
WHAT
我们看官方文档是如此介绍的:
Protocol buffers are a language-neutral, platform-neutral extensible mechanism for serializing structured data.
Protocol buffers 是一个跨语言,跨平台以及支持可扩展的序列化结构数据的格式。
简单来说,Protocol Buffers就是一种google定义的结构化数据格式,用于数据的序列化和反序列化。由于它直接对二进制源数据进行操作,所以它相对于xml来说,足够的小,快以及简单,而且又与语言、平台无关,所以兼容性也有不错的表现。目前很适合做数据存储或 网络通讯间的数据传输。
当前官方显示的已支持的开发语言多达10种,分别有:C++、Java、Python、Objective-C、C#、JavaNano、JavaScript、Ruby、Go、PHP,基本上主流的语言都已支持。当然也有非官方(比如Lua)的支持语言,具体也是增加一个解析lib,有特殊需求的可以参考官方文档自己编写。目前支持的语言如下(有source地址):
Language Source
C++ src
Java java
Python python
Objective-C objectivec
C# csharp
JavaNano javanano
JavaScript js
Ruby ruby
Go golang/protobuf
PHP php
性能
官方介绍的它性能足够强悍,具体有多好?我们看下性能测试对比。

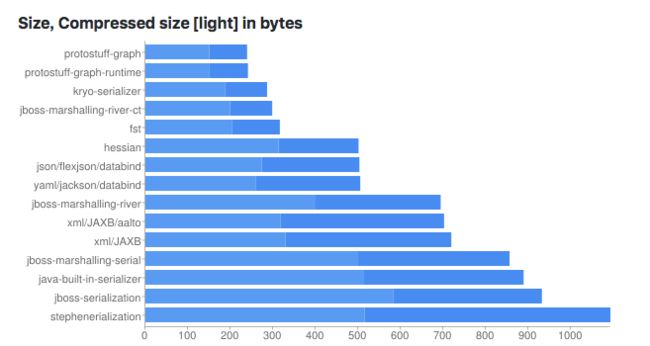
以上是基于Full Object Graph Serializers,包括创建对象,将对象序列化为内存中的字节序列,然后再反序列化的整个过程。图一是(序列化+反序列化)总共耗时,图二是压缩后的大小。我们可以看出protocolBuffer无论是序列化速度,还是数据大小,都有有明显优势。具体测试数据点此.
HOW
具体如何用,官方guide已经有很详细的介绍了,我们基于官方demo对package进行一次分解,了解其序列化过程以及soruce结构,以便对整个机制有一个大概的了解(以下语言基于java)。
demo
此demo假定你已经拥有当前平台的compiler(.proto生成目标语言代码的编译器),如若没有,请参照官网编译C++ runtime and protoc,如若window平台,也可以点击此处下载一个,无需自己编译。
step1:引入maven

step2:定义.proto文件
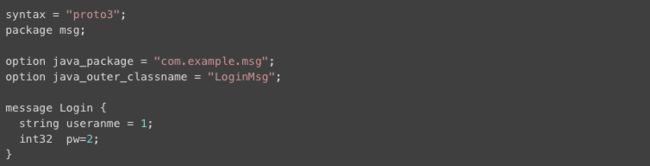
step3:compiler生产代码
最终生成的文件以及目录:

Reader&Writer
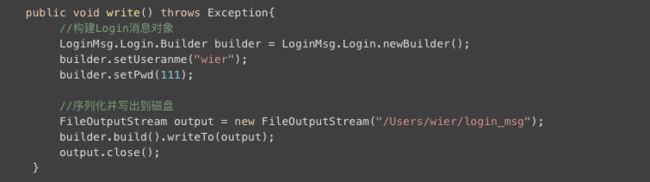
上述通过.proto定义生成的LoginMsg.java,已经整合了对LoginMsg的序列化和反序列化相关代码,我们对login这个消息的reader和writer时只需要通过对该class进行操作即可。比如要把loginMsg写入到流里面发送出去,只需要对loginMsg进行赋值然后writer,对象就被序列化为二进制数据写出,或者接收端读取LoginMsg时,调用其ParserbyReader,就可以基于二进制流反序列化为LoginMsg对象。
Write
Read

我们看到上述代码对消息的read和write都很简单,你只需要对上述的stream改造为为socket就可以基于tcp进行消息传输了。
Message类结构
我们基于LoginMsg来看下整个消息对象主要包含的信息。
一个message类主要包含以下信息:
Login 消息结构对象的主体,主要存储数据,同时继承GeneratedMessageV3,内部封装对象的序列化和反序列化,writeTo序列化,paser反序列化。
LoginOrBuilder 用来连接Login和Builder,提供类型信息以及对外提供field get方法。
Builder 消息对象构建器,对外封装field set方法。
Descriptor 消息对象元数据的描述信息,一般用不到,如果你有动态解析的需求可以通过此来处理
Parser 解析器,为消息反序列号提供服务
我们看下class的层次关系

