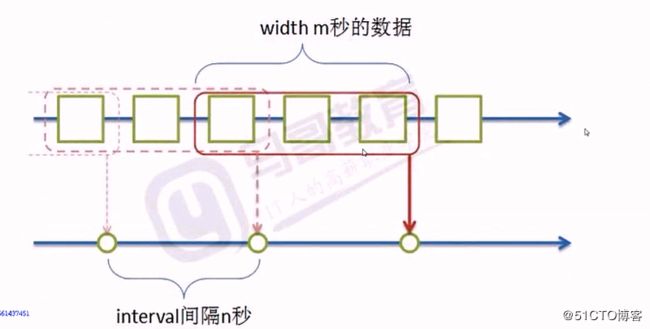
此种方式通常可用于统计日志的相关性趋势计算
2 当 width = interval 时,其刚好无重叠部分
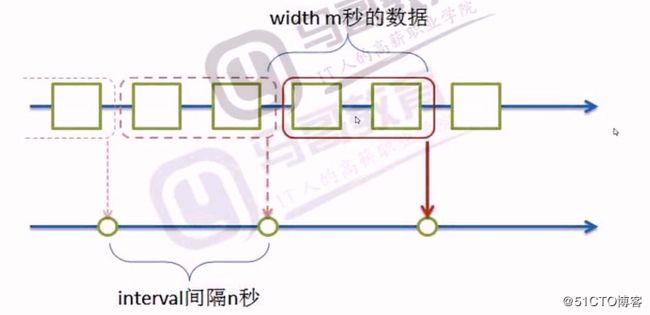
此种方式通常用于统计日志的相关状态码访问情况
3 当width < interval 时,其会有遗漏部分
数据分析基本程序结构
无限产生随机函数,产生时间相关的数据,返回时+随机数,每次去3个数据,求平均值
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import random
import time
# 产生数据的原函数
def Source():
while True:
yield { 'value':random.randint(1,100),'datetime':datetime.datetime.now()} # 此处返回时间
time.sleep(1)
s=Source()
# 定义产生数据的结果,并返回列表
itmes=[ next(s) for _ in range(3)]
# 处理函数
def handler(iterable:list):
vals=[x['value'] for x in iterable]
return sum(vals)/len(vals)
print (itmes)
print ("{:.2f}".format(handler(itmes)))3 窗口函数的实现
将上面获取数据的程序扩展为windows 函数,使用重叠方案,及wdith> interval
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
pattern='''(?P[\d\.]{7,}) - - \[(?P[^\[\]]+)\] "(?P[^"]+)" (?P\d+) (?P\d+) "-" "(?P[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
matcher=regex.match(line)
if matcher: #此处若匹配成立,则进行返回值处理
return { k:ops.get(k, lambda x: x)(v) for k, v in matcher.groupdict().items()}
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
def load(path:str):
with open(path) as f:
for line in f:
d=extract(line) # 此处返回字典
if d: # 若字典存在,则返回,若不存在,则直接返回循环进行下一次
yield d
else:
continue
def windows(src,headler,wdith,interval):
# 时间相关处理
starttime=datetime.datetime.strptime('1970-01-01 01:01:01 +0800','%Y-%m-%d %H:%M:%S %z') # 默认时间窗口的起始值
current=datetime.datetime.strptime('1970-01-01 01:01:02 +0800','%Y-%m-%d %H:%M:%S %z') # 默认时间窗口的结束值
delta=datetime.timedelta(wdith-interval) # 此处获取到的是时间的差值,此处是s,需要和上述的时间进行匹配
bugffer=[]
for line in src:
if line:
bugffer.append(line) # 此处获取到的是在窗口内的数据的值
print (line)
current=line['datetime'] # 此处获取starttime的初始值,用于选择窗口的起始位置
if (current-starttime).total_seconds()>=interval: # 表示窗口大,可以进行相关的操作了
ret=headler(bugffer)
print (ret)
starttime=current
# bugffer=[ i for i in bugffer if current-delta < i['datetime']]
bugffer1=[] # 通过此临时变量来存储那些重叠的部分
for i in bugffer:
if current - delta < i['datetime']: # 此处若成立,则表明其已经进入到了重叠区域,可进行保留并进行下一次的计算
bugffer1.append(i)
bugffer=bugffer1
def donothing_handler(iterable:list):
print(iterable)
return iterable
windows(load('/var/log/httpd/access_log-20190702'),donothing_handler,10,5) 5 分发
1 生产者消费者模型
对于一个监控系统,需要处理很多数据,包括日志,被监控对象就是数据的生产者producer,数据的处理就是数据的消费者consumer
传统的生产者消费者模型,生产者生产,消费者消费,但这种模型有些问题
开发的代码耦合太高,如果生产规模变大,不易扩展,且生产者和消费者的速度很难匹配。
用消费者的速度来决定生产者的速度
当生产者生产过剩而消费者来不急处理时,便产生了问题 ,及解决的方式便是解耦,通过队列来完成其之间的操作
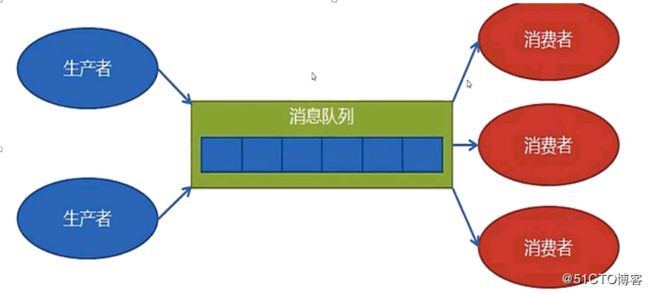
中间队列形成了程序,做成了消息队列MQ
2 消息队列的基本类型
1 概述
1 一对一的发布,及就是数据只能被一个消费者处理,及这个处理了这个数据,另一个则不能处理
2 一对多的发布,同一个数据可以被多个消费者进行处理,此处犹如广播类似
消息队列内部分类:
消息需要分组,有的需要多个副本,有的需要一个副本。消息队列中可能包含多个队列
2 应用
不同模块之间的通信,需要使用消息队列,其中间需要加上消息中间键
消息队列的作用:
1 程序之间实现程序的解耦
2 缓冲,防洪蓄水
3 queue 模块--队列
1 简介
queue 模块提供了一个先进先出的队列queue
相关说明:
queue.Queue(maxsize=0)
创建FIFO队列,返回Queue对象
maxsize 小于等于0,队列长度无限制
2 相关方法
Queue.get(block=True,timeout=None)
从队列中移除元素并返回这个元素
block为阻塞,timeout为超时
如果block为True,是阻塞,timeout为None就表示如果队列中其需要提取的对应数据就一直阻塞下去
如果block为True且timeout 有值,就阻塞到一定秒数抛出Empty异常
如果block 为False,则是非阻塞,timeout将会被忽略,要么成功返回一个元素,要么就抛出empty 异常
Queue.get_nowait()
等价于get(False),也就是说要么成功返回一个元素,要么抛出empty异常,但是queue的这种阻塞效果,需要多线程的时候进行演示
Queue.put(item,block=True,timeout=None)
把一个元素添加到队列中去
block=True,timeout=None,一直阻塞直到有空位放元素
block=True,timeout=5,阻塞5秒若没空位则抛出异常。
block=False,timeout失效,立即返回,能put就put,不能则抛出异常Queue.put_nowait(item)
等价于put(item,False),也就是能put进去就put进去,不能则抛出异常
3 实例
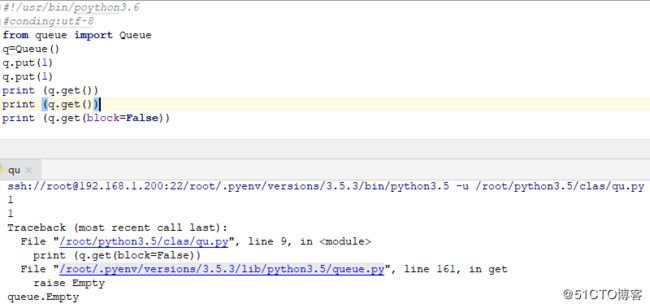
#!/usr/bin/poython3.6
#conding:utf-8
from queue import Queue
q=Queue()
q.put(1)
q.put(1)
print (q.get())
print (q.get())
print (q.get(block=False))结果如下
4 分发器的实现
1 概念
由生产者提供服务,消费者处理服务,当时间达到设置的时间后,其将自动交给handler进行处理,这就是分发器
分发器需要将数据发送给不同的消费者,此处需要和对应的消费者之间建立连接每个消费者的处理速度是不同的,消费者放需要进行处理的暂存处理,其需要防止到各自的暂存区域,每个消费者内部维护
分发器决定发送给谁,暂存器负责进行暂存处理
分发器中可以有队列,也可以没有
暂存区可使用队列和列表,其主要取决于其的不同业务
当对于一个大系统时,需要在分发器中进行消息的暂存,来获取一定的消息存储量 ,其相当于大坝到水池的概念。
生产者(数据源)生产数据,缓冲到消息队列中
2 数据处理流程
数据加载---数据提取---数据分析
处理大量数据的时候,对于一个数据源来说,需要多个消费者进行处理,但如何分配数据就是问题
3 相关流程
需要一个分发器,把数据分发给不同的消费者处理
每一个消费者拿到数据后,有自己的处理函数,所以要一种注册机制,
如何注册: 在调度器内部记录有哪些消费者,记录消费者自己的队列
每一个消费者的统计方式是不同的,因此其统计结果也是各有差异,及就是handler的不同,其结果是不同的
分发: 轮询,一对多副本发送,一个数据通过分发器,发送给n个消费者
线程
由于一条数据会被不同的注册过的handler处理,因此最好的方式就是多线程一般遇到阻塞问题就会使用多线程,将处理数据的问题应用到多线程上去
进程: 程序独立运行的一个空间
真正干活的是线程,内存中保留着进程的相关的状态,线程才是真正跑的指令,
多个线程之间的CPU之间是调度的,但CPU的调度是操作系统的原因,优先级越高,分的时间越多,CPU实现的是分时的概念,对线程来说,CPU是不能被独占的。
5 线程配置
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
from queue import Queue