MessageLite/Message接口是所有message的抽象接口,message可以基于Parser从字节流数据中构建对象,也可以通过Builder创建的对象序列化后写入字节流数据到IO管道,MessageLite和Message内部都定义了自己的Builder类,继承自MessageLiteOrBuilder以及MessageOrBuiler,并定义了MessageLite/Message和它们各自Builder类的共同接口。
调用时序
write
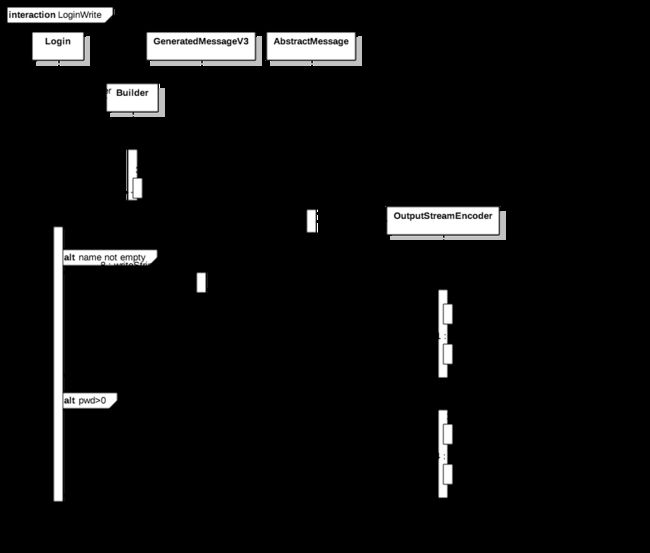
上面write的过程,我们可以看到,数据的封装主要通过build来处理,GeneratedMessageV3封装了一些基础字段读取的操作,最终的字段的写入主要依靠CodedOutputStream来进行,CodedOutputStream封装的所有(定义类型)字段转二进制的方式,比如int,String 等,你只需基于定义字段传入即可。OutputStreamEncoder是CodedOutputStream是一个子类。
read
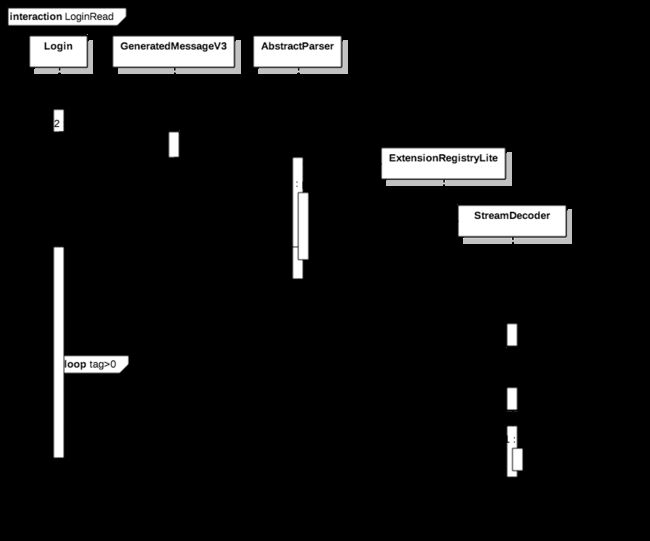
read的过程也是一个解包的过程,Parser主要来做解析管理,比如可以基于二进制数据或者基于IO来解析,或者一些扩展字段调用预注册的ExtensionRegister来自己定义解析。最终的字段读取调用CodedInputStream来读取,CodedInputStream和上面的CodedOutputStream一样,也是基于一些定义字段进行读取操作,将二进制数据转换为指定字段类型。消息的构造函数有基于CodedInputStream读取的,读取顺序基于tag来进行。具体每个field的tag是做什么的后续讲解。
message二进制结构
通过上面的read和write过程,我们可以看到每个消息字段读取的时候,都会先调用一次readTag或者writeTag,那么这个tag是做什么的,我们先看一个message的二进制组成结构。

一个二进制流,都是一队有序的byte数据组成,上述图中每个field都是有一个tag和value组成,tag等于就是这个value信息的描述或者定义,告知解析器当前fields是什么类型字段,以及读取的顺序,有了这个信息,解析器就知道一个field在流中的开始位置和结束位置,如此一个field解码成功,并且与字段顺序无关。
tag的构成:
(fieldNumber << 3) | wireType;
为何需要fieldNumber,一个是它可以告知解析器当前field在字节流中解析的顺序,另外也可以做到对协议的扩展,比如你在已经用到的协议消息中,需要增加一个字段或者更改一个字段,可以 fieldNumber+1,这样即便是同样一个消息,无论client是否更新协议(比如依然采用old message),依然不影响server端的解析。这样的机制,保证了即使该消息添加了新的字段,也不会影响旧的编/解码程序正常工作。
Descriptor
Descriptor 是消息对象的元数据描述信息,在compilerss生成消息对象class的时候,会为每个message定义一个Descriptor静态字段、同时还会定义一个FieldAccessorTable静态字段用于使用反射读取/设置某个字段的值。
当然了这些在一般的序列化和反序列化的时候用不到,因为消息的解析顺序以及类型已经在生成的时候基于配置文件生成好了,无需再来解析标签含义。
如果你有动态解析的需求,比如:新增或者更新一个 Message 时候,不需要更代码,重启进程,基于接收到 数据和配置文件,自动创建具体的 Protobuf Message 对象,再做的反序列化。此时Descriptor对你有很大的帮助意义。我们看下Descriptor下类层结构。

最后
extensions
在protocol2期间,还支持extensions字段定义,通过extend 用来解决消息复用的方式,目前在protocol3已经废弃了,采用Any来支持。
Unknown Fields
在protocol2期间,如果有无法解析的字段(如消息升级之后,client采用old message 传送),默认的解决方式如下:

如今protocol3已经对这一方案进行更新了,遇到没有定义的字段,直接skipField。

本节只针对protocol buffer 的是什么,以及如何用进行了介绍,并没有针对protocol为何会有占用空间小,解析速度快以及兼容性等优点进行梳理,如果你对这部分有兴趣,请关注下一篇相关文字,我会尝试梳理一下关于why问题。