import threading
pattern='''(?P[\d\.]{7,}) - - \[(?P[^\[\]]+)\] "(?P[^"]+)" (?P\d+) (?P\d+) "-" "(?P[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
matcher=regex.match(line)
if matcher: #此处若匹配成立,则进行返回值处理
return { k:ops.get(k, lambda x: x)(v) for k, v in matcher.groupdict().items()}
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
def load(path:str):
with open(path) as f:
for line in f:
d=extract(line) # 此处返回字典
if d: # 若字典存在,则返回,若不存在,则直接返回循环进行下一次
yield d
else:
continue
# 构建时间窗口
def windows(src:Queue,headler,wdith,interval):
# 时间相关处理
starttime=datetime.datetime.strptime('1970-01-01 01:01:01 +0800','%Y-%m-%d %H:%M:%S %z') # 默认时间窗口的起始值
current=datetime.datetime.strptime('1970-01-01 01:01:02 +0800','%Y-%m-%d %H:%M:%S %z') # 默认时间窗口的结束值
delta=datetime.timedelta(wdith-interval) # 此处获取到的是时间的差值,此处是s,需要和上述的时间进行匹配
bugffer=[]
# for line in src:
while True:
data=src.get(block=True,timeout=15)
if data:
bugffer.append(data) # 此处获取到的是在窗口内的数据的值
current=data['datetime'] # 此处获取starttime的初始值,用于选择窗口的起始位置
if (current-starttime).total_seconds()>=interval: # 表示窗口大,可以进行相关的操作了
ret=headler(bugffer)
print (ret)
starttime=current
# bugffer=[ i for i in bugffer if current-delta < i['datetime']]
bugffer1=[] # 通过此临时变量来存储那些重叠的部分
for i in bugffer:
if current - delta < i['datetime']: # 此处若成立,则表明其已经进入到了重叠区域,可进行保留并进行下一次的计算
bugffer1.append(i)
bugffer=bugffer1
def donothing_handler(iterable:list):
print(iterable)
return iterable
# 构建分发器
def dispather(src):
queues=[] # 队列的列表,用于保存其中的队列
threads=[] # 线程列表,用于保存线程
def reg(handler,width,interval): # 注册流程
q=Queue() # 分配队列
queues.append(q) #为了后期能够调用,需要将其保留到列表中
t=threading.Thread(target=windows,args=(q,handler,width,interval)) #此处是多线程,此处执行了一个函数
threads.append(t)
def run():
for t in threads:
t.start()
for x in src:
for q in queues:
q.put(x) # 所有的queues中推送q,此处便是一对多的情况,此处启动数据引擎
return reg,run
reg,run=dispather(load('/var/log/httpd/access_log-20190702'))
reg(donothing_handler,10,5)
run() #此处启动并运行数据引擎 6 状态码分析
1 状态码简介
状态码中包含了很多信息,如
304,服务其收到客户端提交的请求参数,发现资源未变化,要求浏览器使用静态资源的缓存
404,服务器找不到请求
304,占比大,说明静态缓存效果鸣谢,404占比大,说明出现了错误连接,或者常使嗅探网络资源
如果400,500占比突然增加,网站一定出问题了。
2 相关程序处理
#!/usr/bin/poython3.6
#conding:utf-8
import datetime
import re
from queue import Queue
import threading
from collections import defaultdict
pattern='''(?P[\d\.]{7,}) - - \[(?P[^\[\]]+)\] "(?P[^"]+)" (?P\d+) (?P\d+) "-" "(?P[^"]+)"'''
regex=re.compile(pattern)
def extract(line):
matcher=regex.match(line)
if matcher: #此处若匹配成立,则进行返回值处理
return { k:ops.get(k, lambda x: x)(v) for k, v in matcher.groupdict().items()}
ops={
'datetime': lambda strtime: datetime.datetime.strptime(strtime,'%d/%b/%Y:%H:%M:%S %z'),
'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
'size': int,
'status' :int,
}
def load(path:str):
with open(path) as f:
for line in f:
d=extract(line) # 此处返回字典
if d: # 若字典存在,则返回,若不存在,则直接返回循环进行下一次
yield d
else:
continue
# 构建时间窗口
def windows(src:Queue,headler,wdith,interval):
# 时间相关处理
starttime=datetime.datetime.strptime('1970-01-01 01:01:01 +0800','%Y-%m-%d %H:%M:%S %z') # 默认时间窗口的起始值
current=datetime.datetime.strptime('1970-01-01 01:01:02 +0800','%Y-%m-%d %H:%M:%S %z') # 默认时间窗口的结束值
delta=datetime.timedelta(wdith-interval) # 此处获取到的是时间的差值,此处是s,需要和上述的时间进行匹配
bugffer=[]
# for line in src:
while True:
data=src.get(block=True,timeout=15)
if data:
bugffer.append(data) # 此处获取到的是在窗口内的数据的值
current=data['datetime'] # 此处获取starttime的初始值,用于选择窗口的起始位置
if (current-starttime).total_seconds()>=interval: # 表示窗口大,可以进行相关的操作了
ret=headler(bugffer)
print (ret)
starttime=current
# bugffer=[ i for i in bugffer if current-delta < i['datetime']]
bugffer1=[] # 通过此临时变量来存储那些重叠的部分
for i in bugffer:
if current - delta < i['datetime']: # 此处若成立,则表明其已经进入到了重叠区域,可进行保留并进行下一次的计算
bugffer1.append(i)
bugffer=bugffer1
def donothing_handler(iterable:list):
print(iterable)
return iterable
def status_handler(iterable:list):
status=defaultdict(lambda :0)
for i in iterable:
key = i['status']
status[key]+=1
total=sum(status.values())
return {k:v/total*100 for k,v in status.items()}
# 构建分发器
def dispather(src):
queues=[] # 队列的列表,用于保存其中的队列
threads=[] # 线程列表,用于保存线程
def reg(handler,width,interval): # 注册流程
q=Queue() # 分配队列
queues.append(q) #为了后期能够调用,需要将其保留到列表中
t=threading.Thread(target=windows,args=(q,handler,width,interval)) #此处是多线程,此处执行了一个函数
threads.append(t)
def run():
for t in threads:
t.start()
for x in src:
for q in queues:
q.put(x) # 所有的queues中推送q,此处便是一对多的情况,此处启动数据引擎
return reg,run
reg,run=dispather(load('/var/log/httpd/access_log-20190702'))
# reg(donothing_handler,10,5)
reg(status_handler,5,5)
run() #此处启动并运行数据引擎 7 浏览器分析
1 简介
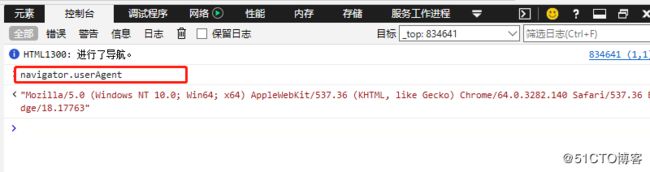
useragent 这里是指,软件按照一定的格式像远端服务器提供一个标识自己的字符串,在http协议中,使用user-agent字段传送这个字符串
通过参数navigator.userAgent 可在浏览器的控制台中获取userAgent
2 信息提取及模块安装
需要安装的模块
pyyaml,ua-parser,user-agents模块
安装pip install pyyaml ua-parser user-agents3 基础实例
#!/usr/bin/poython3.6
#conding:utf-8
from user_agents import parse
u='''Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'''
ua=parse(u)
print (ua.browser)
print (ua.browser.family,ua.browser.version_string)#获取浏览器类型和版本结果如下
![]()
4 具体代码如下
#!/usr/bin/poython3.6
#conding:utf-8
import re
import datetime
from queue import Queue
import threading
from pathlib import Path
from user_agents import parse
from collections import defaultdict
pattern = '''(?P[\d\.]{7,}) - - \[(?P[^\[\]]+)\] "(?P[^"]+)" (?P\d+) (?P\d+) "([^"]+)" "(?P[^"]+)"'''
regex = re.compile(pattern) # 此处编译一次就够了
def extract(line)->dict:
matcher=regex.match(line)
if matcher:
return {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
ops= {
'datetime' :lambda timestr:datetime.datetime.strptime(timestr,"%d/%b/%Y:%H:%M:%S %z"), # 此处得到的是datatime,
'status': int,
'size' : int,
'request':lambda request:dict(zip(('method','url','protocol'),request.split())),
'useragent': lambda useragent : parse(useragent)
}
def openfile(path:str):
with open(path) as f:
for line in f:
d = extract(line)
if d:
yield d
else:
# TODO 不合格的数据
continue
def load(*path): # 需要可迭代对象
for file in path:
p = Path(file)
if not p.exists(): # 判断是否存在文件或目录
continue # 此处不存在,直接返回下一个循环
if p.is_dir():
for x in p.iterdir():
if x.is_file(): # 此处若是文件,则进行相关的处理,如果是目录,则不进行处理
yield from openfile(str(x)) #多个处理完,因此不是使用return直接输出,需要通过列表实现
elif p.is_file():
yield from openfile(str(p))
############################################################## 窗口器
def windows(src:Queue,handler,wdith:int,interval:int):
#{'request': {'protocol': 'HTTP/1.1', 'url': '/favicon.ico', 'method': 'GET'}, 'remote': '192.168.1.3', 'useragent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36', 'status': 404, 'datetime': datetime.datetime(2019, 6, 20, 23, 4, 16, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'size': 209}
# 和时间求值相关
start =datetime.datetime.strptime('1970/01/01 01:01:01 +0800','%Y/%m/%d %H:%M:%S %z')
current=datetime.datetime.strptime('1970/01/01 01:01:02 +0800','%Y/%m/%d %H:%M:%S %z')
# 和缓冲区相关
buffer=[] # 数据的存储大小,存储一点,消耗一点
delta=datetime.timedelta(wdith-interval) #此处返回是一个int类型,但其需要的是时间类型,因此此处需要进行类型转换
# for x in src: # 真实的q中是没有迭代的
while True:
data=src.get() #当其没有数据时会阻塞,其是在另一个线程中,不会影响主线程的显示
if data:
buffer.append(data) # 此处插入的是一个字典,若对于多个情况,则可通过传入整个字典比较合适
current= data['datetime'] # 对观察数据的时间进行查看
if (current - start).total_seconds()>=interval: # 若其相减大于 interval,则满足条件,则可以开始进行计算了,查看时间走出的情况
ret= handler(buffer) # 此处进行相关的计算即可
print (ret) #返回值,返回结束时间和平均值
start = current # 其变化必须在处理完成后达成
# buffer的处理,当前时间减去delta,窗口是时间范围留下的数据形成的
buffer=[ i for i in buffer if current - delta < i['datetime'] ] # 当前时间减去delta就是buffer中需要留下来的部分
# 如果相减之后值小于当前进行的值,则表示其应该保留,否则应该删除
def donothing_handler(iterable:list):
print (iterable)
return (iterable)
#此处是生成器
def status_handler(iterable:list):
d={}
for item in iterable: # 获取到的元素是一个字典
key= item['status'] # 此处表示状态码
if key not in d.keys(): # 取出其中的值,真实的是需要多个状态码的
d[key]=0
d[key]+=1
total=sum(d.values())
return {k:v/total*100 for k,v in d.items()} # 做的是某一个时间点的小统计
# 浏览器分析
ua_dict=defaultdict(lambda :0) # 创建默认字典
def browser_handler(iterable:list):
for item in iterable:
ua = item['useragent']
key= (ua.browser.family,ua.browser.version_string) #浏览器的名称和版本号
ua_dict[key]+=1
return ua_dict
######################################################## 分发源
# windows(load('/var/log/httpd/access_log'),donothing_handler,10,5) #此处不用了
#创建分发器
def dispatcher(src):
# 队列的列表,用于保存队列
queues=[]
threads=[]
def reg(handler,width,interval): # 就差一个q
q=Queue() #分配一个邮箱
queues.append(q) # 为了后期能够调用,需要将其保留到列表中
# windows(q,handler,width,interval) # 注册一次,需要分配一个q
t = threading.Thread(target=windows,args=(q,handler,width,interval)) # 此处是多线程,此处是执行了一个函数
threads.append(t)
def run():
for t in threads: #此处需要运行
t.start()
for x in src:
for q in queues:
q.put(x) # 所有的queues中推送q,此处便是一对多的情况,此处启动数据引擎
return reg,run
reg,run=dispatcher(load('/var/log/httpd/access_log-20190702'))
# reg注册窗口,每个窗口有不同的参数handler,width,interval
# reg(donothing_handler,10,5)
# reg(status_handler,10,5)
reg(browser_handler,5,5) # 窗口调用
run() # 此处启动并运行数据引擎